







目录
os.path.join()
-
函数功能: 连接两个或更多的路径名分量。
-
注意:
- 如果路径首字母不包含’/’,则函数会自动加上’/’
- 如果有一个组件是一个绝对路径,则在它之前的所有组件均会被舍弃;
绝对路径和相对路径:
绝对路径:目标文件在硬盘上的真实路径(最精确路径)
C:\Users\80975\OneDrive\Desktop\cover\cover1.jpg _就是绝对路径
相对路径:相对于当前文件位置的路径
1.引用上级文件: …/cover1.jpg
2.引用同级文件: cover1.jpg
3.引用下级文件: cover/cover1.jpg
4.引用上上级文件: …/…/cover1.jpg- 存在以‘’/’’开始的参数,从最后一个以”/”开头的参数开始拼接,之前的参数全部丢弃。
- 同时存在以‘’./’与‘’/’’开始的参数,以‘’/’为主,从最后一个以”/”开头的参数开始拼接,之前的参数全部丢弃。
- 如果最后一个组件为空,则生成的路径以一个’'分隔符结尾;
- 如果不显示地添加斜杠‘/’,那么程序会自动添加反斜杠‘\’
# 不良写法习惯
os.path.join('/SRCNN','/experiment/epoch','/last_ckp.pth')
# 建议写法:将‘/’放在每个路径名组件的后面,即紧随其后!
os.path.join('/SRCNN/','experiment/epoch/','last_ckp.pth')
# 输出
/SRCNN/experiment/epoch/last_ckp.pth
zip()
- 函数功能: 用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
>>> a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 返回一个对象
>>> zipped
<zip object at 0x103abc288>
>>> list(zipped) # list() 转换为列表
[(1, 4), (2, 5), (3, 6)]
>>> list(zip(a,c)) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> a1, a2 = zip(*zip(a,b)) # 与 zip 相反,zip(*) 可理解为解压,返回二维矩阵式
>>> list(a1)
[1, 2, 3]
>>> list(a2)
[4, 5, 6]
>>>
pandas.to_datatime()
- 函数功能: 把pandas某一列的时间数据(时/分/秒)转换成时间格式,于是需要to_datetime
- to_datetime默认会有(年/月/日/时/分/秒)六个属性
- 只保留时刻的函数
- data[‘just_time’]=data1[‘地震发生时间’].dt.time
data[‘just_data’]=data[‘地震发生时间’].dt.data
data[‘just_hour’]=data[‘地震发生时间’].dt.hour
dt.year,dt.month,dt.day
- data[‘just_time’]=data1[‘地震发生时间’].dt.time
- 修改格式
- elborn[“time”] = pd.to_datetime(elborn[“time”], format=“%Y-%m-%d %H:%M:%S”)
pandas中的groupby
在日常的数据分析中,经常需要将数据根据某个(多个)字段划分为不同的群体(group)进行分析,如电商领域将全国的总销售额根据省份进行划分,分析各省销售额的变化情况,社交领域将用户根据画像(性别、年龄)进行细分,研究用户的使用情况和偏好等。在Pandas中,上述的数据处理操作主要运用groupby完成。
(0)、模拟生成数据
company=["A","B","C"]
data=pd.DataFrame({
"company":[company[x] for x in np.random.randint(0,len(company),10)],
"salary":np.random.randint(5,50,10),
"age":np.random.randint(15,50,10)
}
)
print(f"{data}")

(1)、groupby基本原理
- 将数据按照公司分组(只需一行代码)
group = data.groupby("company")
- group是一个DataFrameGroupBy对象

- 直接输出的结果是内存地址,将group转成list进行查看
list_group = list(group)
print(list_group)
输出:
[('A', company salary age
5 A 35 44),
('B', company salary age
0 B 17 27
6 B 26 48
8 B 17 42),
('C', company salary age
1 C 20 18
2 C 20 39
3 C 8 19
4 C 34 30
7 C 14 22
9 C 26 36)]
- 列表由三个元组组成,每个元组中,第一个元素是组别(这里是按照company进行分组,所以最后分为了A,B,C),第二个元素的是对应组别下的DataFrame,整个过程可以图解如下:

- 总结: groupby的过程就是将原有的DataFrame按照groupby的字段(这里是company),划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作。
(3)、agg操作
聚合操作可以用来求和、均值、最大值、最小值等。
- pandas中常见的聚合操作:

- 求不同公司员工的平均年龄以及薪水的中位数,可以利用字典进行聚合操作的指定
mean = group.agg('mean')
print(mean)
 - 不同的列求不同的值,比如要计算不同公司员工的平均年龄以及薪水的中位数
- 不同的列求不同的值,比如要计算不同公司员工的平均年龄以及薪水的中位数
split_agg = group.agg({'salary':'median','age':'mean'})
print(split_agg)

(5)、transform操作
transform是一种什么数据操作?和agg有什么区别呢?
使用agg操作可以求不同公司的平均薪水,但是如果要在原数据集中加入一个新的列avg_salary代表员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水)
- 不用transform的话,实现代码如下:
avg_salary_dict = data.groupby('company')['salary'].mean().to_dict() # 先求得不同公司的平均薪水
data['avg_salary'] = data['company'].map(avg_salary_dict) # 按照员工和公司的对应关系填充到对应的位置
print(data)

- 使用transform:
data['avg_salary'] = data.groupby('company')['salary'].transform('mean')
print(data)

- 进行groupby后transform的实现过程(为了更直观展示,图中加入了company列,实际按照上面的代码只有salary列)


有什么区别?
- 对agg而言,会计算得到A,B,C公司对应的均值并直接返回
- 对transform而言,则会对每一条数据求得相应的结果,同一组内的样本会有相同的值,组内求完均值后会按照原索引的顺序返回结果
参考链接:Pandas教程 | 超好用的Groupby用法详解
seaborn库
- 是啥: Seaborn 其实是在matplotlib的基础上进行了更高级的 API 封装,从而使得作图更加容易 在大多数情况下使用seaborn就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充。Seabn是基于MatPultLB的Python可视化库。它为绘制有吸引力的统计图形提供了一个高级接口。
添加链接描述
 图片参考
图片参考 - 风格设置:seaborn的风格设置主要分为两类,其一是风格(style)设置,其二是环境(context)设置。
- style:
- set,通用设置接口
- set_style,风格专用设置接口,设置后全局风格随之改变
- axes_style,设置当前图(axes级)的风格,同时返回设置后的风格系列参数,支持with关键字用法
-
darkgrid,默认风格
whitegrid
dark
white
ticks - 相比matplotlib绘图风格,seaborn绘制的直方图会自动增加空白间隔,图像更为清爽。而不同seaborn风格间,则主要是绘图背景色的差异
- context:
-
set,通用设置接口
-
set_context,环境设置专用接口,设置后全局绘图环境随之改变
-
plotting_context,设置当前图(axes级)的绘图环境,同时返回设置后的环境系列参数,支持with关键字用法
-
当前支持的绘图环境主要有4种:
notebook,默认环境
paper
talk
poste

