






系列文章目录
研究笔记(二):Adversarial attacks(对抗攻击)
文章目录
前言
本系列文章旨在记录本人探索对抗攻击领域的心路历程
作为上一篇的续作,这篇将继续学习对抗攻击的有关内容。
一、Adversarial attacks(续)
1.1 The C&W Attack
The Carlini & Wagner Attack,以名字命名的攻击方式,出自论文“Towards evaluating the robustness of neural networks“,这篇文章提出主要是针对当时很火的防御蒸馏,为了攻破这个防御机制,作者提出了根据距离度量的三种( L 0 L0 L0, L 1 L1 L1, L ∞ L∞ L∞)攻击方式,作者表示他们提出的攻击方式能够100%攻破防御蒸馏机制,攻击方式表达式如下:
minimize D ( x , x + δ ) such that C ( x + δ ) = t x + δ ∈ [ 0 , 1 ] n \begin{aligned} \operatorname{minimize} & \mathcal{D}(x, x+\delta) \\ \text { such that } & C(x+\delta)=t \\ & x+\delta \in[0,1]^n \end{aligned} minimize such that D(x,x+δ)C(x+δ)=tx+δ∈[0,1]n
在上式中,要找到最小的 D ( x , x + δ ) D(x,x+δ) D(x,x+δ)且满足 x + δ x+δ x+δ经过网络模型后与另一标签与之相对应,经过干扰 δ δ δ的图像 x x x不超出样本空间。这里 D ( . ) D(.) D(.)是距离量度,就是计算的 L 0 L0 L0或 L 1 L1 L1或 L ∞ L∞ L∞,论文中展现的是 L 0 L0 L0。作者认为上述公式中 C ( . ) C(.) C(.)是难以求解的,所以找一种更适合优化的其他形式来表示,在这里定义了一个 目标函数 f f f使得使得 C ( x + δ ) = t C(x+δ) = t C(x+δ)=t当且仅当 f ( x + δ ) ≤ 0 f(x+δ)≤0 f(x+δ)≤0,而对于 f f f的函数形式有以下几种选择:
f 1 ( x ′ ) = − loss F , t ( x ′ ) + 1 f 2 ( x ′ ) = ( max i ≠ t ( F ( x ′ ) i ) − F ( x ′ ) t ) + f 3 ( x ′ ) = softplus ( max i ≠ t ( F ( x ′ ) i ) − F ( x ′ ) t ) − log ( 2 ) f 4 ( x ′ ) = ( 0.5 − F ( x ′ ) t ) + f 5 ( x ′ ) = − log ( 2 F ( x ′ ) t − 2 ) f 6 ( x ′ ) = ( max i ≠ t ( Z ( x ′ ) i ) − Z ( x ′ ) t ) + f 7 ( x ′ ) = softplus ( max i ≠ t ( Z ( x ′ ) i ) − Z ( x ′ ) t ) − log ( 2 ) \begin{aligned} f_1\left(x^{\prime}\right) & =-\operatorname{loss}_{F, t}\left(x^{\prime}\right)+1 \\ f_2\left(x^{\prime}\right) & =\left(\max _{i \neq t}\left(F\left(x^{\prime}\right)_i\right)-F\left(x^{\prime}\right)_t\right)^{+} \\ f_3\left(x^{\prime}\right) & =\operatorname{softplus}\left(\max _{i \neq t}\left(F\left(x^{\prime}\right)_i\right)-F\left(x^{\prime}\right)_t\right)-\log (2) \\ f_4\left(x^{\prime}\right) & =\left(0.5-F\left(x^{\prime}\right)_t\right)^{+} \\ f_5\left(x^{\prime}\right) & =-\log \left(2 F\left(x^{\prime}\right)_t-2\right) \\ f_6\left(x^{\prime}\right) & =\left(\max _{i \neq t}\left(Z\left(x^{\prime}\right)_i\right)-Z\left(x^{\prime}\right)_t\right)^{+} \\ f_7\left(x^{\prime}\right) & =\operatorname{softplus}\left(\max _{i \neq t}\left(Z\left(x^{\prime}\right)_i\right)-Z\left(x^{\prime}\right)_t\right)-\log (2) \end{aligned} f1(x′)f2(x′)f3(x′)f4(x′)f5(x′)f6(x′)f7(x′)=−lossF,t(x′)+1=(i=tmax(F(x′)i)−F(x′)t)+=softplus(i=tmax(F(x′)i)−F(x′)t)−log(2)=(0.5−F(x′)t)+=−log(2F(x′)t−2)=(i=tmax(Z(x′)i)−Z(x′)t)+=softplus(i=tmax(Z(x′)i)−Z(x′)t)−log(2)
其中, s o f t p l u s ( x ) = l o g ( 1 + e x p ( x ) ) ) ) softplus(x) = log(1 + exp(x)))) softplus(x)=log(1+exp(x)))),loss函数是交叉熵损失函数,由此可以把 C ( . ) C(.) C(.)的优化问题替换掉,变为解决以下优化问题,其中 c c c是一个适当选择的常数。
minimize D ( x , x + δ ) + c ⋅ f ( x + δ ) such that x + δ ∈ [ 0 , 1 ] n \begin{array}{ll} \operatorname{minimize} & \mathcal{D}(x, x+\delta)+c \cdot f(x+\delta) \\ \text { such that } & x+\delta \in[0,1]^n \end{array} minimize such that D(x,x+δ)+c⋅f(x+δ)x+δ∈[0,1]n
学习之后感觉像是The L-BFGS Attack的改进版本,这种方式的
L
2
L2
L2范数得到的攻击样本看起来比 JSMA要好,做到了人眼无法辨别的程度。

