







盘点自训练数据集如何打标签!
一、打标签规则
二、推荐工具
使用心得
前言
分享我在训练自己的数据集前期所碰到的一些问题,希望大家能及时避雷!
一、打标签规则
由于我使用YOLOv5模型,查询官方建议以及网上各路大神总结的经验打标签规则我总结了如下几点:
1、标签一一对应,每个数据集的标签标号要一致不然会混淆(例如person:0;clothes:5;要保证训练集中的标签标号都是一致的)。
2、贴边规则 :标注框需紧贴目标物体的边缘进行画框标注,不可框小或框大。
3、目标被遮挡也要标注,小目标也要标注,人眼可分辨的都需要标注。
4、人眼难以分辨的不要标。
5、重叠规则:当两个目标物体有重叠的时候,只要不是遮挡超过一半的就可以框的(遮挡范围需要根据算法识别情况制定),允许两个框有重叠的部分。如果其中一个物体挡住另一个物体一部分,框的时候就需要对另一个物体的形状进行脑补完整然后框起来即可。
6、独立规则:每一个目标物体均需要单独标框,比如:图中有三瓶水不能只标一个框,而是要将三个目标分别标框。
7、不框规则:图像模糊不清的不框,太暗和曝光过度的不框,不符合项目特殊规则的不框。
8、边界检查:确保框坐标不在图像边界上,防止载入数据或者数据扩展过程出现越界报错。
9、小目标规则:不同的算法对小目标的检测效果不同,对于小目标只要人眼能分清,都应该标出来。根据算法的需求,去决定是否启用这些样本参与训练。
10、小于10X10或者20X20像素的目标不方便标记可以忽略。
11、对与边界模糊、连片处理,标为一个样本框。
12、对于模糊、遮挡、有拖影的样本 最好单独建立样本库,有选择的启用。
