






超分辨率方法分为三类:
基于插值的方法:最近邻插值、双线性插值和双三次插
基于重建的方法:括频域方法和空域方法,但无法很好的模拟现实场景
基于学习的方法:基于卷积神经网络的SR方法、基于残差网络(residual network, ResNet)的SR方法和基于生成对抗网络(generative adversarial networks, GAN)的SR方法。
卷积
网络模型中的卷积层可以得到图像的特征信息
卷积层数少则为浅层特征信息,随着层数的增加逐渐变为深层特征信息
ResNet的分支操作就是将浅层特征信息与深层特征信息融合,之后在进行学习,从而提高学习能力
特征金字塔
单纯的卷积后获得深层特征信息进行处理的话,在下采样时会丢失小目标的细节,通过特征金字塔,即全部利用浅层到深层的特征层(太浅层的不要),综合处理金字塔所有层的特征从而提高学习质量。
以FPN网络为例子
对于一般的神经网络都是采用图b所示的方式来预测,通过对图像多次降采样,在最后一层进行预测,这种方式的缺点是对小目标的检测效果不好。
在SSD中采用了图c的方式,利用前几层的信息进行多尺度预测,这种方式的缺点是低层的语义信息不够,而且SSD为了避免重复使用前面已经卷积过的feature map,而从靠后的层(eg: conv4_3 of VGG nets )才开始构建金字塔,这样做的缺点就是金字塔的低层的分辨率也不够,丢失了前面层高分辨率的信息,而那些才是对识别小目标起重要作用的信息。
而FPN是目前应用比较广的一种方式,在图C的基础上增加了一条自上而下的路径,主要目的就是解决前面三种方式存在的问题。通过自上而下的路径,使得低层的feature map具有较好的语义信息。
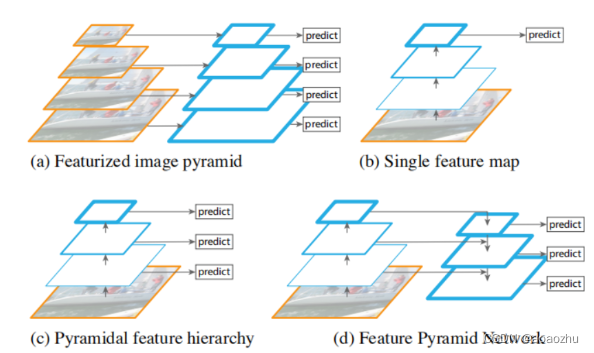
下图中的stage345就是利用的特征金字塔的中层深层特征层
注意力转移
即对不同的特征层处理,对想要的特征层给予更高的权重,从而给予更高的注意力,权重的分配由学习过程分配。
编码器
编码器是预先训练的图像分类模型(如VGG[29]和ResNet [8])提供多层次的深层特性:高级特性低分辨率表示语义信息,并且高分辨率的低层次特征代表了细致的细节。
解码器
特征融合之后的目的输出,例如目标识别,最后对原图进行框选,这一步骤就是解码。
上下采样
上采样原理:
图像放大几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素。
插值算法还包括了传统插值,基于边缘图像的插值,还有基于区域的图像插值。
下采样原理:
对于一副图像Ⅰ尺寸为M*N,对其进行s倍下采样,即得到(M/s)*(N/s)尺寸的分辨率图像,当然,s应该是M和N的公约数才可以;
如果考虑是矩阵形式的图像,就是把原始图像s*s窗口内的图像变成一个像素,这个像素点的值就是窗口内所有像素的均值或者最大值(也就是 Pooling池化操作等)。
对图像的缩放操作并不能带来更多关于该图像的信息, 因此图像的质量将不可避免地受到影响。然而,确实有一些缩放方法能够增加图像的信息,从而使得缩放后的图像质量超过原图质量的。
Pk = Σ Ii / s2
其实下采样就是池化。
采样层是使用 pooling 的相关技术来实现的,目的就是用来降低特征的维度并保留有效信息,一定程度上避免过拟合;
但是pooling的目的不仅仅是这些,他的目的是保持旋转、平移、伸缩不变形等。采样有最大值采样,平均值采样,求和区域采样和随机区域采样等
池化也是这样的,比如最大值池化,平均值池化,随机池化,求和区域池化等。
两种池化
采样层是使用池化 (pooling) 的相关技术来实现的,目的就是用来降低特征的维度并保留有效信息,一定程度上避免过拟合。但是池化的目的不仅仅是这些,还有保持旋转、平移、伸缩不变形等。
采样有最大值采样,平均值采样,求和区域采样和随机区域采样等。池化也是这样的,比如最大值池化,平均值池化,随机池化,求和区域池化等。
池化操作是在卷积神经网络中经常采用过的一个基本操作,一般在卷积层后面都会接一个池化操作,但是近些年比较主流的ImageNet上的分类算法模型都是使用的max-pooling,很少使用average-pooling,这对我们平时设计模型时确实有比较重要的参考作用。
通常来讲,max-pooling的效果更好,虽然max-pooling和average-pooling都对数据做了下采样,但是max-pooling感觉更像是做了特征选择,选出了分类辨识度更好的特征,提供了非线性,根据相关理论,特征提取的误差主要来自两个方面:(1)邻域大小受限造成的估计值方差增大;(2)卷积层参数误差造成估计均值的偏移。一般来说,average-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。average-pooling更强调对整体特征信息进行一层下采样,在减少参数维度的贡献上更大一点,更多的体现在信息的完整传递这个维度上,在一个很大很有代表性的模型中,比如说DenseNet中的模块之间的连接大多采用average-pooling,在减少维度的同时,更有利信息传递到下一个模块进行特征提取。
但是average-pooling在全局平均池化操作中应用也比较广,在ResNet和Inception结构中最后一层都使用了平均池化。有的时候在模型接近分类器的末端使用全局平均池化还可以代替Flatten操作,使输入数据变成一位向量。
转载原文链接:https://blog.csdn.net/qq_29931083/article/details/100084994
多尺度特征融合
https://blog.csdn.net/qq_40602790/article/details/124079984
对抗攻击
1.端到端可训练使得梯度很容易从监督目标传播到输入图像,这使得显著目标检测模型面临对抗性攻击的风险。
2.基于深度学习的显著目标检测模型大致可以分为两类。一组采用分段标记,另一组预测像素级结果。分段标记方法首先将图像划分为多个区域。同一区域的像素很可能具有相似的显著性值。然后提取每个区域的CNN特征来评估其显著性。相比之下,像素化方法通常采用全卷积网络(FCN)架构,它将整个图像作为输入并直接产生密集的显著性图。
3.CNN对一些通用噪声不太敏感,因为对抗样本是针对神经模型的。















 882
882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