1.2 Universal Adversarial Perturbations
和它的名字一样,作者想要得到一种扰动可以在任何图像上以高概率欺骗模型,相当于生成一个通用噪声,不管加到什么图像上都能扰乱识别,方法来自论文”Universal Adversarial Perturbations“,生成对抗的主要研究内容如下:
k ^ ( x + v ) ≠ k ^ ( x ) for "most" x ∼ μ . \hat{k}(x+v) \neq \hat{k}(x) \text { for "most" } x \sim \mu \text {. } k^(x+v)=k^(x) for "most" x∼μ.
在公式中
μ
\mu
μ表示
x
x
x的样本空间,
k
^
\hat{k}
k^表示分类器抽象化的函数,
v
v
v是需要寻找的微小扰动,这个微小扰动出自样本空间,但不是其中的某一个输入,这个扰动可以使所有出自
μ
\mu
μ的图像绝大多数都被分类器错误判断。将上面公式优化为解决下面公式来找到微小扰动
v
v
v。


在上面公式中
ξ
ξ
ξ为
v
v
v范数的限制,
δ
δ
δ量化了从分布
μ
μ
μ中采样的所有图像的期望对抗率
其实就是用数据集里面的图片每一张都计算一次扰动,这个范数始终是小于
ξ
ξ
ξ的,之后从第一张算得扰动起下一次计算得扰动满足小于
ξ
ξ
ξ的同时还满足这次扰动与上一次扰动相加之后仍然能使本次得对抗图像被错误识别,遍历过所有图片之后计算的扰动只需要乘以一个较小的值作为所有图像的干扰,在人眼能够接受的范围内使得绝大多数图像都被模型错误识别。下图是根据不同的网络模型计算得到的扰动图和被干扰的图像经过识别后输出错误标签的例子


