







1.数据集和任务定义
本次采用的是唐诗数据集,一共有接近60000首唐诗,不需要标签,因为AI自动写诗可以看成是语言模型的一个应用。
数据集下载(不需要积分):https://download.csdn.net/download/qq_43391414/20184591。
其中一首诗的一句如下:
| 上句 | 下句 |
|---|---|
| 度 门 能 不 访 | 冒 雪 屡 西 东 |
任务定义:给出一首诗的开头几个词,或者首句(随便),续写之后的句子。
测试结果初窥:
| 输入 | 上句 | 下句 |
|---|---|---|
| 度 门 能 不 | 度门能不见 | 今日复不知 |
| 举头望 | 举头望山中 | 一年一年年 |
| 会当 | 会当年少年 | 春风吹新开 |
初步感觉还不错,不但有一些意境,而且其还学会了5个字就打一个逗号,10个字就打一个句号。
2.读取数据集
import numpy as np
file_path="D:\Download\\tang.npz"
poem=np.load(file_path,allow_pickle=True)
poem.files
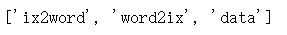
ix2word,word2ix,data=poem['ix2word'],poem['word2ix'],poem['data']
一些其他操作:
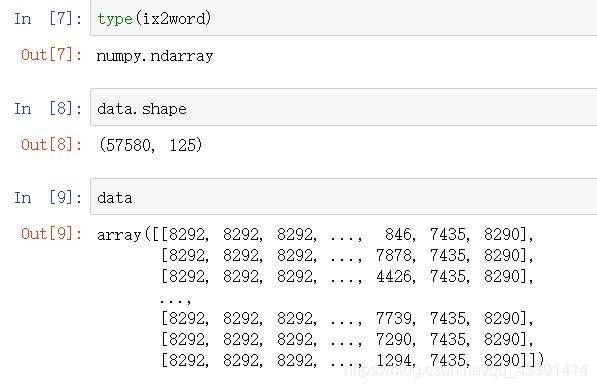
char2ix=word2ix.item()
ix2char=ix2word.item()
vocab_size=len(char2ix)
vocab_size
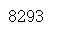
pad_id=char2ix["</s>"]
start_id=char2ix["<START>"]
end_id=char2ix["<EOP>"]
print(pad_id,start_id,end_id)
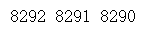
3.数据预处理
资源限制,如果你是用你自己的笔记本跑的话,最好和我一样,选少一些诗进行训练,用服务器的可以根据自己需要。
#减少训练的量,选2000首诗进行训练。
data=data[:2000]
data.shape
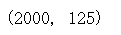
我们的数据集是填充符</s>在前面,诗在后面,我看得不爽,把诗放在前面,你可以忽略,后面相应的变化下,也没问题。
#把</s>放在放到后面。
def reverse(poem):
ind=np.argwhere(poem==start_id).item()
new_poem=poem[ind:len(poem)]
pad=poem[0:ind]
return np.hstack((new_poem,pad))
#将数据进行转换。
for i in range(len(data)):
data[i]=reverse(data[i])
for i in range(data.shape[1]):
print(ix2char[data[3][i]],end=" ")
查看第4首诗:

我们发现,一首诗大部分都是</s>,其实这对我们的训练是不利的,我们的模型会只想着预测下一个词为</s>,因为由上面可知,通常都是对的。而且我训练过,的确是这样,所以我有了另外的处理办法,后面说。
获得预测标签,即下一位。比如上面那首诗,LSTM当前输入是庭的时候,我们希望其输出是树。
def label(poem):
return np.hstack((poem[1:len(poem)],pad_id))
datay=np.zeros(data.shape).astype(np.int64)#这个zeros函数默认返回的就是float32类型。
#### label在pytorch中要求是long型,也就是Numpy中的Int64
for i in range(len(data)):
datay[i]=label(data[i])
datay
4.数据制作
batch_size=1
epochs=2
hidden_size=50
embedding_dim=50
为什么batch_size=1?我的考虑就是因为诗里面有大量的</s>,但是两首诗中</s>的数量不一样,如果把一首诗的长度从125删到50,另外一首诗可能还有</s>,或者多删了(把诗都删除了一部分)。所以索性每次只训练一首诗,这样长度灵活。
import torch
import torch.utils.data as tdata
data_inputs = torch.tensor(data)
labels=torch.LongTensor(torch.tensor(datay))
print(data_inputs.shape)
print(labels.shape)
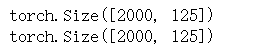
下面无需多少,标准的制作dataset和dataloader的过程,之前我的系列早就说过了。
class mydataset(tdata.Dataset):
def __init__(self, data_inputs, data_targets):
self.inputs = data_inputs
self.label = data_targets
def __getitem__(self, index):
return self.inputs[index], self.label[index]
def __len__(self):
return len(self.inputs)
dataset=mydataset(data_inputs,labels)
dataset[100]