13、宽高比 极端不是好样本。
二、推荐工具
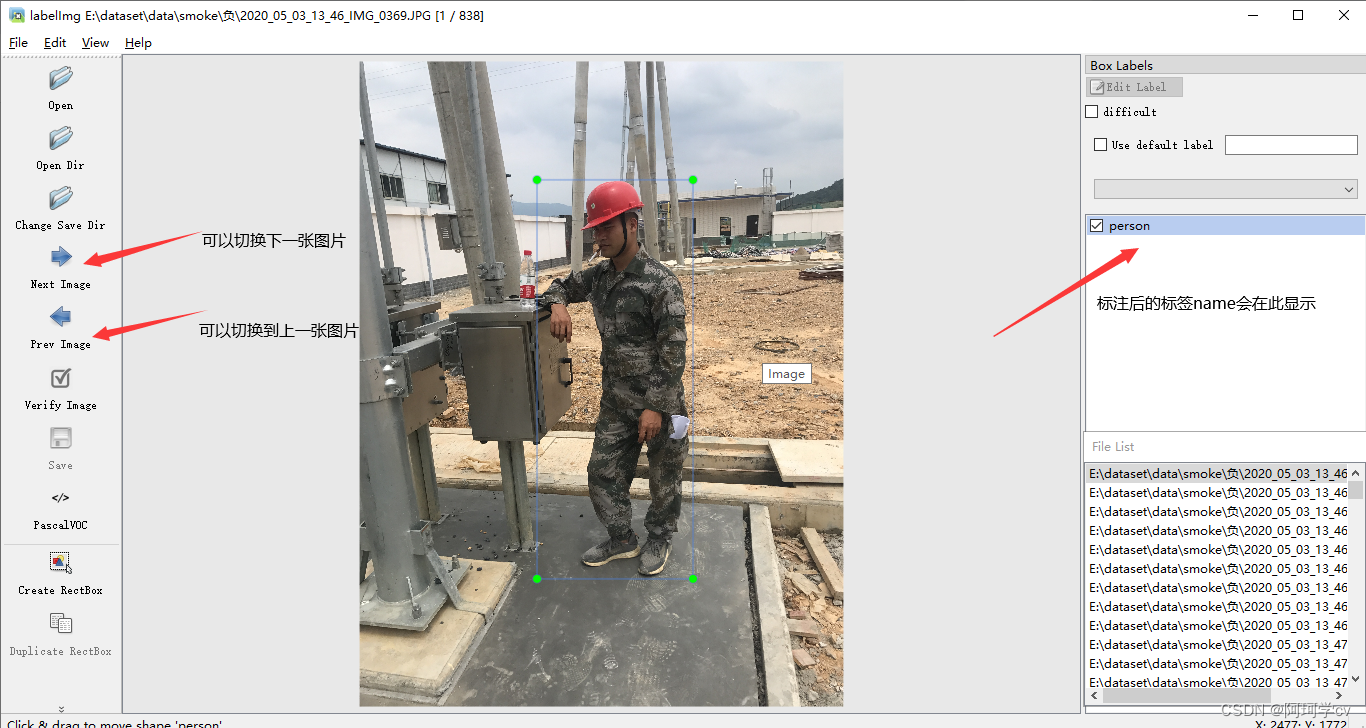
1.labelimg
主页面

open dir 打开待标注的图片文件夹
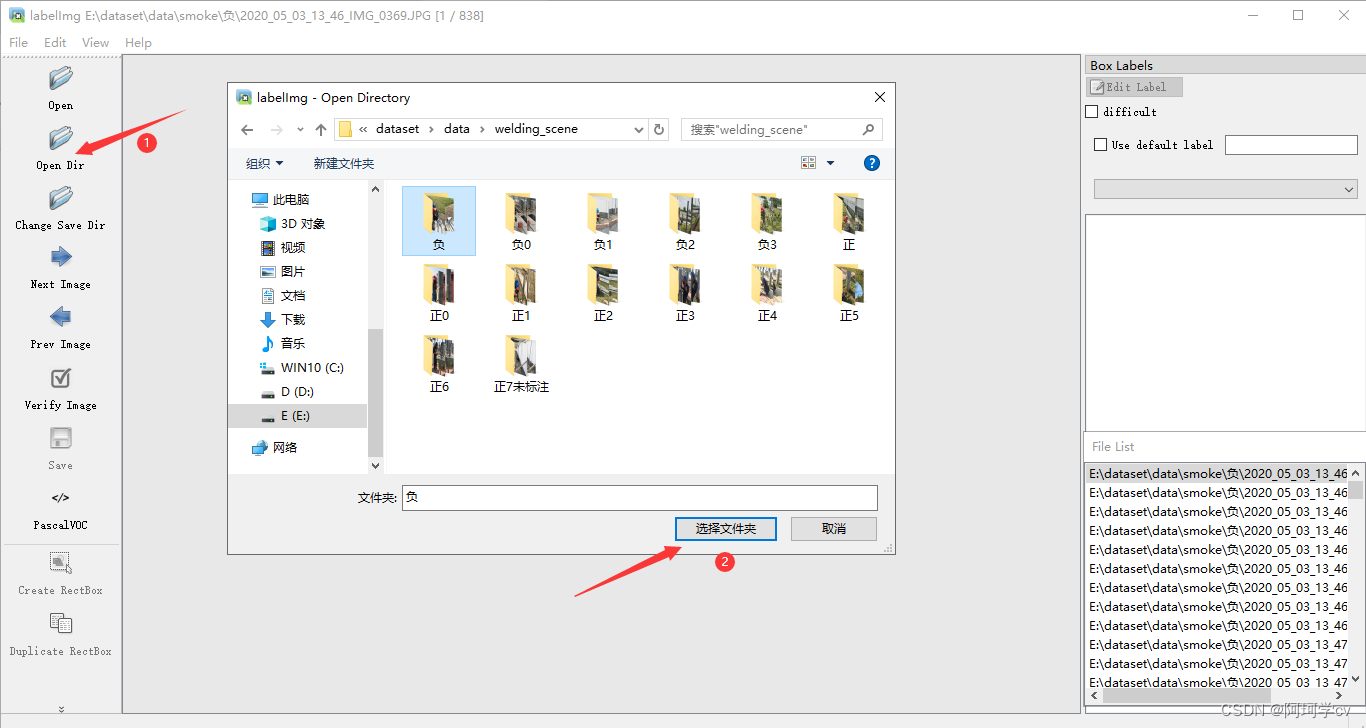
change save dir 选择保存标签数据的文件夹
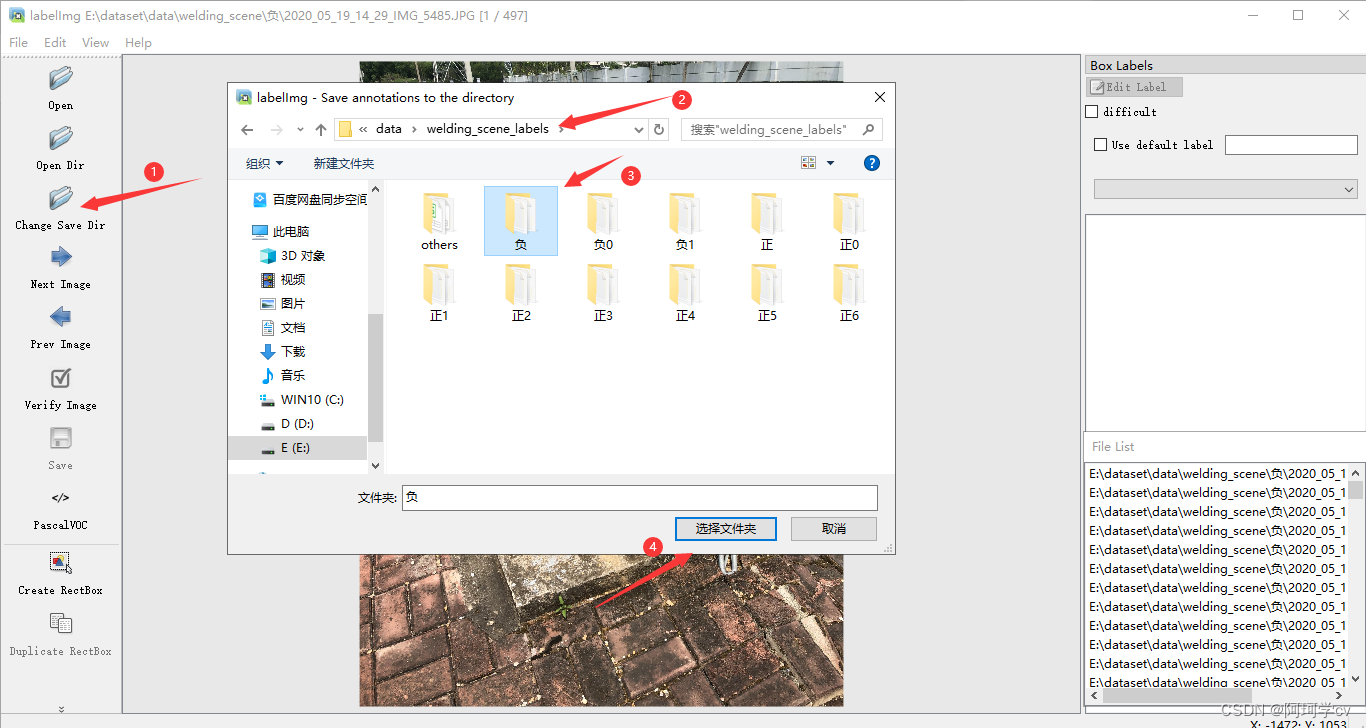
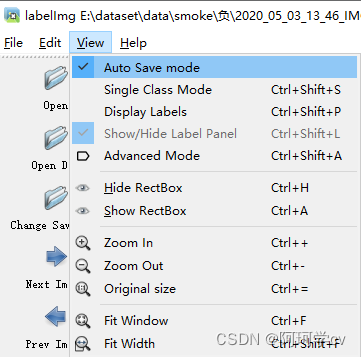
打开自动保存功能,可以在选择的save dir中自动保存,无需手动save
create rectbox 画矩形框,打标签名
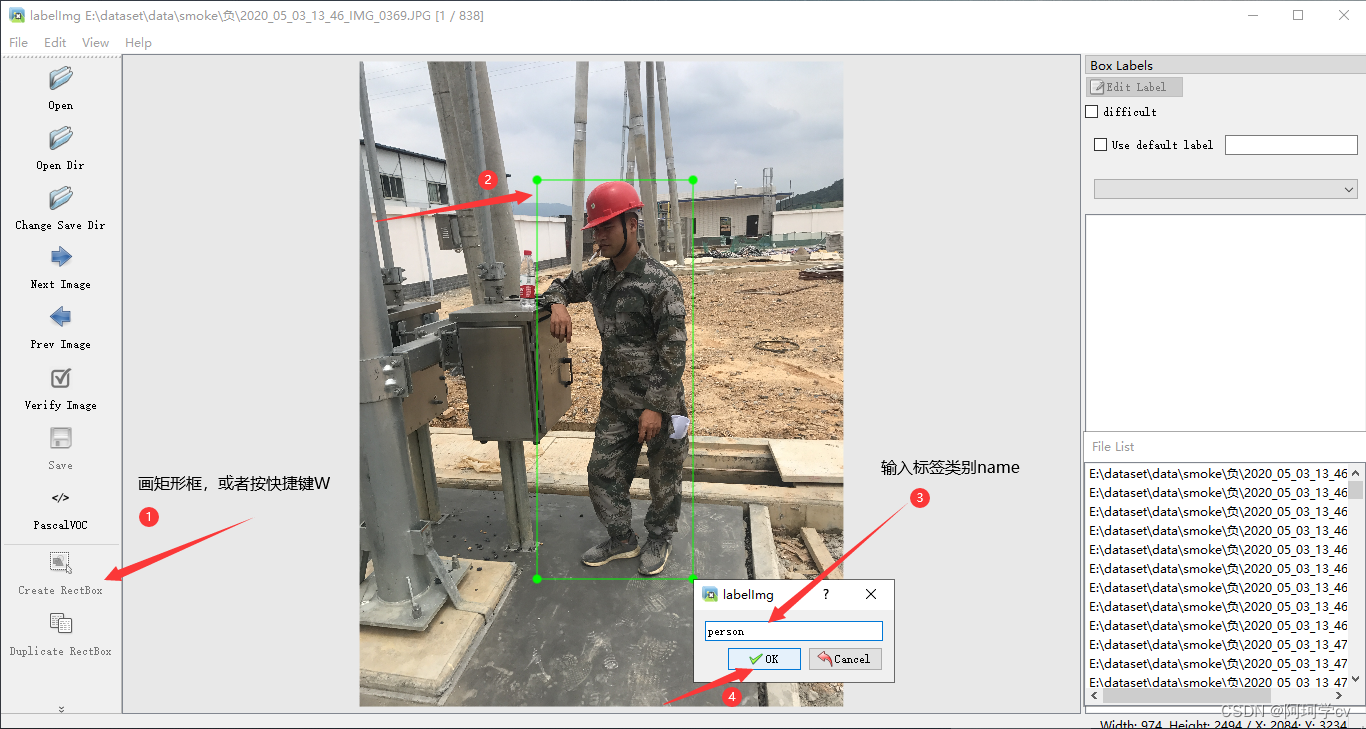
