







卷积神经网络基础知识
本文主要介绍CNN,convolutional neural network的基础知识,目录如下:
- 卷积神经网络历史
- CNN组成和介绍
全连接层;卷积层;池化层; - FP和BP算法
激活函数;FP算法;BP算法;优化器;
本文参考的资料如下:
- 1.1 卷积神经网络基础
https://www.bilibili.com/video/BV1b7411T7DA - LaTeX数学符号大全
https://blog.csdn.net/LCCFlccf/article/details/89643585 - 卷积动画详解
https://blog.csdn.net/haohulala/article/details/107332661 - 1.2 卷积神经网络基础补充
https://www.bilibili.com/video/BV1M7411M7D2
卷积神经网络历史
1998年,yanglecun(美国人)提出来的CNN模型如下:
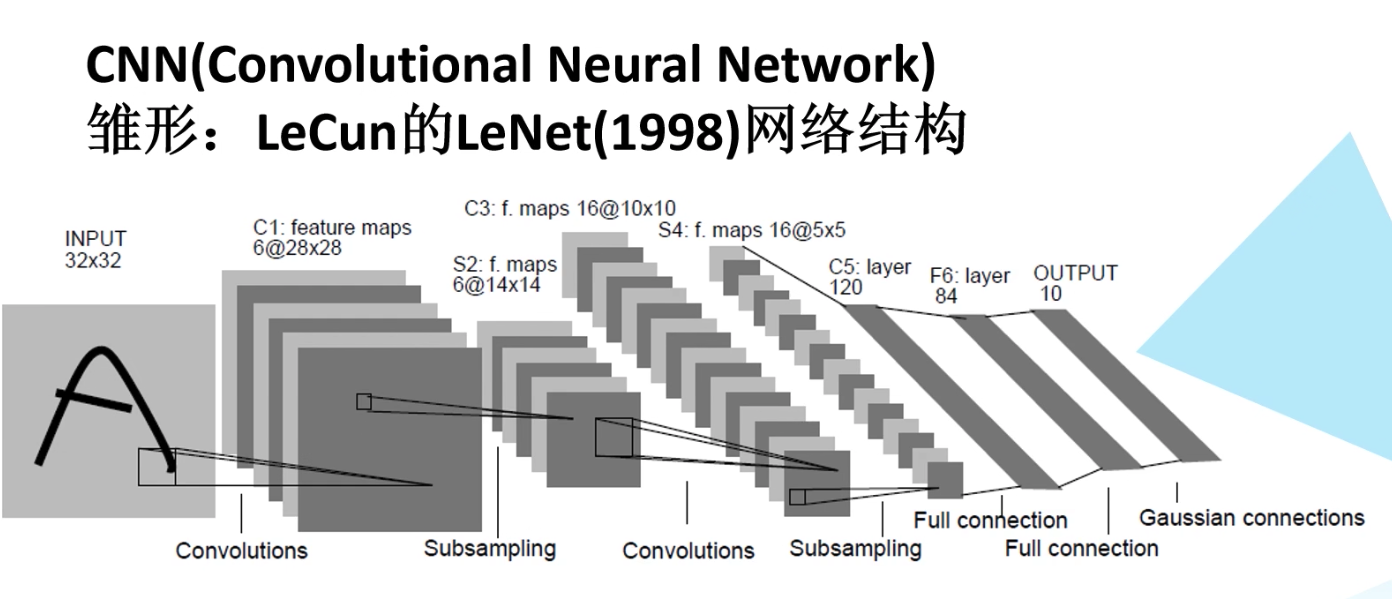
简略历史如下:

CNN组成和介绍
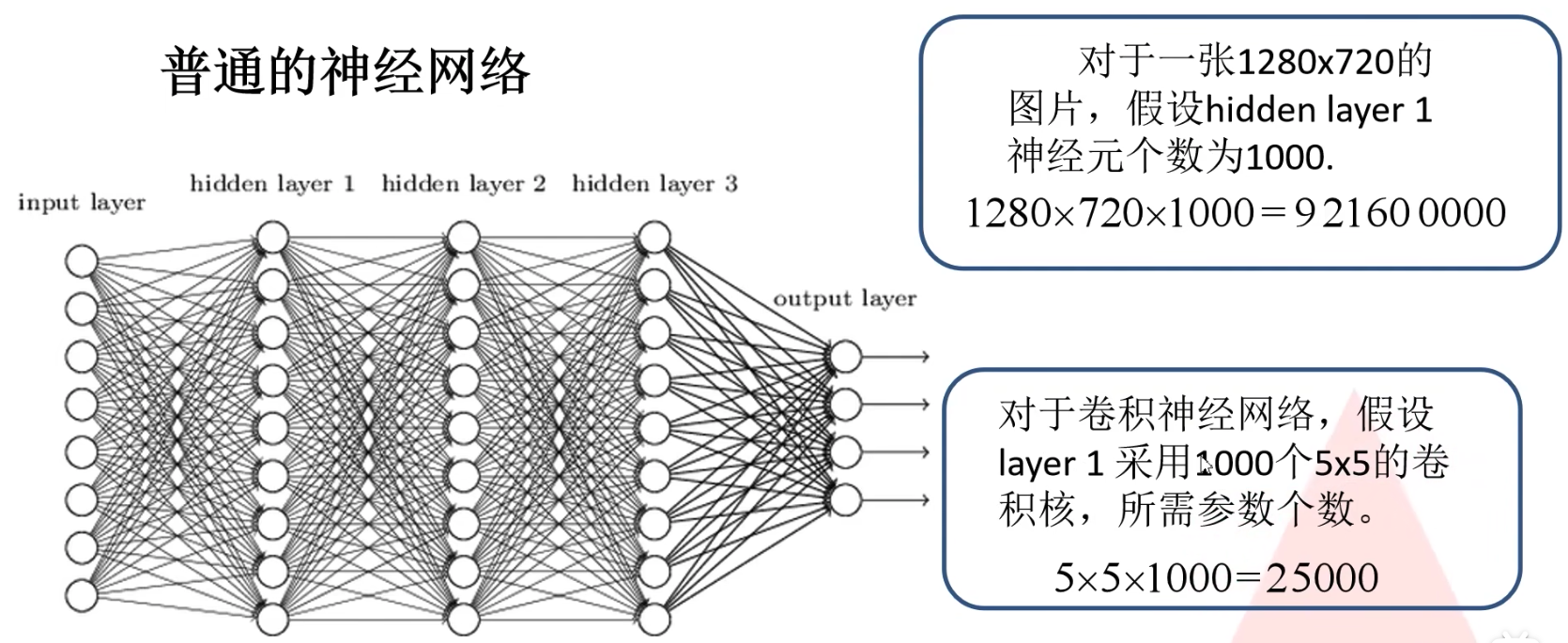
CNN的主要组成包括dense layer全连接层,convolutional layer卷积层,subsampling layer/down-pooling下采样层和upsampling layer上采样层,其中downsampling layer用于特征提取/减少,upsampling layer用于增加特征。
全连接层
在全连接层中,即将每个节点全连接并赋予权重值(可能还会增加bias偏置值)。全连接网络例子如下:
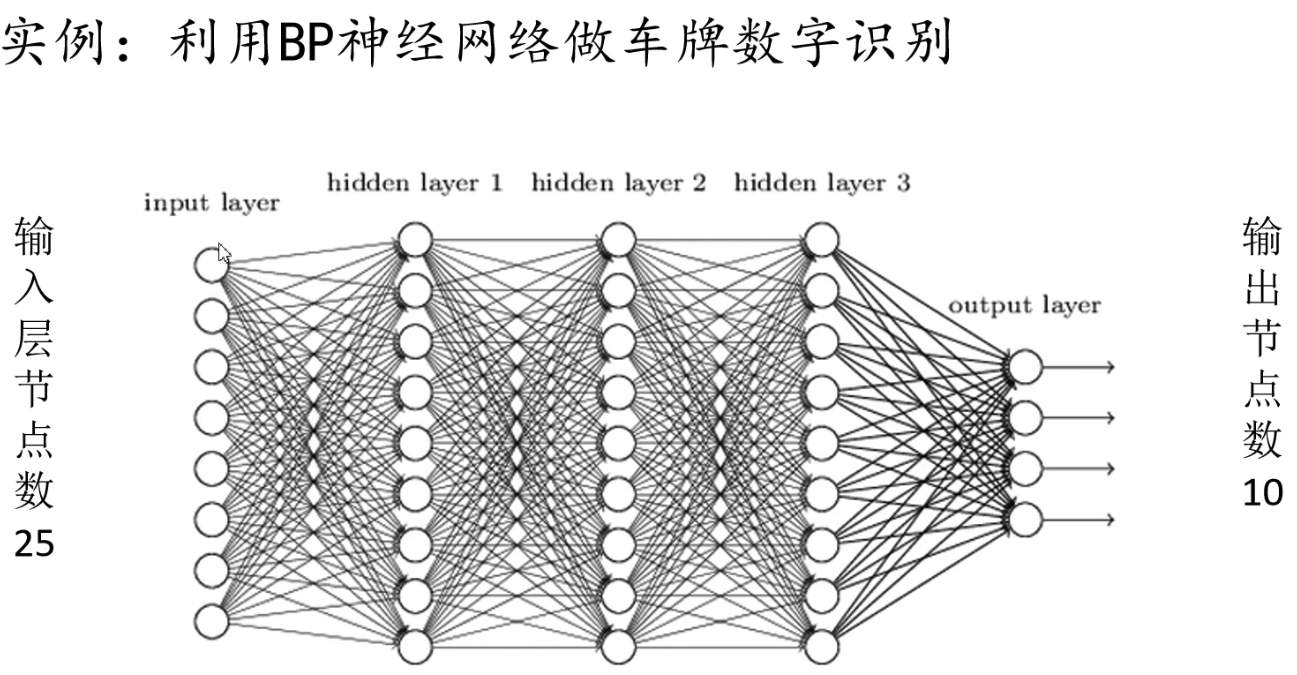
