









机器学习基础篇(七)——朴素贝叶斯
一、前言
机器学习中常见的一个问题就是如何把未知的数据分到先前已经知晓的类别中去。比如我们想对一个未知的水果进行分类,而我们已经知道分类特征如下:
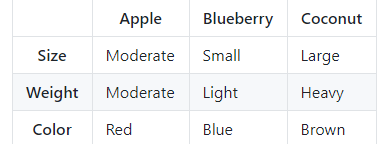
如图所示,我们有三个现有的水果类别:苹果,蓝莓和椰子。这些水果中的每一种都有三个我们关心的特征:大小,重量和颜色。通过观察未知水果我们发现,这个水果大小适中(moderate),但是很重(heavy),并且还是红色(red)的。我们可以将这些特征与我们已经知道的特征进行比较,由此判断它是什么类型的水果。若未知水果像椰子一样重,但另外两个特征与苹果相同,我们将猜测它是苹果。
这个例子比较简单,但是它体现了在分类问题中的一种思想:在分类问题中,我们会将未知标签的数据集特征与我们已知标签的特征进行比较。朴素贝叶斯,就是这样一种比较的方法。
二、简介
朴素贝叶斯是一种分类技术,它会使用我们已知的数据概率来对未知的数据点进行分类。 这种概率和现有的数据分布以及数据的标签有关。
正如上面例子所言,我们将最类似于未知数据的分类,作为未知数据的标签。
Naive Bayes(朴素贝叶斯)技术的理论依据是贝叶斯定理(Bayes’ Theorem),在下面我们将详细阐述。
三、贝叶斯定理
- 首先我们引入两个个概念:概率、条件概率
(1)概率:事件A发生的可能性就被称为A发生的概率,用P(A)来表示
(2)条件概率:当事件B已经发生的时候,事件A发生的可能性,称为在B条件下A发生的条件概率,用P(A|B)表示 - 那么对于事件A、B同时发生的概率,就可以用P(AB)来表示
- 因此我们可以得出以下公式:
P(AB)=P(A|B)*P(B)
P(AB)=P(B|A)*P(A) - 于是有:
P(A|B)*P(B)=P(B|A)*P(A)=P(AB)
P(A|B)=P(B|A)*P(A)/P(B)
举个栗子:
一起汽车撞人逃跑事件,已知只有两种颜色的车,比例为蓝色20% 绿色80%,目击者指证是蓝车。但根据现场分析,当时那种条件下,目击者看车的颜色正确的可能性是60%。那么,肇事的车是蓝车的概率到底是多少?
- 首先,事件B={目击者看到车为蓝色},事件A={车本来就是蓝色}
P(B)=0.6(看对了)*0.2(车本来是蓝色)+0.4(看错了)*0.8(车是绿色)=0.44
P(AB)=0.6(看对了)*0.2(本来是蓝色)=0.12
P(A|B)=P(AB)/(B)=0.12/0.44
四、朴素贝叶斯理论
朴素贝叶斯的基本方法:在统计数据的基础上,依据条件概率公式,计算当前特征的样本属于某个分类的概率,选最大的概率分类
具体过程如下:
- 当前有一个样本X,X有N个特征,分别为: X={a1,a2,a3…an}
- 类别集合为:Y={y1,y2,y3…ym}共有M个类别
- 分别计算X属于每个类别的条件概率:P(y1|X),P(y2|X),P(y3|X)…P(ym|X)
- 然后选取上述条件概率中的最大值,其所对应的类别就是X样本所属的分类:max{P(y1|X),P(y2|X),P(y3|X)…P(ym|X)}
- 那么问题出现:对于任意一个分类K,条件概率P(yk|X)的值应该如何计算?
由公式可知:
P(yk|X)==P(X|yk)*P(yk)/P(X) - X有N个特征,而且每个特征相互独立,所以:
P(X|yk)*P(yk)=P(a1|yk)*P(a2|yk)…P(an|yk)*P(yk)
P(X|yk)*P(yk)=P(yk)∏P(ai|yk)(i:1~N)
于是:P(yk|X)==P(yk)∏P(ai|yk)/P(X)(i:1~N)
注:N个特征相互独立,代表着这N个特征之间相互没有影响。于是在计算概率的时候可以连乘,正如上面公式所展示的。
五、算法
下面讲解一些朴素贝叶斯的基本算法,我们可以根据算法的特征类型将其分成两类。
- 连续:这意味着最终的标签为实值(可以存在小数)
- 离散:这以为着最终的结果为分类的类别值(只能为整数)
1 .高斯模型(连续数据)
高斯模型假设特惠总能的分布式属于正态分布的,在处理连续的特征变量时,我们应该选择使用搞事模型,正态分布的概率你读函数如图:

可以看出,正态分布像一个钟形,均值所对应的概率密度函数最高。我们假定某个特征I服从均值为μ,方差为σ²的正态分布,记为N(μ,σ²)。
刚刚的公式:
P(yk|X)==P(yk)∏P(ai|yk)/P(X)(i:1~N)
我们可以假定样本X的特征I符合正态分布,此时上式中的的计算会变得十分容易。
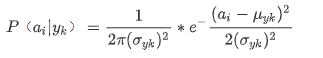
如上所示,其中(σ[yk])² 代表类别为 yk的样本中,第I维特征的方差。μ代表类别为yk的样本中,第I维特征的均值。
代码实现
# 朴素贝叶斯—高斯模型
import numpy as np
from sklearn.naive_bayes import GaussianNB#导入高斯模型
# 样本包含三个特征,分别是red,green,blue的百分比,每个特征值都在0-1之间
X=np.array([[.5,0,.5],[1,1,0],[0,0,0]])#创建训练集
y=np.array(['Purple','Yellow','Black'])
# 运用高斯模型训练数据
clf=GaussianNB()
clf.fit(X,y)
# 运用模型 进行测试,比如试一下,red 0.5,green 0.5,blue 0.5
print(clf.predict([[.5,.5,.5]]))
运行结果
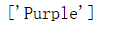
注: 可以使用其他的数据测试
2.多项式模型(离散数据)
当我们的特征都是分类型特征的时候,可以使用多项式模型,我们可以用它来计算特征中分类的出现频率。特别的是,当特征只有两种的时候,我们将会使用多项式模型中的伯努利模型。
在多项式模型中,对于样本X的第I个特征,P(ai|yk)的计算十分容易
P(ai|yk)=N(yk,ai)/N(yk)
如上所示,其中N(yk,ai)代表类别为yk的样本中,第I维特征取值是ai的个数。N(yk)代表类别为yk的样本个数。
代码实现
# 朴素贝叶斯——多项式模型
#我们使用文章最开始的水果的数据集作为示例
#水果数据集的样本X具有三个特征[Size, Weight, Color]
#每个特征共有三种分类
#由于python不能直接识别文字
#所以将这个三个特征的不同分类重新编码如下
# Size: 0 = Small, 1 = Moderate, 2 = Large
# Weight: 0 = Light, 1 = Moderate, 2 = Heavy
# Color: 0 = Red, 1 = Blue, 2 = Brown
import numpy as np
from sklearn.naive_bayes import MultinomialNB#导入到多项式模型
# 用编好的数据创建训练集
X=np.array([[1,1,0],[0,0,1],[2,2,2]])
# 给训练集的数据创建标签
y=np.array(['Apple','Blueberry','Coconut'])
# 运用多项式模型训练数据
clf=MultinomialNB()
# 训练水果数据集
clf.fit(X,y)
# 预测数据集,试一下size=1,weight=2,color=0
print(clf.predict([[1,2,0]]))
运行结果
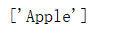
3.伯努利模型(离散数据)
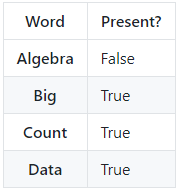
上文中我们提到,当特征只有两种的时候,我们可以使用伯努利模型。与多项式模型不同,我们在这里只计算一个特征是否发生。比如,本页面是否存在【多项式】这三个字,答案只有两种,存在or不存在。伯努利模型的条件概率计算方法与多项式模型一致。
下图展示了我们可能与伯努利模型一起使用的数据类别:
代码实现
我们将根据某些特征,来预测某些东西是否是鸭子。
# 朴素贝叶斯——伯努利模型
import numpy as np
from sklearn.naive_bayes import BernoulliNB#导入伯努利模型
# 数据集X的特征有三个,分别是:
# walks like a duck
# talks like a duck
# is small
# 这三个特征分别有两种分布,是或否
# walks like a duck:0=False,1=True
# talks like a duck:0=False,1=True
# is small:0=False,1=True
# 创建数据集
X=np.array([[1,1,0],[0,0,1],[1,0,0]])
# 给训练集创建标签:是鸭子or 不是鸭子
y=np.array(['duck','not a duck','not a duck'])
# 使用伯努利模型训练数据
clf=BernoulliNB()
clf.fit(X,y)
# 预测数据集,我们试一下三个特征都为True
print(clf.predict([[True,True,True]]))
运行结果
六、小结
在本节内容中,我们学习了朴素贝叶斯的相关知识。朴素贝叶斯可以让我们依据现有的数据特征和标签,对于预测数据进行分类。正如前面代码所展现的那样,我们不需要很多数据就可以训练朴素贝叶斯模型。朴素贝叶斯模型有另外一个优点,就是运行速度特别快,可以进行实时预测。我们用朴素贝叶斯做了很多假设,所以要对结果持保留态度,不能完全信任。当我们没有太对数据,又需要迅速产生结果的时候,可以选择朴素贝叶斯模型。
自学自用,希望可以和大家积极沟通交流,小伙伴们加油鸭,如有错误还请指正,不喜勿喷,喜欢的小伙伴帮忙点个赞支持,蟹蟹呀
















 2274
2274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