上面第一个是输入,下一个是输出(标签),发现移了一位,第一个中8291下一个词是6575,恰好是第二个中的第一个6575,即其需要预测下一个词。
dataloader = tdata.DataLoader(dataset,
batch_size=batch_size,
shuffle=True,
)
5.定义网络结构:
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class LSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(LSTM, self).__init__()
self.hidden_dim = hidden_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim,batch_first=True)
self.linear = nn.Linear(hidden_dim, vocab_size)
def forward(self, input,hc0=None):
#hc0:指的是给定的输入句子,其会转化成这个h0和c0,作为起始的hc0。hc0=(h0,c0)
if hc0==None:
hc0=gethc0(input)
batch_size, seq_len = input.size()
embeds = self.embeddings(input).float() # [batch, seq_len] => [batch, seq_len,embed_dim]
output, hc = self.lstm(embeds,hc0)#output:batch, seq_len,hidden_dim
output = self.linear(output)##output:batch, seq_len,vocab_size
#output:batch*seq_len,vocab_size
return output,hc
#hc本来的确不需要,但是如果给定了几个首句,我们就需要这个东西,然后再开始预测。
#linear层其实对每一个字从hidden_size变成vocab_size,这个参数都是一样的,并不是序列中的位置1和位置2不一样。
自己好好理解以下,那个hc0是用于测试的时候需要用,或者说语言模型都需要这个。其他的,比如文本分类什么的不需要这个参数。
model=LSTM(vocab_size=vocab_size, embedding_dim=embedding_dim, hidden_dim=hidden_size)
lr=1e-4
optimizer=optim.Adam(model.parameters(),lr=lr)
loss_fn=nn.CrossEntropyLoss()
epochs=60
#记录训练误差。
losses=[]
for i in range(epochs):
model.train()
for idx,(datax,datay) in enumerate(dataloader):
#由于现在是一次处理一首诗,所以可以将哪些<s>去掉,我个人会觉得更好。
pad_index=np.argwhere(t_data.view(-1)==pad_id).min().item()
datax=datax[:,:pad_index]
datay=datay[:,:pad_index]
output,hc=model(datax,None)
loss=loss_fn(output.view(-1,vocab_size),datay.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if idx%250==1:
losses.append(loss.item())
print("epoch:{},loss:{}".format(i,loss.item()))

别急,训练的时间好像用了不到20分钟把,但是效果好啊。
6.测试网络
def sentence2id(sentence):
ids=[]
for i in range(len(sentence)):
ids.append(char2ix[sentence[i]])
return ids
def test(start_sentence=["<START>"],poem_len=20):
#输入start_id,并得到最后一个hidden,cell,然后递归传入。
#poem_len:指定需要最多生成多少句诗词。
#转化为id形式。
poempre=sentence2id(start_sentence)
#将poempre转化成标准的shape形式#batch_size,seq_len
poempre=torch.tensor(poempre).unsqueeze(0)
print("给定的句子为:",end=" ")
for i in range(len(start_sentence)):
print(start_sentence[i],end=" ")
print()
print("续写如下:")
model.eval()
output,hc=model(poempre,None)
#output:batch*seq_len,vocab_size
#hc:batch*1*hidden_size
# 利用hc作为初始状态,利用上一个输出作为这一次的输入。
for i in range(poem_len):
#注意不要搞错了,这里的output并不是lstm的output,而是整个网络的output,但是这个hc确实lstm的最后隐状态。
pred_id=np.argwhere(output==torch.max(output)).max().item()
print(ix2char[pred_id],end=" ")
#需要重新构造input了。#batch_size,seq_len
if(pred_id== end_id):
break#生成了<eop>。
new_input=torch.tensor([pred_id]).unsqueeze(0)
model.eval()
output,hc=model(new_input,hc)
print()
print("生成完毕")
def gethc0(x):
return (x.new_zeros((1,x.shape[0],hidden_size),requires_grad=False).float(),
x.new_zeros((1,x.shape[0],hidden_size),requires_grad=False).float())
start_sentence=["<START>","会","当"]
poem_len=10
test(start_sentence,poem_len)

7.可视化
import matplotlib.pyplot as plt
plt.plot(losses)
plt.ylim(ymin=2, ymax=10)
plt.title("The accuracy of LSTM model")
plt.show()
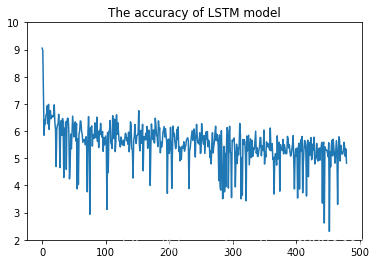
可以看到,450多的时候的那个模型没准是最好的。
8.总结
我觉得一个可以尝试的点是选取一个长度,例如把诗的长度都截取到50个字,现在是125。这样应该会少很多</s>,虽然浪费了一些诗,而且也有一些诗还有</s>,但是已经少很多噪音了。
而且这个方法的优势在于batch_size可以取32啊之类的,一般来说使用batch_size模型会训练得更好,而我这里batch_size=1相当于没有使用,所以你看可视化的图,抖动得比较厉害。
你可以试试。


















 9167
9167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