全连接层参数个数计算:
全连接层的参数个数计算取决于该层的输入维度、输出维度以及权重矩阵的大小。具体计算公式如下:
假设输入维度为 n n n,输出维度为 m m m,权重矩阵的大小为 w × h w\times h w×h,则全连接层的参数个数为:
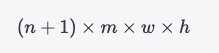
其中, n + 1 n+1 n+1 是因为每个神经元都有一个偏置项。
举个例子,假设输入维度为 1000,输出维度为 500,权重矩阵的大小为 200x100,则全连接层的参数个数为:

因此,这个全连接层的参数个数为 100,100,000。
卷积层
卷积层中最重要的就是filter/convolutional kernel卷积核,卷积层的主要目的是对图像进行特征提取,而每一次卷积即将卷积核和图像上数字进行矩阵点乘。
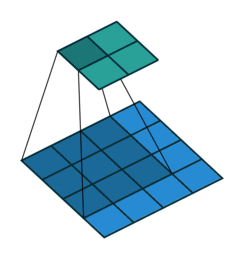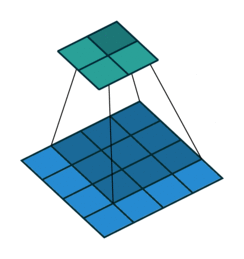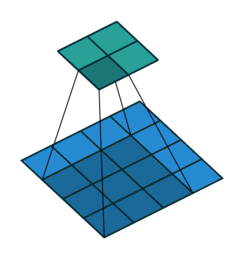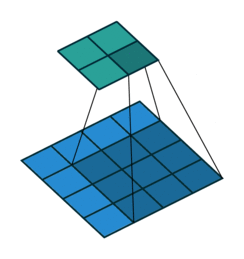
矩阵相乘分为矩阵叉乘(又叫矩阵乘, A × B {A}\times{B} A×B),矩阵点乘( A ⋅ B {A}\cdot{B} A⋅B)。矩阵乘法即线性代数中的一行乘一列,矩阵点乘即两矩阵对应元素相乘。
卷积层具有局部感知机制和权值共享。其中权值共享机制使得每一层卷积所需要的参数大大小于全连接层所需要的参数。例子如下:
需要注意的是:1. 卷积核的channel(深度/维数)与输入特征矩阵的channel相同;2. 输出特征矩阵的channel(深度/维数)与卷积核的个数相同。