-
可以看出,4种默认绘图环境最直观的区别在于字体大小的不同,而其他方面也均略有差异。
-
- style:
- 颜色设置:
- color_palette,基于RGB原理设置颜色的接口,可接收一个调色板对象作为参数,同时可以设置颜色数
- hls_palette,基于Hue(色相)、Luminance(亮度)、Saturation(饱和度)原理设置颜色的接口,除了颜色数量参数外,另外3个重要参数即是hls
- 绘制图表:
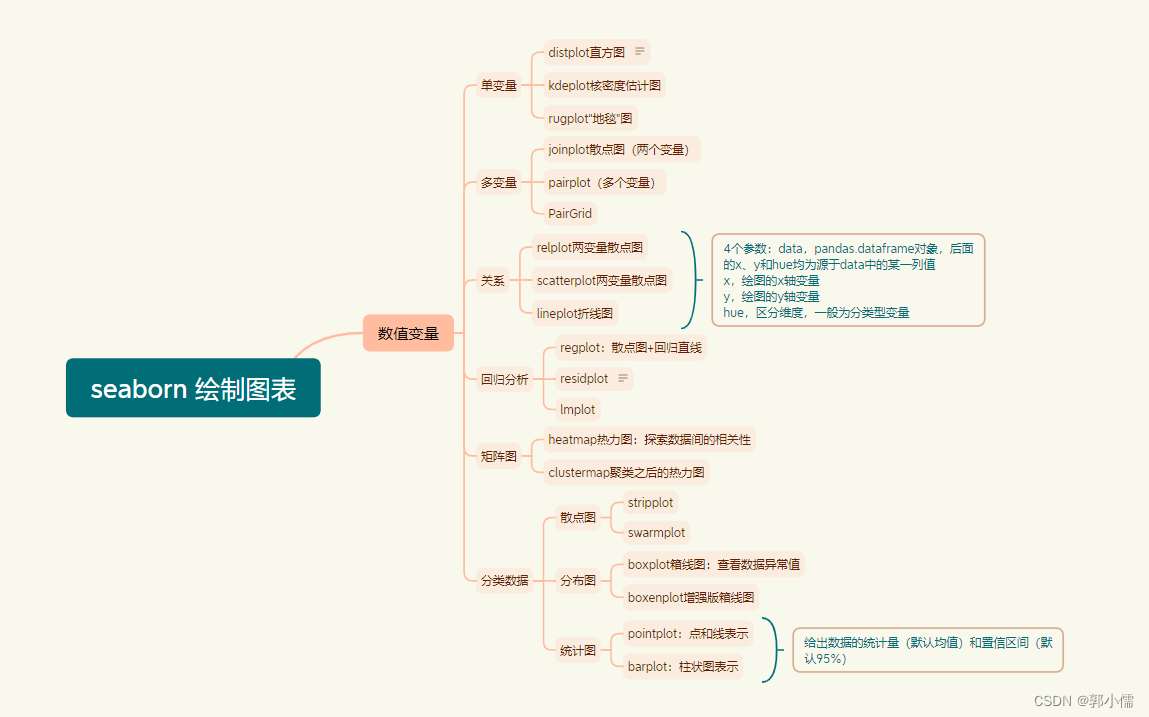
参考链接:seaborn
DataFrame.corr() 相关系数函数
- 干啥的: 计算DataFrame列之间的相关系数
- 举个例子:
a = np.arange(1,10).reshape(3,3)
data = DataFrame(a,index=["a","b","c"],columns=["one","two","three"])
print(data)
'''
one two three
a 1 2 3
b 4 5 6
c 7 8 9
'''
#计算第一列和第二列的相关系数
print(data.one.corr(data.two))
#1.0
#返回一个相关系数矩阵
print(data.corr())
'''
one two three
one 1.0 1.0 1.0
two 1.0 1.0 1.0
three 1.0 1.0 1.0
'''
#计算第一列和第二列的协方差
print(data.one.cov(data.two))
#9.0
#返回一个协方差矩阵
print(data.cov())
'''
one two three
one 9.0 9.0 9.0
two 9.0 9.0 9.0
three 9.0 9.0 9.0
'''
- 参数:
- method:计算相关性的方法,包括’pearson’(默认)、‘kendall’和’spearman’。这三个方法分别对应着皮尔逊相关系数、肯德尔相关系数和斯皮尔曼相关系数。
- min_periods:计算相关性时的最小样本量。
- dropna:布尔类型的参数,设置是否在计算相关性时忽略缺失值。默认为True,即忽略缺失值。
- 皮尔逊相关系数: 连续性变量才可采用,连续数据,正态分布,线性关系,用pearson相关系数是最恰当。
- 斯皮尔曼相关系数: 秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据。不满足连续数据,正态分布,线性关系,用spearman相关系数是最恰,当两个定序测量数据之间也用spearman相关系数。

参考链接:1111、2222


matplotlib库
专门写一篇吧:等一下下
导入数据:写一个read_data()函数
def read_data(data_path: str, filter_data: str = None) -> pd.DataFrame:
"""Reads a .csv file."""
df = pd.read_csv(data_path)
if filter_data is not None:
log(INFO, f"Reading {filter_data}'s data...")
df = df.loc[df['District'] == filter_data]
df.set_index(pd.DatetimeIndex(df["time"]), inplace=True)
df.drop(["time"], axis=1, inplace=True)
cols = [col for col in df.columns if col != "District"]
df[cols] = df[cols].astype("float32")
return df
学到了什么?
- pandas.read_csv()
- 使用pandas中的read_csv函数从指定路径(data_path)读取一个.csv文件,并将其存储在名为df的DataFrame对象中。
- df.loc()
- 通过行标签取值
- df = df.loc[df[‘District’] == filter_data]
- 这一行将会过滤DataFrame df,只保留’District’列等于filter_data的行。
- pandas.DatetimeIndex()
- 直接生成时间戳索引
-
例子:
idx = pd.DatetimeIndex([“1/1/2020 10:00:00+00:00”, “2/1/2020 11:00:00+00:00”])
idx
DatetimeIndex([‘2020-01-01 10:00:00+00:00’, ‘2020-02-01 11:00:00+00:00’],
dtype=‘datetime64[ns, UTC]’, freq=None)
- df.set_index()