至此一张图片就标注完了,可以通过以下操作切换列表中的图片
tips:xml标签格式转换为txt(转换脚本:🔗)。
优点:labelimg可以实时保存标签文件,也可以对修改后的标签信息实时更新到对应的txt标签文档,若不小心关闭窗口,也不会影响之前的工作量。
缺点:操作过于依赖用户,个人觉得对于工作量大的朋友很耗时。
由于我的工作量很大,对此我比较喜欢makesense.ai在线标注网站,主要是方便。
2.makesense.ai
S1 :主页面点击右下角的Get Started进入

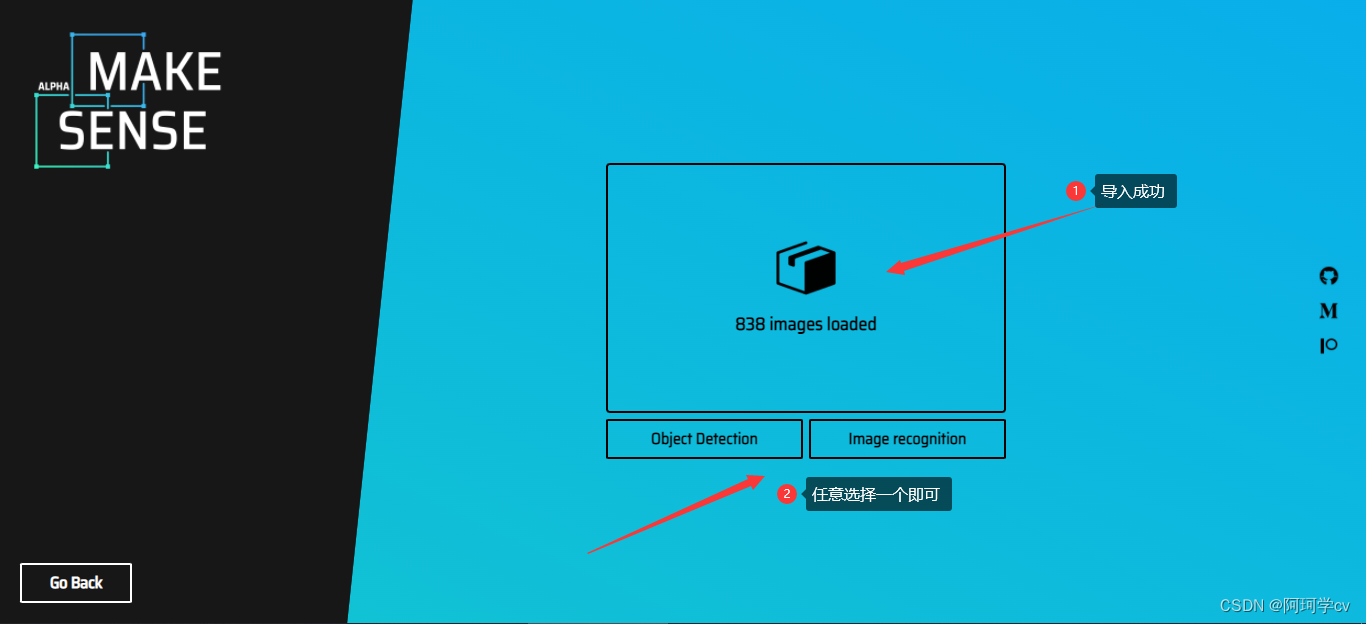
S2:导入标注图片

S3:定义标签名称及顺序
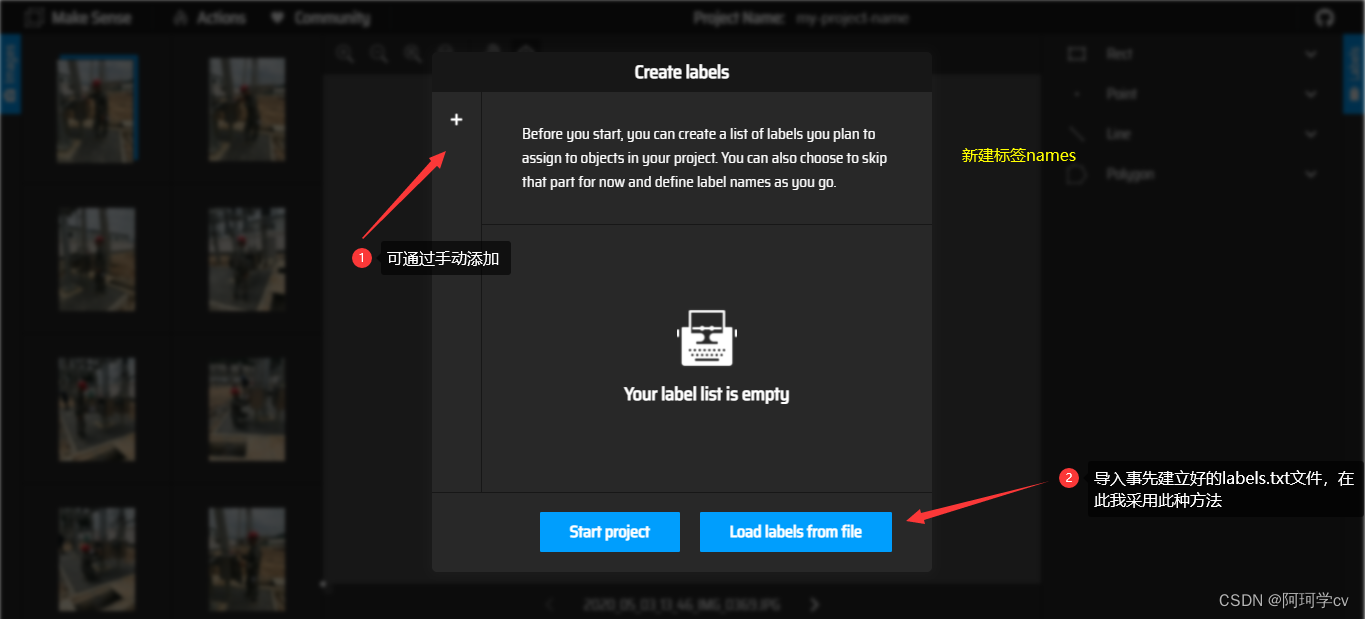
