







练习题(2)
1.要将employee 的表名更改为 employee_info,下面MySQL语句正确的是:
A.ALTER TABLE employee RENAME employee_info;
B.ALTER TABLE employee MODIFY employee_info;
C.ALTER TABLE employee ALTER employee_info;
D.ALTER TABLE employee CHANGE employee_info;
MySQL中ALTER TABLE命令可以修改数据表的表名或数据表的字段。但是接不同后缀意义不同,比如:
要修改表名或索引名时,可以用RENAME函数;当然RENAME也可以更改列名,但是后面要加TO,且它只会更改列的名字,并不更改定义。
要修改字段定义和名称,可以用MODIFY或CHANGE函数。但是MODIFY只改字段定义,不改名字;CHANGE是两个都可以修改。
要修改字段默认值,可以用ALTER 字段名 SET DEFULT 更改值。
所以根据题意,要修改表名,只能用RENAME函数,因此A正确;
BCD则分别是修改字段的方法。
2.下列子句中不可以与聚合函数一起使用的是()
A.GROUP BY
B.COMPUTE BY
C.HAVING
D.WHERE
D.WHERE子句的作用对象只是行,用来过滤数据作为条件使用。
3.下列关于视图的相关概念描述不正确的是()
A.视图可以解决检索数据时一个表中得不到一个实体所有信息的问题
B.视图是一种数据库对象,是从数据库的表或其他视图中导出的基表
C.若基表的数据发生变化,则变化也会自动反映到视图中
D.数据库存储的是视图的定义,不存放视图对应的数据
答案:B 视图是虚拟表,视图所引用的表称为视图的基表。
视图是虚拟表,是一个依赖于别的表上的寄生表,其本身不存储数据,对视图的操作最终都会转化为对基本表的操作。所以说视图不能是从其他视图导出的
4.Mysql中表student_table(id,name,birth,sex),score_table(stu_id,subject_name,score),查询多个学科的总分最高的学生记录明细以及总分,如下SQL正确的是()?
A.
select t2.*,c1 as `最高分` from (
select stu_id,sum(score) as c1 from score_table group by stu_id order by c1 desc limit 1
) t1
join student_table t2
on t1.stu_id = t2.id ;
B.
select t2.*,c1 as `最高分` from (
select stu_id,max(score) as c1 from score_table group by stu_id order by c1 desc limit 1
) t1
join student_table t2
on t1.stu_id = t2.id ;
C.
select t2.*,c1 as `最高分` from (
select stu_id,max(sum(score)) as c1 from score_table group by stu_id order by c1 desc limit 1
) t1
join student_table t2
on t1.stu_id = t2.id ;
D.
select t2.*,c1 as `最高分` from (
select stu_id,max(sum(score)) as c1 from score_table group by stu_id
) t1
join student_table t2
on t1.stu_id = t2.id ;
A正确,可以在子句中使用 order by c1 desc limit 1;
B是求的单科最高分;
CD执行均报错
5.关于解决事务的脏读的最简单的方法,下列选项正确的是()
A.修改时加排他锁,直到事务提交后释放,读取时加共享锁
B.读取数据时加共享锁,写数据时加排他锁,都是事务提交才释放锁
C.修改时加共享锁,直到事务提交后释放,读取时加排他锁
D.读取数据时加排他锁,写数据时加共享锁,都是事务提交才释放锁
答案:A
B选项,是对不可重复读或幻读的解决方法;CD选项中,各过程中添加了错误的锁。
6.关于维护参照完整性约束的策略,下列选项描述不正确的是()