- df.drop([“time”], axis=1, inplace=True)
- 这一行删除了名为"time"的列,axis=1表示删除列,inplace=True表示在原始DataFrame上进行修改。
- cols = [col for col in df.columns if col != “District”]
- 这一行创建了一个列表cols,其中包含了除了"District"之外的所有列名。
时间滞后 time lag
- 将某个时间点上的数据向后推移若干个时间单位。
def generate_time_lags(df: pd.DataFrame,
n_lags: int = 10,
identifier: str = "District",
is_y: bool = False) -> pd.DataFrame:
"""Transforms a dataframe to time lags using the shift method.
If the shifting operation concerns the targets, then lags removal is applied, i.e., only the measurements that
we try to predict are kept in the dataframe. If the shifting operation concerns the previous time steps (our actual
input), then measurements removal is applied, i.e., the measurements in the first lag are being removed since they
are the targets that we try to predict."""
columns = list(df.columns)
dfs = []
for area in df[identifier].unique():
df_area = df.loc[df[identifier] == area]
df_n = df_area.copy()
for n in range(1, n_lags + 1):
for col in columns:
if col == "time" or col == identifier:
continue
df_n[f"{col}_lag-{n}"] = df_n[col].shift(n).replace(np.NaN, 0).astype("float64")
df_n = df_n.iloc[n_lags:]
dfs.append(df_n)
df = pd.concat(dfs, ignore_index=False)
if is_y:
df = df[columns]
else:
if identifier in columns:
columns.remove(identifier)
df = df.loc[:, ~df.columns.isin(columns)]
df = df[df.columns[::-1]] # reverse order, e.g. lag-1, lag-2 to lag-2, lag-1.
return df
学到了什么?
- unique()
- unique()函数用于获取Series对象的唯一值。唯一性按出现顺序返回。
- 语法:Series.unique(self)
- 返回:ndarray 或 ExtensionArray作为 NumPy 数组返回的唯一值。
- 不能用于DataFrame
Python格式化输出format
- ‘{xxxx}’.format(变量)
>>>'{:.2f}'.format(0.4444) #保留小数点后两位
'0.44'
>>>'{value:.2f}'.format(value=0.6666)
'0.67'
>>>'{:.4%}'.format(0.33333) #百分比格式,并保留四位小数
'33.3330%'
>>>print('{0:x}'.format(1000) ) # 转换成十六进制
>>>print('{0:o}'.format(9876) ) # 转换成八进制
>>>print('{0:b}'.format(7878) ) # 转换成二进制
3e8
23224
1111011000110
>>>print("{:>10}".format(123)) # >代表右对齐,长度为10
123
>>>print("{:=>10}".format(123)) # >代表右对齐,长度为10,不够时===填充
=======123
>>>print("{:=<20}".format(123)) # <代表左对齐,长度为20,不够时===填充
123=================
>>>print("{:-^20}".format(123)) # ^代表剧中对齐,长度为20,不够时--填充
--------123---------
>>>print("{:-^20,}".format(100000)) # ^代表剧中对齐,长度为20,不够时--填充, ,(英文状态下)代表千为分隔符
------100,000-------
参考:不错
argparse模块
- 是什么? python的命令行解析的标准模块,内置于python,不需要安装。这个库可以让我们直接在命令行中就可以向程序中传入参数并让程序运行。来源:添加链接描述
- 通常的用法:
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--dataset_name", type=str, default="assist2015")
parser.add_argument("--model_name", type=str, default="saint")
parser.add_argument("--emb_type", type=str, default="qid")
parser.add_argument("--save_dir", type=str, default="saved_model")
# parser.add_argument("--learning_rate", type=float, default=1e-5)
parser.add_argument("--seed", type=int, default=42)
parser.add_argument("--fold", type=int, default=0)
parser.add_argument("--dropout", type=float, default=0.2)
parser.add_argument("--emb_size", type=int, default=256)
parser.add_argument("--learning_rate", type=float, default=1e-3)
parser.add_argument("--num_attn_heads", type=int, default=8)
parser.add_argument("--n_blocks", type=int, default=4)
parser.add_argument("--use_wandb", type=int, default=1)
parser.add_argument("--add_uuid", type=int, default=1)
args = parser.parse_args()
params = vars(args)
main(params)
其中vars()函数回对象object的属性和属性值的字典对象
说白了就是把他变成一个字典
那为什么不直接写一个字典呢?字典的写法还简单
- 字典写法:
config = Namespace(
project_name = 'test',
batch_size = 512,
hidden_layer_width = 64,
dropout_p = 0.1,
lr = 1e-4,
optim_type = 'Adam',
epochs = 15,
ckpt_path = 'checkpoint.pt'
)
- 实际写法:
添加链接描述
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











