







Contents
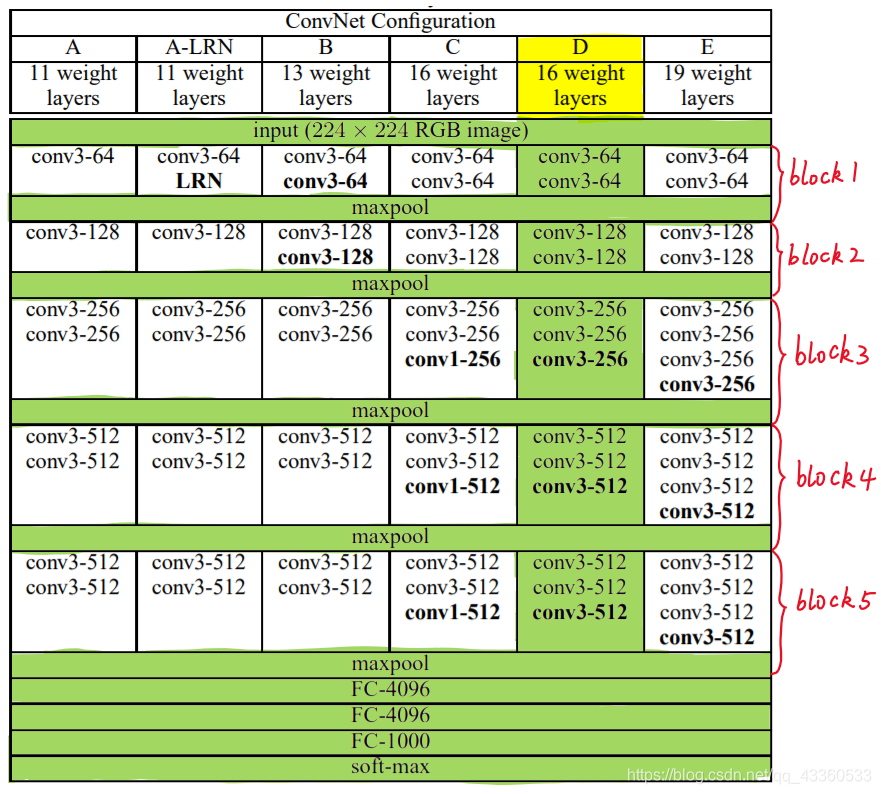
1 VGG基础块
VGG是由几个重复元素的网络块(VGG块)组合起来的。
VGG块的组成规律是:连续使用数个相同的填充为1、窗口形状为3×3的卷积层后接上一个步幅为2、窗口形状为2×2的最大池化层。
卷积层保持输入的高和宽不变,而池化层则对其减半。
这里使用vgg_block函数来实现这个基础的VGG块,它可以指定卷积层的数量和输入输出通道数。
import time
import torch
from torch import nn, optim
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0 :
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size = 3, padding = 1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size = 3, padding = 1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size = 2, stride = 2))
return nn.Sequential(*blk)
conv_arch = ((1,1,64),(1,64,128),(2,128,256),(2,256,512),(2,512,512))
fc_feature = 512 * 7*7
fc_hidden_units = 4096
2 VGG网络模型

def vgg(conv_arch, fc_feature, fc_hidden_units = 4096):
net = nn.Sequential()
# 卷积层部分
for i , (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module('vgg_block_' + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module('fc', nn.Sequential(d2l.FlattenLayer(),
nn.Linear(fc_feature, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)
))
return net
# 下面构造一个高和宽均为224的单通道数据样本来观察每一层的输出形状
net = vgg(conv_arch, fc_feature, fc_hidden_units)
X = torch.rand(1, 1, 224, 224)
# named_children获取一级子模块及其名字(named_modules会返回所有子模块,包括子模块的子模块)
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
vgg_block_1 output shape: torch.Size([1, 64, 112, 112])
vgg_block_2 output shape: torch.Size([1, 128, 56, 56])
vgg_block_3 output shape: torch.Size([1, 256, 28, 28])
vgg_block_4 output shape: torch.Size([1, 512, 14, 14])
vgg_block_5 output shape: torch.Size([1, 512, 7, 7])
fc output shape: torch.Size([1, 10])
Hints:
VGG这种高和宽减半以及通道翻倍的设计使得多数卷积层都有相同的模型参数尺寸和计算复杂度。
3 获取数据和训练模型
ratio = 8
small_conv_vgg = [(1, 1, 64//ratio), (1, 64//ratio, 128//ratio), (2, 128//ratio, 256//ratio),
(2, 256//ratio, 512//ratio), (2, 512//ratio, 512//ratio)]
net = vgg(small_conv_vgg, fc_feature//ratio,fc_hidden_units//ratio)
print(net)
Sequential(
(vgg_block_1): Sequential(
(0): Conv2d(1, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_2): Sequential(
(0): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_3): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_4): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_5): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): FlattenLayer()
(1): Linear(in_features=3136, out_features=512, bias=True)
(2): ReLU()
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=512, out_features=512, bias=True)
(5): ReLU()
(6): Dropout(p=0.5, inplace=False)
(7): Linear(in_features=512, out_features=10, bias=True)
)
)
batch_size = 64
# 如出现“out of memory”的报错信息,可减小batch_size或resize
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
training on cuda
epoch 1, loss 2.3032, train acc 0.101, test acc 0.100, time 338.7 sec
epoch 2, loss 1.1515, train acc 0.101, test acc 0.100, time 349.0 sec
epoch 3, loss 0.7676, train acc 0.099, test acc 0.100, time 363.9 sec
epoch 4, loss 0.5757, train acc 0.098, test acc 0.100, time 364.4 sec
epoch 5, loss 0.4606, train acc 0.098, test acc 0.100, time 354.5 sec
欢迎关注【OAOA】
















 5573
5573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