A.对于任何违反了参照完整性约束的数据更新,系统一概拒绝执行
B.当删除被参照表的一个元组造成了与参照表的不一致,则删除参照表中的所有造成不一致的元组
C.当修改被参照表的一个元组造成了与参照表的不一致,则修改被参照表中的所有造成不一致的元组
D.当删除或修改被参照表的一个元组造成了不一致,则将参照表中的所有造成和不一致的元组的对应属性设置为空值
答案:C
参照完整性共分四种模式:不执行操作、级联、置空、设置默认值。
B选项对应级联操作,即主键列(被参照表)删除同时外键列(参照列)对应列也被删除;
C选项也对应级联操作,但应为修改外键列(参照表)中的数据;
D选项对应置空,即主键列数据删除或者修改时外键列对应数据被置为空值;
设置默认值模式为主键列的修改和删除使对应外键列数据被置为设定的默认值
7.有三张表,分别是departments部门表(注:dept_no是主键):
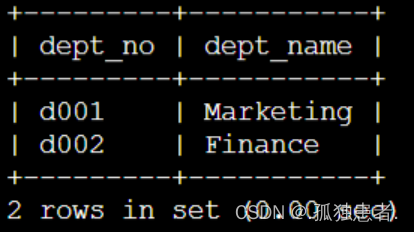
dept_emp部门-员工表:
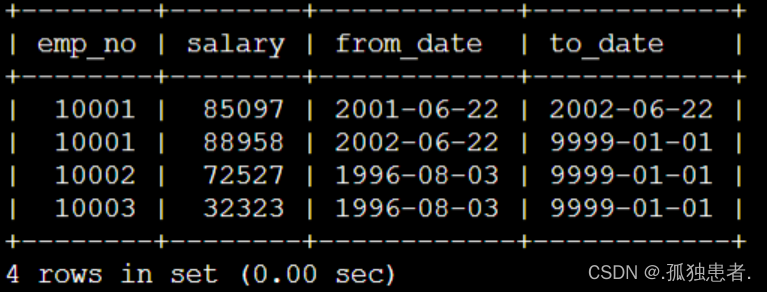
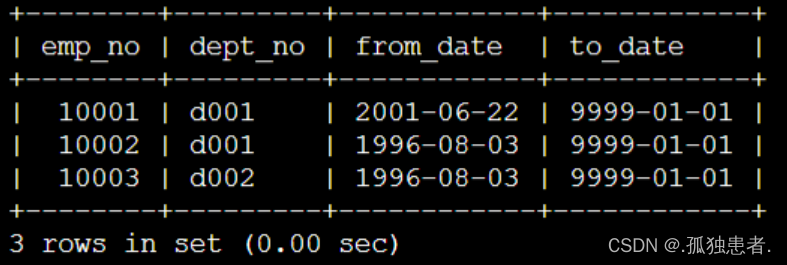 以及salaries工资表:
以及salaries工资表:
 现在统计各个部门的工资条数,按照dept_no、dept_name、sum(工资条数)输出,并按dept_no升序排列会得到如下结果:
现在统计各个部门的工资条数,按照dept_no、dept_name、sum(工资条数)输出,并按dept_no升序排列会得到如下结果:
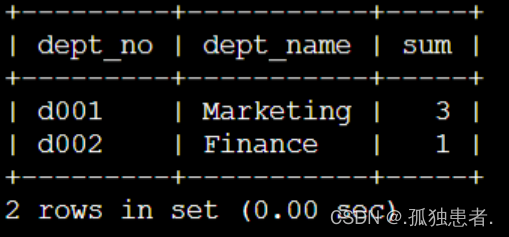
所以下列MySQL语句正确的是:
A.SELECT d.dept_no,d.dept_name,COUNT(salary) sum FROM departments d,dept_emp e,salaries s WHERE d.dept_no=e.dept_no AND e.emp_no=s.emp_no GROUP BY d.dept_no;
B.SELECT d.dept_no, d.dept_name, COUNT(s.salary) AS sum FROM salaries s JOIN dept_emp e ON s.emp_no = e.emp_no JOIN departments d ON d.dept_no = e.dept_no GROUP BY d.dept_no,d.dept_name ORDER BY d.dept_no;
C.SELECT d.dept_no, d.dept_name, SUM(s.salary) AS sum FROM salaries s JOIN dept_emp e ON s.emp_no = e.emp_no JOIN departments d ON d.dept_no = e.dept_no GROUP BY d.dept_no ORDER BY d.dept_no;
D.SELECT d.dept_no, d.dept_name, COUNT(s.salary) AS sum FROM salaries s JOIN dept_emp e ON s.emp_no = e.emp_no JOIN departments d ON d.dept_no = e.dept_no GROUP BY d.dept_no;
本题考察知识点:MySQL中多表连接、分组统计的方法
解题思路:
由于要统计各个部门的工资条数,
首先要把三张表连接起来,而连接三张表的点就是salaries的emp_no对应dept_emp表格的emp_no,这样就拿到了每个员工所在的部门id和对应的工资;
接下来用department的dept_no连接dept_emp表的dept_no,就能拿到员工对应所在的部门名称;
然后对各个部门分组并统计salary条数,就会用到GROUP BY dept_no方法(这里因为dept_no是主键,所以可以用它进行分组)和COUNT(salary);
最后是利用ORDER BY 进行升序排序即可。
因此B是正确的;
A和D选项没有进行最后的排序;
C错在用错统计函数,统计数目应该用COUNT()而不是SUM()求和。
Mysql中表student_table(id,name,birth,sex),插入如下记录:
(‘1003’ , ‘’ , ‘2000-01-01’ , ‘男’);
