







 文章介绍了ROC曲线和AUC的概念,AUC是ROC曲线下的面积。提供了两种计算AUC的方法,一种是通过样本对比较概率,另一种是利用概率排序和rank计算。还给出了Python代码示例来演示AUC的计算过程。
文章介绍了ROC曲线和AUC的概念,AUC是ROC曲线下的面积。提供了两种计算AUC的方法,一种是通过样本对比较概率,另一种是利用概率排序和rank计算。还给出了Python代码示例来演示AUC的计算过程。
ROC曲线
理解AUC需要首先理解ROC曲线,AUC是ROC曲线的面积。
详细参考这个博士AUC详解
AUC计算
方法一:
有M个正样本,N个负样本,一共有M*N个样本对,也就是说从M和N中分别取样,然后组成一个样本对,然后计算对正样本对预测概率大于对负样本预测的概率。
∑
I
(
P
p
o
s
,
P
n
e
c
)
M
×
N
\frac{\sum I(P_{pos},P_{nec})}{M \times N}
M×N∑I(Ppos,Pnec)
举个例子:
| D | Lable | pre |
|---|---|---|
| A | 0 | 0.1 |
| B | 0 | 0.4 |
| C | 1 | 0.35 |
| D | 1 | 0.8 |
这里假设有4个样本,2个正样本和两个负样本。我们所指的概率就是pre,需需要注意的是pre是软概率,也就是越接近1就是正,越接近0就是负,而不是分别针对正负分别预测的,这个很关键,开始我就理解错了。
这里我就是直观的希望对正样本的预测概率大于正样本的。
具体的,这里有四个样本对(C,A),(C,B),(D,A) 和(D,B),这里只有(C,B)是不满足的,应该为零,其他的是1.
那么auc:
1
+
1
+
1
+
0
2
∗
2
=
0.75
\frac{1+1+1+0}{2 * 2} = 0.75
2∗21+1+1+0=0.75
如果两个概率相等,那么
I
=
0.5
I=0.5
I=0.5。
方法二:
这个方法本质和方法一是一样的,只不过这里用数学规律进行了计算。
- 首先将模型预测出来的概率从高到底进行排序(其中正样本M,负样本N个)
- 每个样本设置了一个rank,概率最高的rank是n,其次是n-1。
- 这里的rank实际上就是每一个样本的概率大于多少的样本数量。
基于上面的条件,我们可以发现:
如果我们想要得到的就是每个正样本的概率大于负样本的概率的数量,然后求和。那么,如果概率最大的样本(rank为n)他一定大于剩余的n-1个样本,n-1个样本中有这个正样本M-1个,这M-1个其实并不是我们需要的,所以我们减去,那么就是我们把所有正样本的rank相加,再减去每次多余的正样本就可以了。
举个例子:
| 样本 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| pre | 0.8 | 0.7 | 0.6 | 0.5 | 0.4 | 0.3 |
| label | P | N | P | N | P | N |
| rank | 6 | 5 | 4 | 3 | 2 | 1 |
A的rank是6,那么代表他是大于等于6个节点的,很明显是包括自己以及其他的正样本,这些实际上应该被扣除,因为(A,正样本)是没有意义d的。也就是说:
A: 6 - M
C:4 - (M - 1)
E:2 - (M - 2)
减去的部分,实际上就是 M,M-1, … ,1, 0,这可以用公式
M
∗
M
(
M
+
1
)
/
2
M*M(M+1)/2
M∗M(M+1)/2,因此AUC表示为:
A
U
C
=
∑
i
∈
p
o
s
r
a
n
k
i
−
M
(
1
+
M
)
2
M
∗
N
AUC=\frac{\sum_{i \in posrank_i - \frac{M(1+M)}{2}}}{M * N}
AUC=M∗N∑i∈posranki−2M(1+M)
如果概率相同,则求rank的平均值。
import numpy as np
from sklearn.metrics import auc
from sklearn.metrics import roc_curve
def auc_calculate(labels, preds, n_bins=100):
postive_len = sum(labels)
negative_len = len(labels) - postive_len
total_case = postive_len * negative_len
pos_hist = [0] * n_bins # 直方图长度就是100,因为概率是0-1,乘以100,就是0-100
neg_hist = [0] * n_bins
bin_width = 1.0 / n_bins
for i in range(len(labels)):
nth_bin = int(preds[i] / bin_width)
if labels[i] == 1:
pos_hist[nth_bin] += 1
else:
neg_hist[nth_bin] += 1
accumulated = 0 # 用于累加比pos_hist[i]概率小的负样本的个数
satisfied = 0
for i in range(n_bins):
satisfied += (pos_hist[i] * accumulated + pos_hist[i] * neg_hist[i] * 0.5) # *0.5是为了计算两个样本概率相等的情况
accumulated += neg_hist[i]
return satisfied / float(total_case)
if __name__ == '__main__':
y = np.array([1, 0, 0, 0, 1, 0, 1, 0, ])
pred = np.array([0.9, 0.8, 0.3, 0.1, 0.4, 0.9, 0.66, 0.7])
fpr, tpr, thresholds = roc_curve(y, pred, pos_label=1)
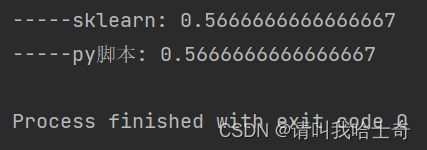
print("-----sklearn:", auc(fpr, tpr))
print("-----py脚本:", auc_calculate(y, pred))
结果:


















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











