







实验一;大数据可视化工具—Excel
实验内容
1.练习excel数据读取及数据随机生成
2.读取相关实验数据,利用在单元格或编辑栏中直接输入带函数公式的方法求得个人成绩与平均成绩的差值
3.根据提供的成绩表数据,练习如何使用快捷键创建柱状图
4.练习如何使用功能区创建不同类型图表(展示创建过程,要求创建柱状图、散点图、饼图、折线图、雷达图,所有图的标题、x轴和y轴的标题,图例都要包含)
5.练习如何使用图表向导创建不同类型图表(展示创建过程,要求创建柱状图、散点图、饼图、折线图、雷达图,所有图的标题、x轴和y轴的标题,图例都要包含)
6.练习如何创建数据透视图
7.Excel power map展示中国不同省份人口数量对比
所需Excel表格数据可关注公众号:Time木 回复:大数据可视化Excel
所需以下所有用到的excel数据见章末注解2
实验详细操作步骤或程序清单:
1.练习excel数据读取及数据随机生成
1.1在excel中导入外部数据
(1)打开一个Excel文件的空白表格。
(2)在“数据”选项卡中单击“获取外部数据”按钮,可以看到关于数据的横向列表。
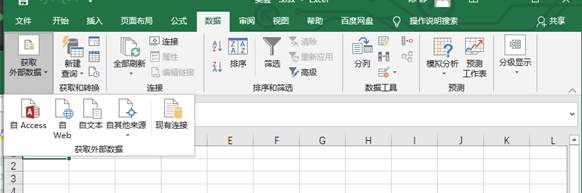
(3)此处导入的外部文件是文本文件类型为例,选择“自文本”选项
(4)在弹出的对话框,找到需要导入的文本数据的具体位置,单击导入

(5)进行选项设置,根据自己需要进行设置。单击下一步,一共三步,直到完成

(6)显示数据

1.2数据随机生成
(1)新建表格写入所需内容,并选中需要生成随机数据的单元格。
(2)单击“公式”选项卡中的“插入函数”,在弹出的窗口中,类别选“数学与三角函数”,函数选择“RANDBETWEEN”,然后单击“确定”。

(3)弹出“函数参数“对话框,在Bottom(最小值)中输入0,在TOP中输入100,单击”确定“.

(4)返回单元格区域,用鼠标拖动填充其他需要生成随机数的单元格。
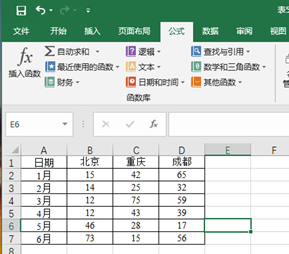
2,读取相关实验数据,利用在单元格或编辑栏中直接输入带函数公式的方法求得个人成绩与平均成绩的差值
(1)获取如图所示数据
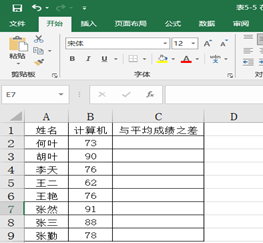
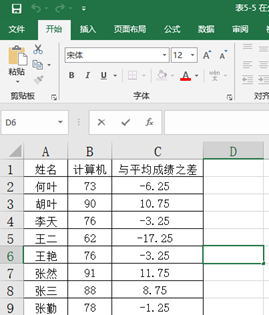
(2)选中需要求解平均成绩之差的单元格,在编辑栏中直接输入“=B2-AVERAGE(B$2:B$9)”该公式表示将B2单元格的成绩减去B2到B9单元格的平均值,从而得到B2单元格的值与平均成绩只差。
(3)C3到C9同理
3,根据提供的成绩表数据,练习如何使用快捷键创建柱状图
(1)打开成绩表,选择A1到D9单元格区域

(2)按“Alt+F1”在当前工作表中快速插入柱形图表。

4,练习如何使用功能区创建不同类型图表(展示创建过程,要求创建柱状图、散点图、饼图、折线图、雷达图,所有图的标题、x轴和y轴的标题,图例都要包含)
(1)打开成绩表,选择A1:D9单元格区域,在插入选项卡的“图表”根据要求分别选择柱状图、散点图、饼图、折线图、雷达图。

(2)分别在相应图标写上标题

5,练习如何使用图表向导创建不同类型图表(展示创建过程,要求创建柱状图、散点图、饼图、折线图、雷达图,所有图的标题、x轴和y轴的标题,图例都要包含)
(1)打开成绩表,选择A1:D9单元格区域,在插入选项卡的“图表”选择所有图表,然后根据要求分别选择柱状图、散点图、饼图、折线图、雷达图。

(2)分别在相应图标写上标题

6,练习如何创建数据透视图
(1)选择数据透视表的数据清单的任意一个单元格。
(2)在“插入”选项卡的“图表”选项组中单击“数据透视图”按钮,在弹出的窗口选择“数据透视图”。

(3)按照创建数据透视表的方法设置数据源和放置位置,单击“确定”,创建一个空数据透视表和数据透视图。


7.Excel power map展示中国不同省份人口数量对比
(1)打开数据表格,选中所要使用的数据的区域。

(2)单击“三维地图”选择“将选定数据添加到三维地图”(可能打不开,见注解1)

(3)位置选择省份,高度选择人数(求和)。

潦草教程,仅供参考。
注解
1,关于无法打开powermap三维地图
https://blog.csdn.net/qq_43374681/article/details/116230805
2,以上所需Excel表格数据可关注公众号:我是TIME0101 回复:大数据可视化Excel
关注公众号:Time木
更多大学课业实验实训可关注公众号回复相关关键词
学艺不精,若有错误还望指点
















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