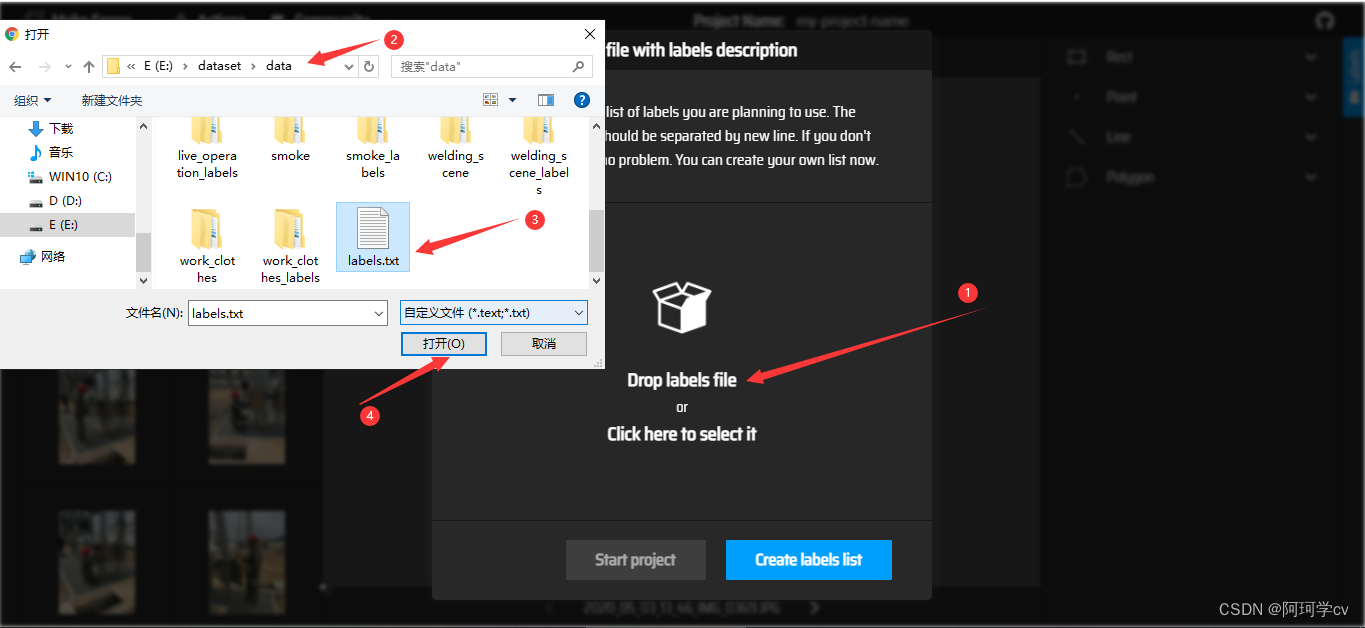
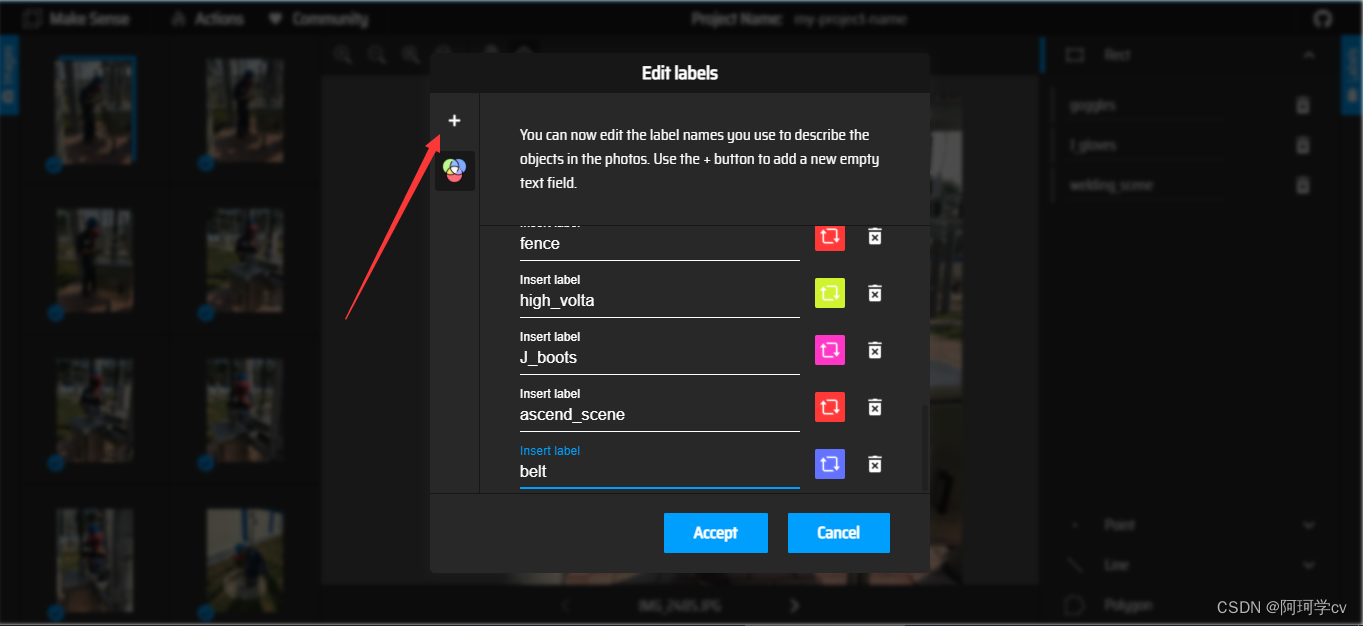
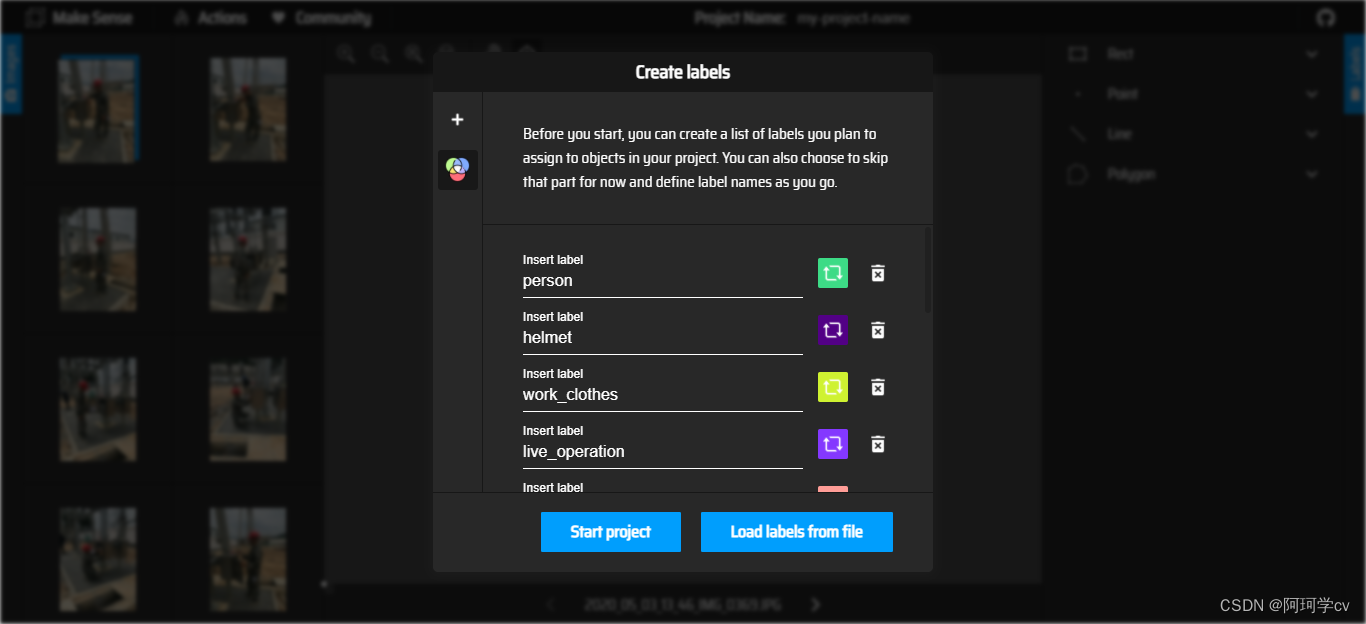 以上界面就表示标签建立完毕,无论是哪种方式都可得到同样的效果,可以发现在此窗口我们可以更换标签颜色,删除标签,如需调换前后顺序,只能手动更改,也不能中间插入。
以上界面就表示标签建立完毕,无论是哪种方式都可得到同样的效果,可以发现在此窗口我们可以更换标签颜色,删除标签,如需调换前后顺序,只能手动更改,也不能中间插入。
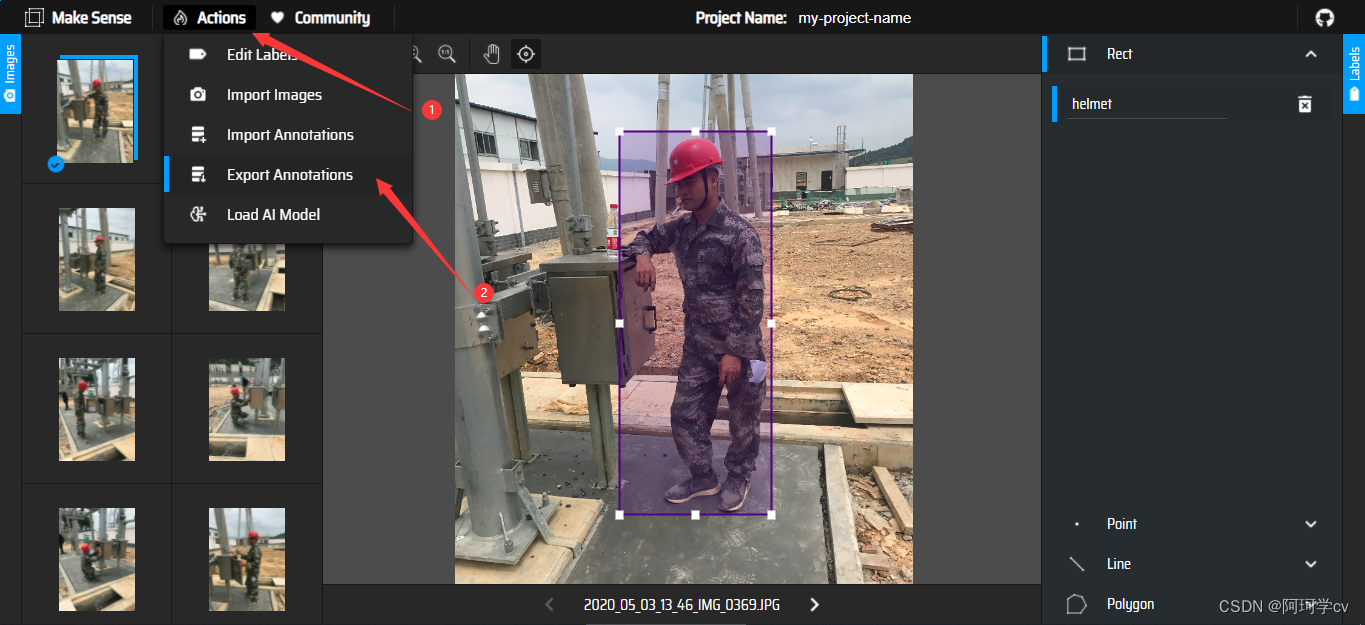
S4:打标签
S5:导出标签数据
