







深度学习存在的问题
一、瓶颈
https://www.zhihu.com/question/40577663/answer/729741077
1.需要大量标注数据
深度学习能够实现的前提是大量经过标注的数据,这使得计算机视觉领域的研究人员倾向于在数据资源丰富的领域搞研究,而不是去重要的领域搞研究。虽然有一些方法可以减少对数据的依赖,比如迁移学习、少样本学习、无监督学习和弱监督学习。但是到目前为止,它们的性能还没法与监督学习相比。
2.过度拟合基准数据
深度神经网络在基准数据集上表现很好,但在数据集之外的真实世界图像上,效果就差强人意了。比如下图就是一个失败案例。一个用ImageNet训练来识别沙发的深度神经网络,如果沙发摆放角度特殊一点,就认不出来了。这是因为,有些角度在ImageNet数据集里很少见。在实际的应用中,如果深度网络有偏差,将会带来非常严重的后果。要知道,用来训练自动驾驶系统的数据集中,基本上从来没有坐在路中间的婴儿。

3.对图像变化过度敏感
深度神经网络对标准的对抗性攻击很敏感,这些攻击会对图像造成人类难以察觉的变化,但可能会改变神经网络对一个物体的认知。而且,神经网络对场景的变化也过于敏感。比如下面的这张图,在猴子图片上放了吉他等物体,神经网络就将猴子识别成了人类,吉他识别成了鸟类。
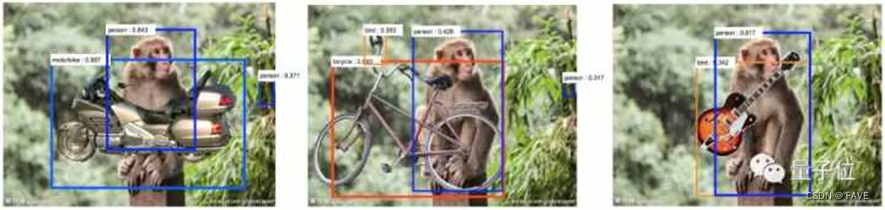
背后的原因是,与猴子相比,人类更有可能携带吉他,与吉他相比,鸟类更容易出现在丛林中。这种对场景的过度敏感,原因在于数据集的限制。对于任何一个目标对象,数据集中只有有限数量的场景。在实际的应用中,神经网络会明显偏向这些场景。对于像深度神经网络这样数据驱动的方法来说,很难捕捉到各种各样的场景,以及各种各样的干扰因素。想让深度神经网络处理所有的问题,似乎需要一个无穷大的数据集,这就给训练和测试数据集带来了巨大的挑战。
注:组合爆炸的概念
视觉领域,真实世界的图像,从组合学观点来看太大量了。任何一个数据集,不管多大,都很难表达出现实的复杂程度。例如现在要搭建一个视觉场景:有一本物体字典,要从字典里选出各种各样的物体,把它们放到不同的位置上。每个人选择物体、摆放物体的方法都不一样,搭出的场景数量是可以指数增长的。就算只有一个物体,场景还是能指数增长。因为,它可以用千奇百怪的方式被遮挡;物体所在的背景也有无穷多种。
二、问题:
小目标检测
一、主要原因
(1)小目标在原图中尺寸比较小,通用目标检测模型中,一般的基础骨干神经网络(VGG系列和Resnet系列)都有几次下采样处理,导致小目标在特征图的尺寸基本上只有个位数的像素大小,导致设计的目标检测分类器对小目标的分类效果差。
(2)小目标在原图中尺寸比较小,通用目标检测模型中,一般的基础骨干神经网络(VGG系列和Resnet系列)都有几次下采样处理,如果分类和回归操作在经过几层下采样处理的 特征层进行,小目标特征的感受野映射回原图将可能大于小目标在原图的尺寸,造成检测效果差。
二、其他原因
(1)小目标在原图中的数量较少,检测器提取的特征较少,导致小目标的检测效果差。
(2)神经网络在学习中被大目标主导,小目标在整个学习过程被忽视,导致导致小目标的检测效果差。物体遮挡和物体堆叠
遮挡
目标检测中存在两类遮挡:
1.物体堆叠:待检测的目标之间相互遮挡
2.物体遮挡:待检测的目标被干扰物体遮挡。

具体来说,如果检测任务的目标是汽车和人,那么汽车被人遮挡,而且人被干扰物体(牛)遮挡。因为算法只学习待检测的物体的特征,所以第二种遮挡只能通过增加样本来优化检测效果。在现实的检测任务中,只有比较特殊的场景需要考虑遮挡问题,比如行人检测、公交车上密集人群检测、牲畜数量计算等。导致该问题的原因主要是:
(1)高度重叠的实例(以及它们的相关候选区域)可能具有非常相似的特性。因此,检测器很难对每个建议分别生成有区别的预测。
(2)实例之间可能会严重重叠,因此预测很可能被NMS错误地抑制,出现该问题的具体原因如下。
如下图所示,其中T1,T2为Groundtruth框,而P1,P2,P3为anchors,由于P2中包含了T2的部分区域,所以P2对应的proposals很容易受到T2的干扰,导致回归出来的proposal同时包含了目标T1,T2的部分区域,不精准。
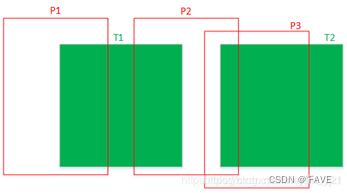
假设图中的预测框P1不存在,也即T1对应的proposals只有P2,如果T2对应的max score的proposal近似为P3,那么当P2和P3的IOU大于阈值时,在后处理nms阶段就会把P2过滤掉,从而导致更严重的情况,T1被漏召回。
原文链接:https://blog.csdn.net/andyjkt/article/details/107849011
基于深度学习的视频目标检测 https://zhuanlan.zhihu.com/p/67608224
视频目标检测
视频目标检测任务中最大的困难就是如何保持视频中目标的时空一致性。众所周知,视频是由多个有序列关系的图像组成的,该序列关系是一种时间的序列关系,因此其中的目标如果在运动,那么空间位置以及其自身的属性会发生变化,而且这种变化与时间存在紧密的关系,但即使发生了变化,每一帧的发生变化的目标还是属于同一个目标,这就叫做时空一致性。
具体的挑战分为以下五类:
1.运动模糊:目标在现实中的运动实际上是一个连续的过程,但是摄像机是按照一幅一幅图的取景,每次捕捉图像的时候,会用快门控制外景进入相机内部成像组件,而快门闭合的速度就决定每次取景有多长时间外景被捕捉到,所以就会出现目标一段运动中多个被合成为一个的情况,也就产生了运动模糊。这个时候,目标的外观并不容易被分辨,如图1所示。

图1 运动模糊
2.虚焦:这是因为摄像设备并没有一直准确的对目标进行对焦产生的问题。这种情况可能会使视频一种一些包含目标的帧中目标出现模糊或者使视频一些帧的图像产生整体的模糊,如图2所示。

图2 虚焦
3.遮挡:目标在运动过程中,可能会出现运动到一些物体的后方,而被该物体遮挡,如图3所示。

图3 遮挡
4.外观变化:视频中目标可能会出现外观上的变化,例如图4中所示变色龙出现罕见的姿势。

图4 外观变化
5.尺度变化:目标在运动过程中,从镜头中远的地方运动到近的地方,其外观的尺寸可能会发生变化。















 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