对于输出特征矩阵,它的深度和卷积核个数相同,而对于它的大小则和输入图片大小,卷积核大小,步长,补充像素有关。输出特征矩阵大小的计算公式如下:
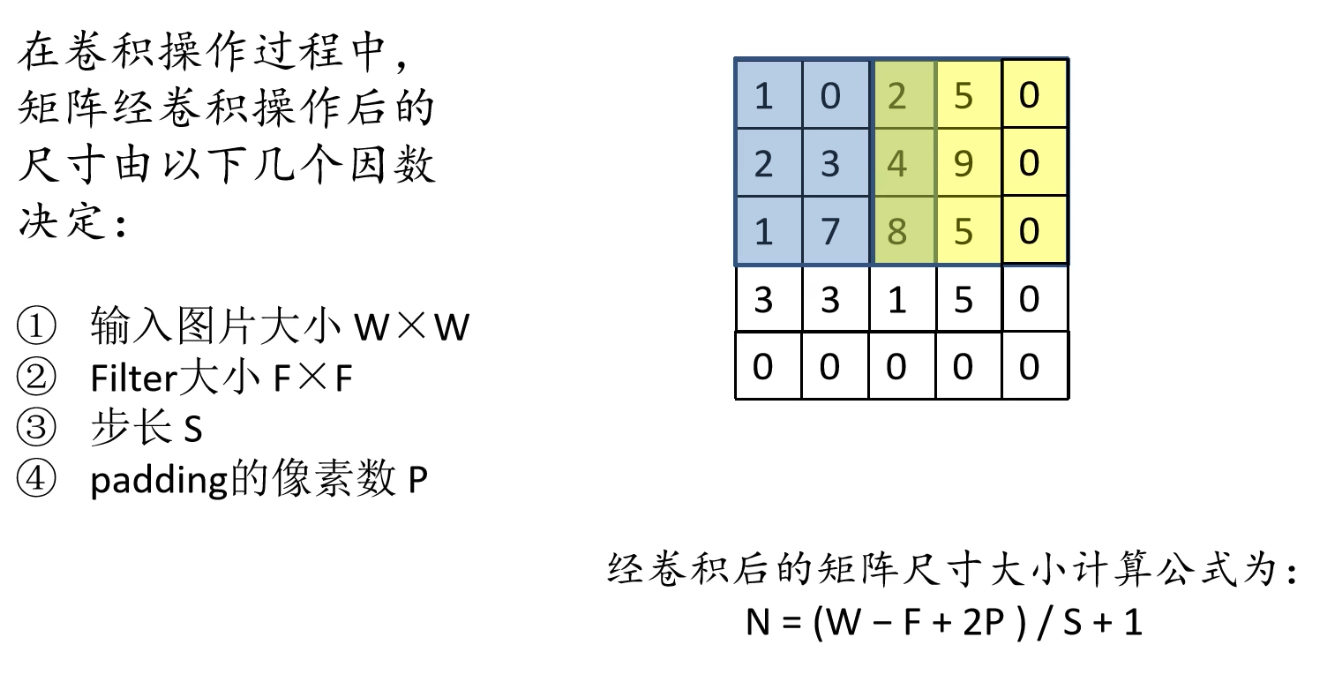
卷积层参数个数计算:
卷积层的参数个数计算取决于该层的卷积核尺寸、输入通道数、输出通道数。具体计算公式如下:
假设卷积核尺寸为 k × k k\times k k×k,输入通道数为 c i n c_{in} cin,输出通道数为 c o u t c_{out} cout,则卷积层的参数个数为:
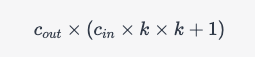
其中, c i n × k × k c_{in}\times k\times k cin×k×k 是卷积核中的权重参数个数, 1 1 1 是偏置参数个数。