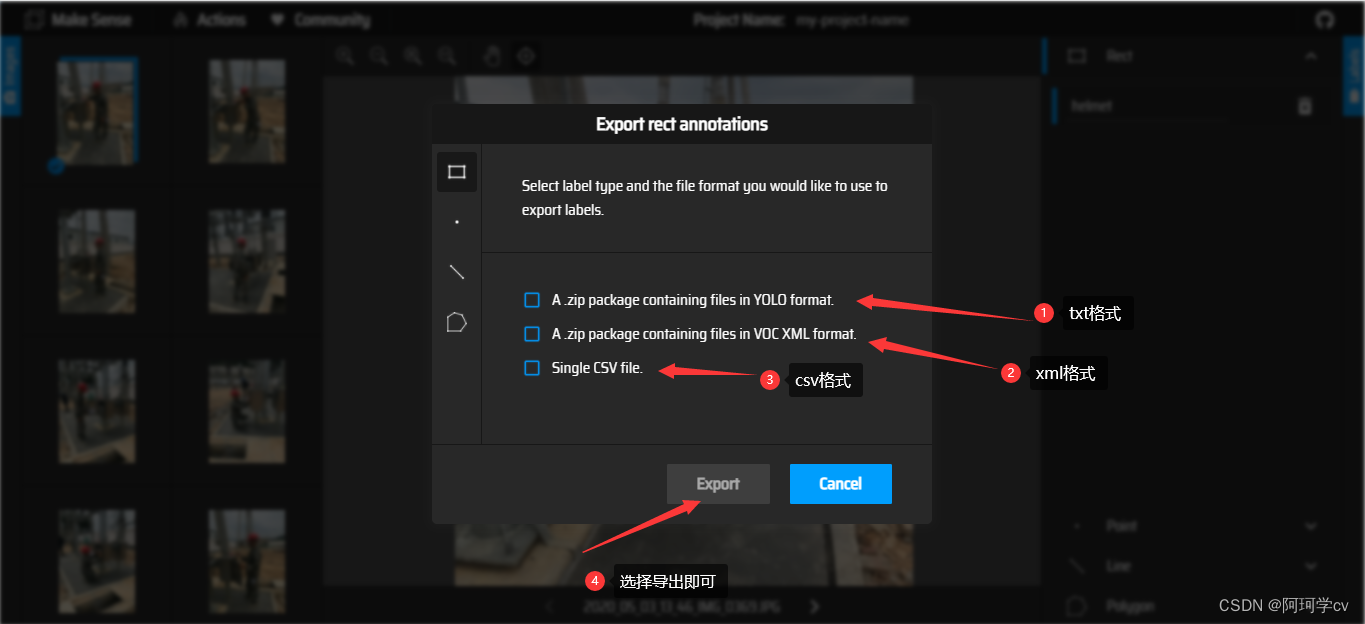
注意:1、建议大家打完标签后请立即导出数据,因为这是在线网站,谁也不知道下一秒会不会卡顿,我曾气到吐血,一天的工作量结束因为卡顿没有及时导出数据而gameover(这也是为什么我们导入图像数据时能瞬间上传上千张样本的原因,它不会为我们存储任何数据),且把三个格式都导出,以防我们后续需要更改标签顺序时我们可以依赖xml文件,而txt文件我们是无能为力的。
2、建议样本超过500张以上的分批次标注
S6:在原有标注基础上继续打标签(导入已有的标签文件以及 labels.txt 文本文档)
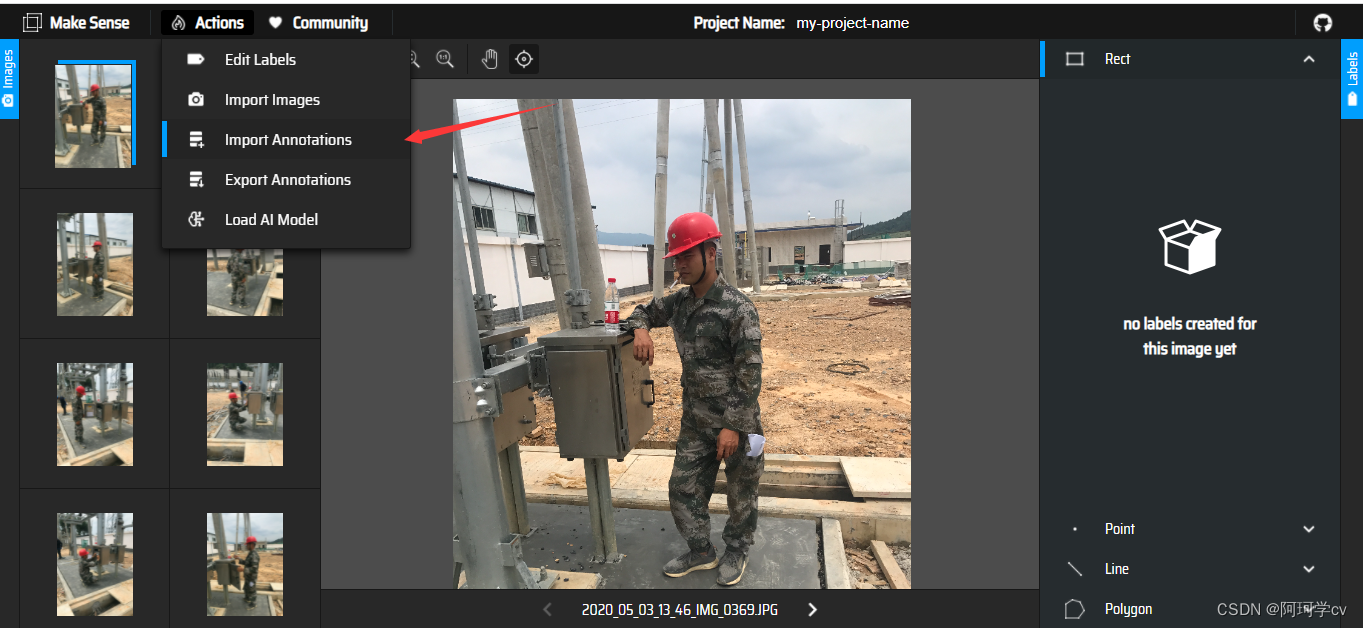
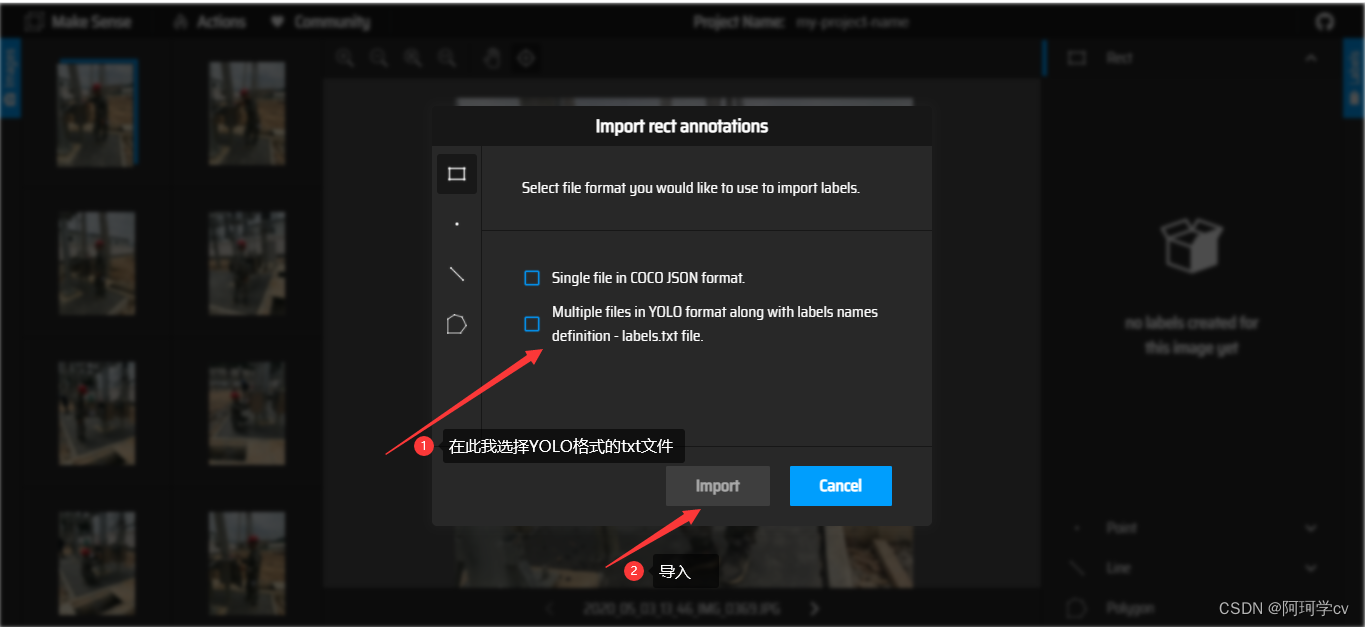