思考:这种方法直接运用到分割上或许是一个不错方法,应该能弱化分割精度,在此mark一下。
至此结束了对2018年之前的攻击(第一代攻击)模式的简单研究,接下来对2018年之后的攻击(第二代攻击)进行探索学习。
二、 Recent Attacks on Classifiers
2.1 Robust Superpixel-Guided Attentional Adversarial Attack
作者提出当时存在的攻击大多都是以”像素级“或"全局"的方式添加扰动,这些方法对基于图像处理的防御方法和基于隐写分析的检测方法不具有鲁棒性。因此提出这一攻击方式,此方式只在图片中的显著区域添加对抗扰动,并保证在每个超像素内相同。作者称即使在这种高度受限的修改空间中,此方法也能保持攻击能力。与现有方法相比,该方法对基于图像处理的防御和基于隐写分析的检测具有显著的鲁棒性。目的还是为了干扰分类,干扰过程如下图所示。
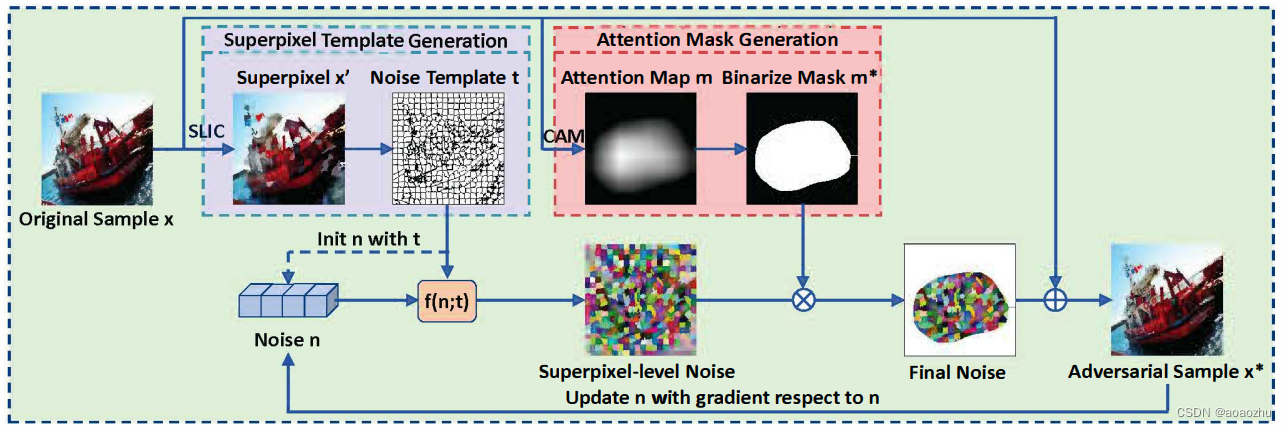
首先用SLIC算法将原图进行超像素处理,之后得到超像素噪声模板
t
t
t,初始化对抗噪声
n
n
n直接计算其梯度,其长度为超像素数,同时原图生成注意图用于裁剪显著区域噪声得到最终噪声图(Final Noise),之后使用生成的对抗样本对对抗噪声
n
n
n进行迭代。在每次迭代中,首先使用一个映射函数
f
f
f将
n
n
n填充到超像素级噪声模板
t
t
t中,得到填充噪声
f
(
n
;
t
)
f(n;t)
f(n;t),整体公式表达式如下:

2.2 GreedyFool: Distortion-Aware Sparse Adversarial Attack
作者提出稀疏对抗样本,可以通过干扰几个像素来欺骗目标模型。乍一看有些像One-pixel attack的思想,只不过变成了几个像素。作者提出一种攻击方式“GreedyFool”。它主要包括两个阶段,在第一阶段,我们根据梯度信息迭代选择 k k k个最合适的像素进行修改,直到攻击成功。在第二阶段,还应用此策略,尽可能多地减少不重要的像素,以进一步提高稀疏性。
稀疏攻击:指改变关键像素产生对抗攻击使网络判断错误
稠密攻击:指改变图片的所有像素产生对抗攻击使网络判断错误
在第一阶段迭代地增加扰动像素的数量,直到找到一个对抗的样本。在每次迭代中使用最新修改的图像
x
x
xtadv运行向前向后传递,以计算损失函数到
x
x
xtadv 的梯度。梯度值越大的像素点对干扰的贡献越大。
L
L
L(
x
x
xtadv,
y
y
y,
H
H
H)使损失函数,
g
g
gt代表求损失函数的梯度。
k
k
k是置信因子用来控制攻击力度。为了实现对抗样本的不可见性引入了图像的畸变图,其中像素的失真表示像素修改的可见性,失真越高意味着像素修改越容易被观察到。

在第一阶段生成的稀疏攻击已经能够达到攻击的效果,但是作者发现在第一次生成的干扰像素点中有冗余,所以进行第二阶段减少不必要的像素点达到更稀疏的扰动。扰动生成流程图如下。

作者提出了一个新的基于GAN的畸变图生成框架。该框架包含一个生成器 G G G和一个鉴别器 D D D,发生器和鉴别器进行极大极小博弈得到畸变图。全局扰动 x x x’‘是为了使GAN训练更加稳定,在计算 l o s s loss loss时有如下公式。

思考:生成对抗网络对于显著分割任务产生干扰图也可用上图中的流程,但在鉴别器与生成器的设置中应针对显著性与二值分割图像进行研究,比如,要对对抗图生成标签(gt)这个真值图如何选取,用GAN感觉有一定难度。
三、总结
学习到这里我们所遇到的大多用到了模型梯度进行计算得到扰动,但我们最终目的要找的还是应用于大多模型,即可转移性强的攻击方式,之后运用到实验之中,在接下来的学习中会更简洁的说明攻击方法,专注于其是否有可转移性。主要研究黑盒攻击。















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