(‘1004’ , ‘张三’ , ‘2000-08-06’ , ‘男’);
(‘1005’ , NULL , ‘2001-12-01’ , ‘女’);
(‘1006’ , ‘张三’ , ‘2000-08-06’ , ‘女’);
(‘1007’ , ‘王五’ , ‘2001-12-01’ , ‘男’);
(‘1008’ , ‘李四’ , NULL, ‘女’);
(‘1009’ , ‘李四’ , NULL, ‘男’);
(‘1010’ , ‘李四’ , ‘2001-12-01’, ‘女’);
执行
select t1.,t2.
from (
select * from student_table where sex = ‘男’ ) t1
inner join
(select * from student_table where sex = ‘女’)t2
on t1.birth = t2.birth and t1.name = t2.name ;
的结果行数是()?
A.4 B.3 C.2 D.1
题目中【inner join … on t1.birth = t2.birth and t1.name = t2.name ; 】inner join意思是左右表中的birth、name都不为NULL时才会匹配上,结果中不含有一个字段为NULL或两个字段都为NULL的记录,结果只有‘张三’一条记录。所以选D.
 9.
9.
Mysql(版本8.0.25)中表student_table(id,name,birth,sex),插入如下记录:
(‘1004’ , ‘张三’ , ‘2000-08-06’ , ‘男’);
(‘1005’ , NULL , ‘2001-12-01’ , ‘女’);
(‘1006’ , ‘张三’ , ‘2000-08-06’ , ‘女’);
(‘1007’ , ‘王五’ , ‘2001-12-01’ , ‘男’);
(‘1008’ , ‘李四’ , NULL, ‘女’);
(‘1009’ , ‘李四’ , NULL, ‘男’);
(‘1010’ , ‘李四’ , ‘2001-12-01’, ‘女’);
执行
select t1.,t2.
from (
select * from student_table where sex = ‘男’ ) t1
full join
(select * from student_table where sex = ‘女’) t2
on t1.birth = t2.birth and t1.name = t2.name ;
的结果行数是()?
A.4 B.3 C.2 D.执行错误
oracle里面有full join,但是在mysql中没有full join。我们可以使用union来达到目的
答案:D
10.使用SQL语句建个存储过程proc_stu,然后以student表中的学号Stu_ID为输入参数@s_no,返回学生个人的指定信息。下面创建存储过程语句正确的是:( )
A.
CREATE PROCEDURE [stu].[proc_student]
@s_no AS int
AS
BEGIN
select * from stu.student where Stu_ID=@s_no
END
B.
CREATE PROCEDURE [stu].[proc_student]
@s_no int
AS
BEGIN
select * from stu.student where Stu_ID=@s_no
END
C.
CREATE PROCEDURE [stu].[proc_student]
@s_no int
AS
BEGIN
select * from stu.student where s_no=@s_no
END
D.
CREATE PROCEDURE [stu].[proc_student]
@s_no AS int
AS
BEGIN
select * from stu.student where Stu_ID=@Stu_ID
END
注意MySQL的存储过程和sql server写法不一样。
由题目知道student表中的数据列名为Stu_ID,因此排除C;
变量名定义为s_no,因此排除D;
A和B的差异在于定义s_no时是否有AS,在MySQL中AS是可省略的,因此AB均正确















 2880
2880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