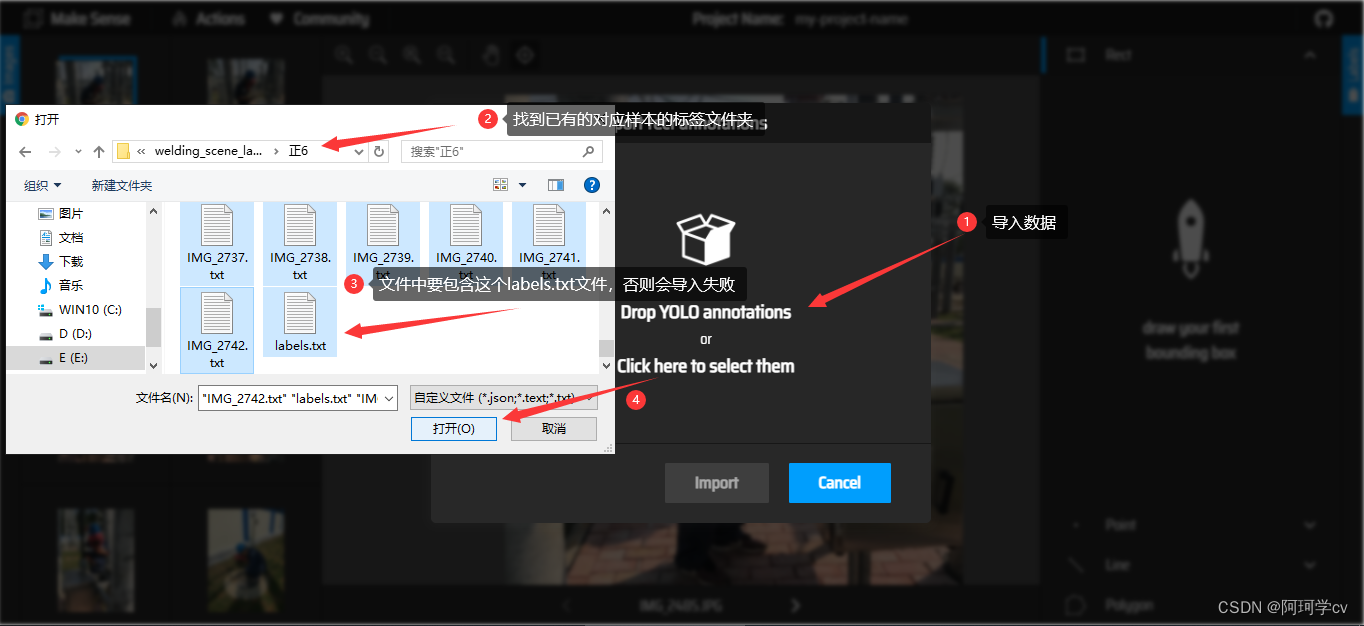
注意:此过程需要等待一会,因为你会发现import按钮无法选中,等到可以选中的时候就表示已经导入成功了。(这也是为什么我建议分批次打标注)
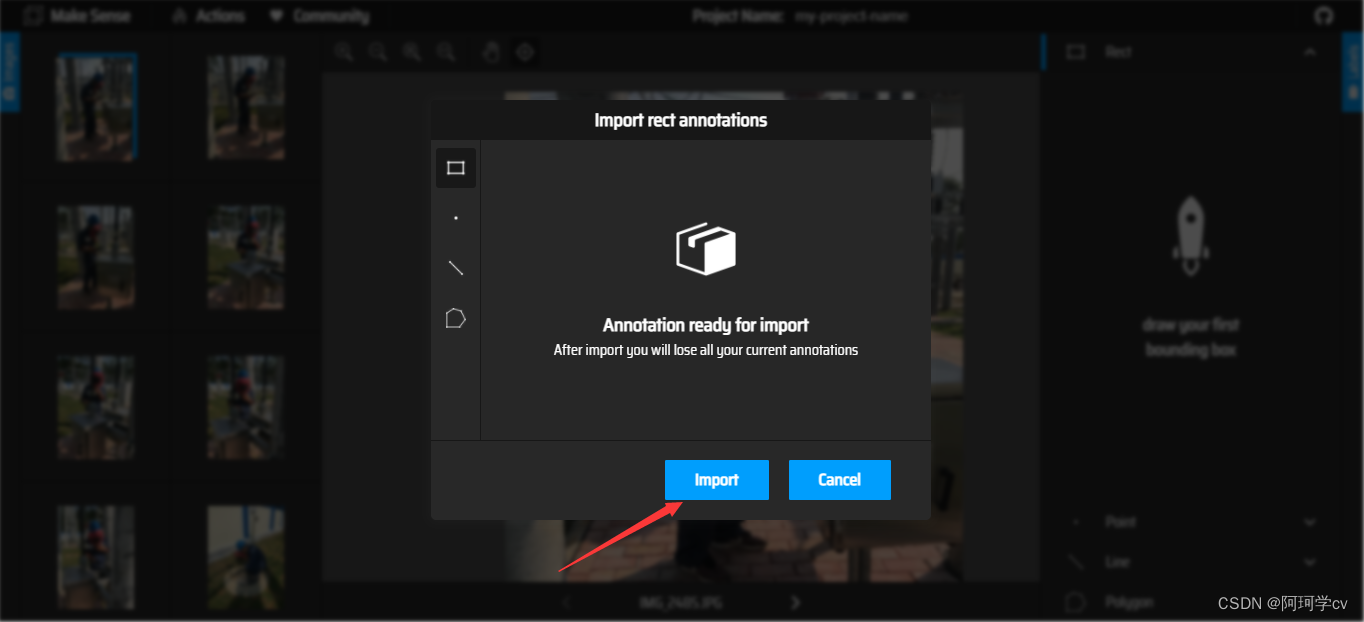
此页面表示我们成功导入了已有标签数据,确认进入后,我们可以看到已打过的标注框已经显示了。
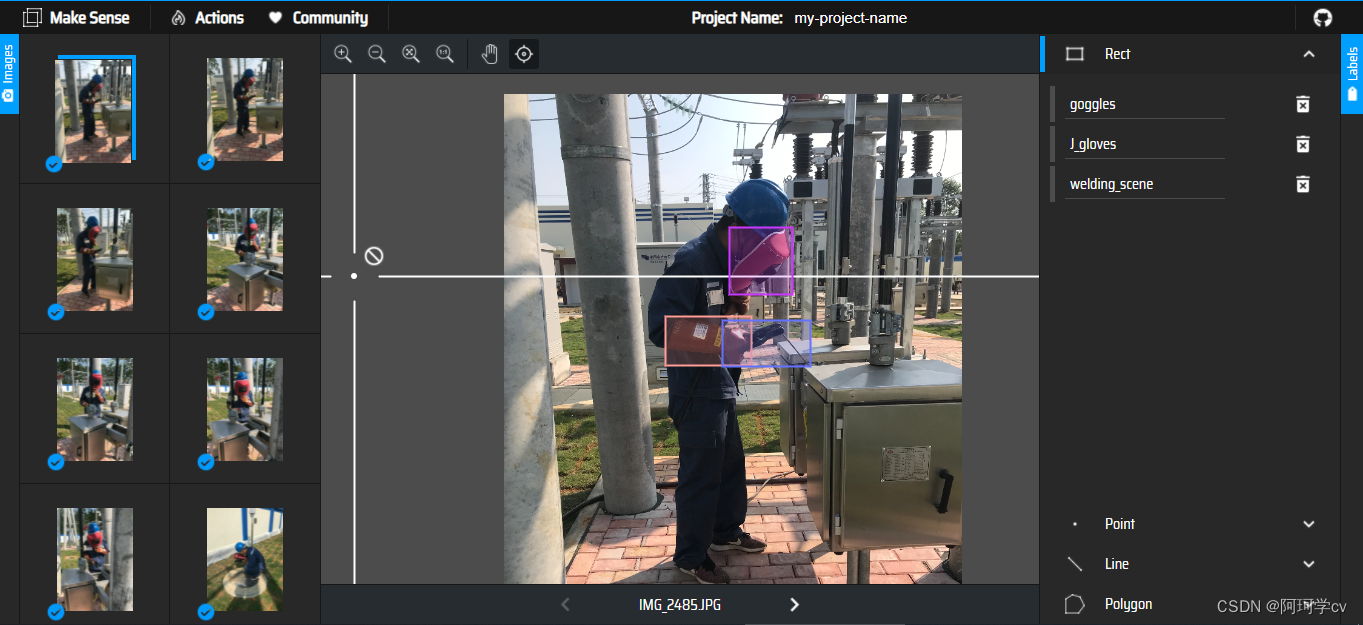
在此基础上我们可以继续标注新的类别,注意,若是新增的标注类别没有在labels.txt文件中包含,我们可以新增标签类别,但是只能在原有的names顺序之后新增,不能插入到某个标签顺序之后,我暂时还没找到合理的解决办法,可能xml文件可以解决这个问题??还未尝试(如果有小伙伴知道请告诉我一下,我快被折磨疯了)

使用心得
labelimg没啥风险,即使不小心退出了,但是它有实时保存的功能,不担心因为没有及时保存而白干!!
虽然makesense有点风险,可能会白干,但是我个人还是喜欢makesense的,只要做好分批次打标注,及时导出数据,一般很少出现卡顿情况,我出现的那次可能是电脑太老了???
强烈建议大家都尝试后再做选择!!
第一次写文分享,不当之处请大家及时指出,若有什么使用建议可以给我留言!
❤笔芯

















 2077
2077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