举个例子,假设卷积核尺寸为 3 × 3 3\times 3 3×3,输入通道数为 64,输出通道数为 128,则卷积层的参数个数为:
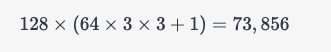
因此,这个卷积层的参数个数为 73,856。
需要注意的是,在计算参数个数时,如果卷积层的padding、stride、dilation等超参数发生变化,计算公式也需要做相应的修改。
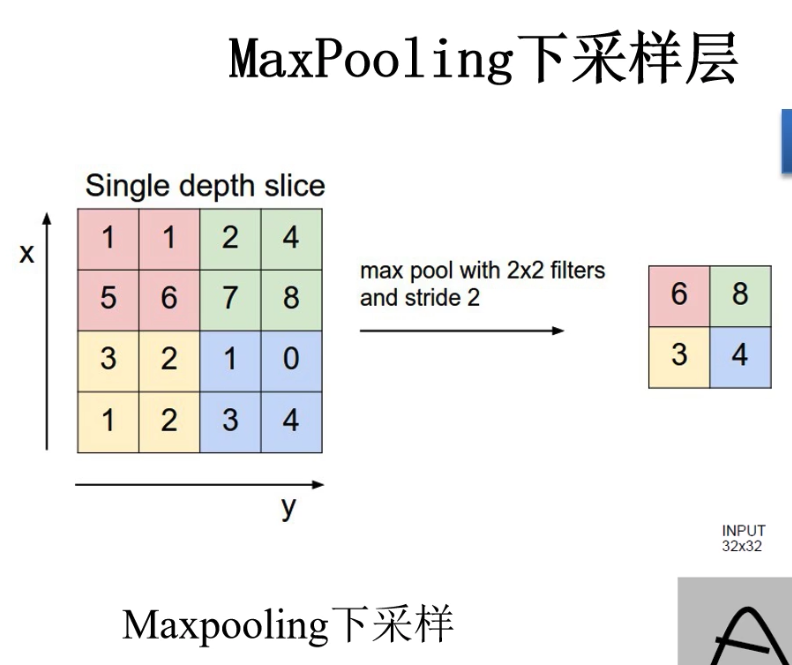
下采样层/池化层
下采样层的主要目的是对特征图进行稀疏处理,减少数据运算量。它具有以下三个特点:
- 没有训练参数。即不会和卷积层一样,需要更新/修正卷积核的参数。
- 只改变特征矩阵的w和h,不改变channel。
- 一般poolsize和stride相同。
下图以Maxpooling层为例:
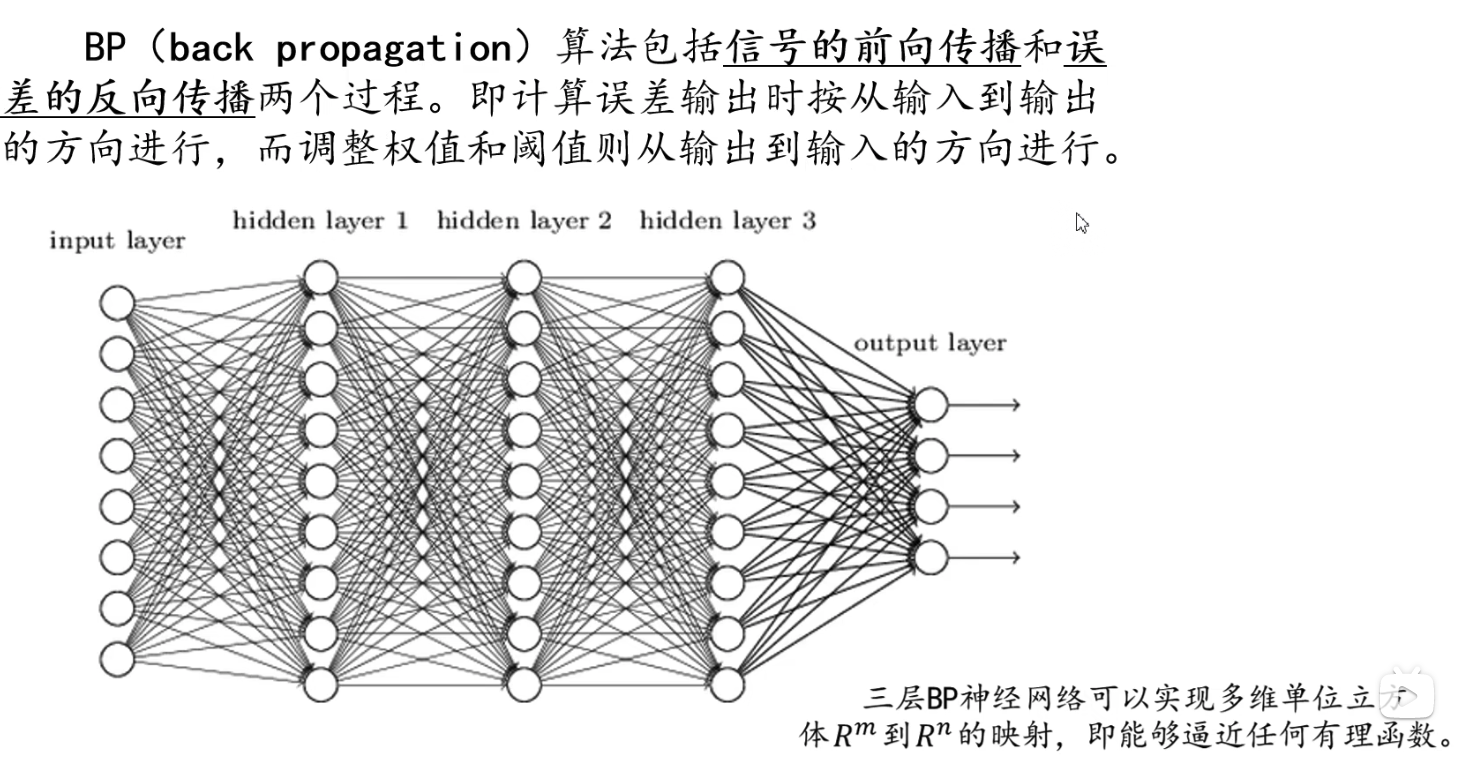
FP和BP算法
我们使用FP算法更新预测值 o u t p u t ^ \hat{output} output^,使用BP算法更新权重值weight。
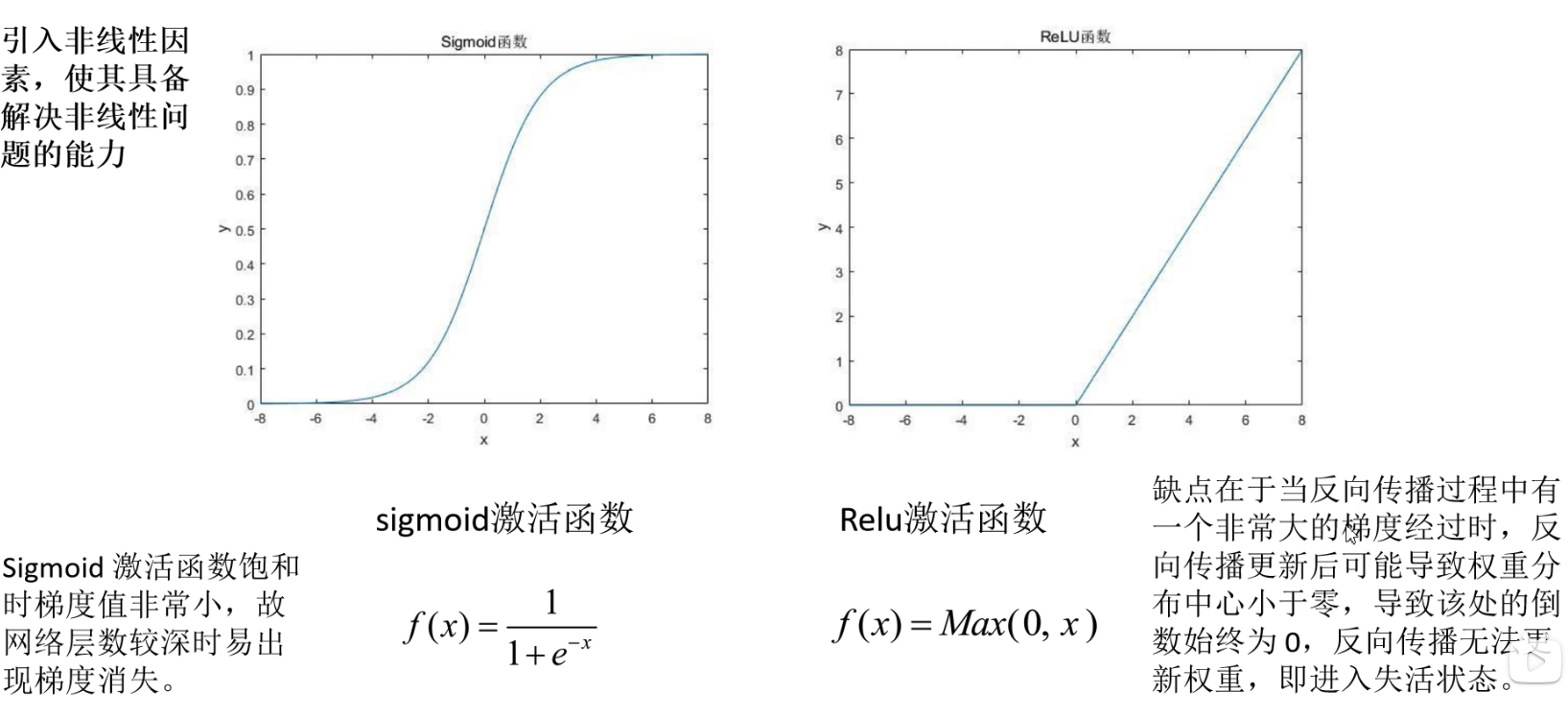
激活函数
引入激活函数即引入非线性因素使我们的网络具备解决非线性问题的能力。常见的有sigmoid/logic,softmax,ReLU等。
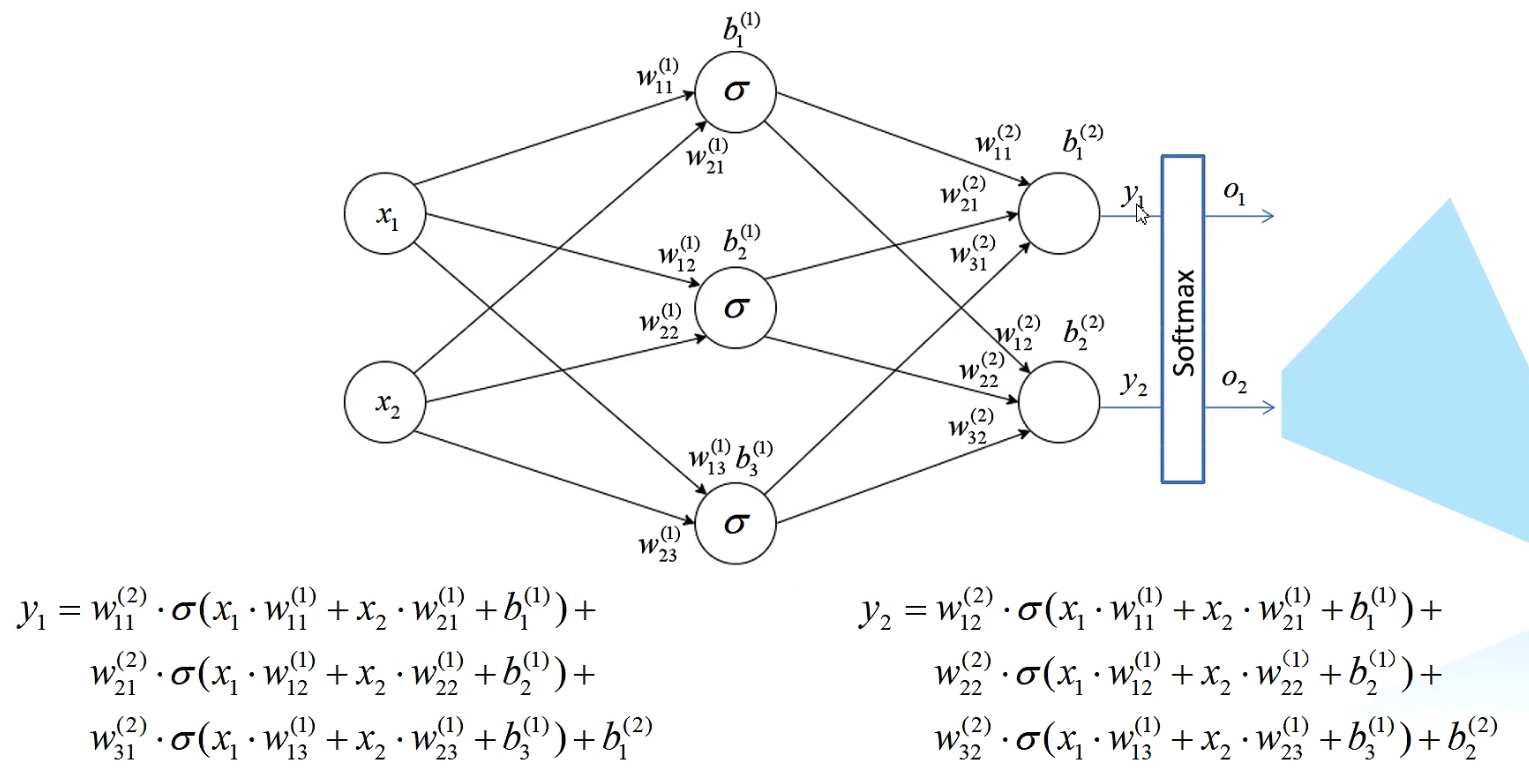
FP算法
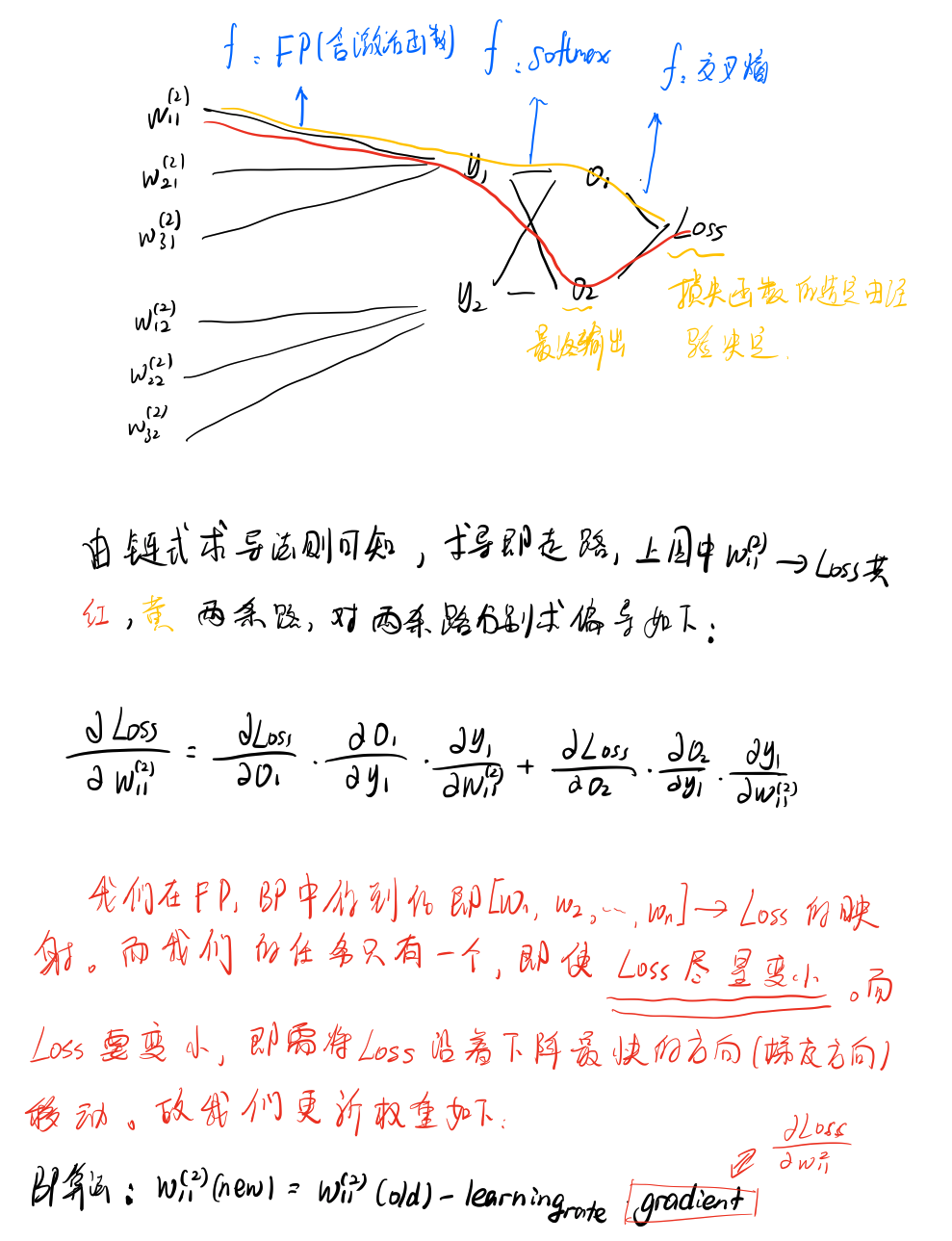
FP,forward propagation。用于更新预测值 o 1 ^ \hat{o_1} o1^。我们用上一层结果乘以权重再放入激活函数中得到下一层的输入结果,FP算法例子如下:
最终我们经历一系列计算得到了最终的output,我们根据经验选择适合的loss function损失函数,最终计算出来我们的Loss值(即自变量是weight权重值,因变量是Loss损失值)。
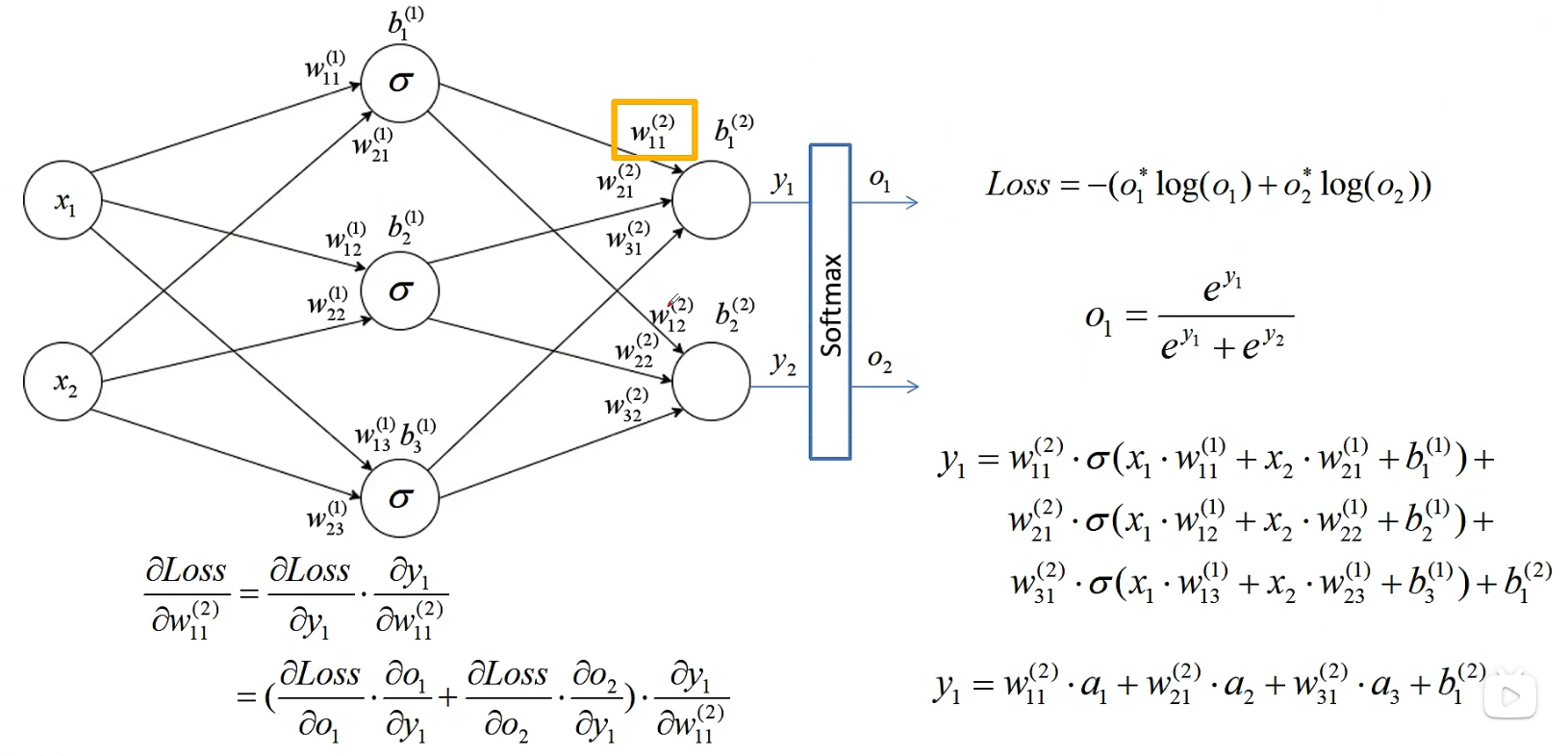
BP算法
我们得到了自变量为wight,因变量为Loss的函数。而我们在学习中要完成的终极目标就是使得损失函数的输出值尽量小,而多元函数的值要变小,便是让损失函数沿着下降最快的方向(梯度方向)下降,所以我们用链式法则求偏导,使用BP算法更新权重值如下:

手写推导部分如下:
梯度下降算法

优化器
如采用分批次等方法,使得更快收敛















 2988
2988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









