







 本文详细介绍了拉普拉斯金字塔在图像超分辨率(SR)中的应用,特别是LapSRN网络结构。它通过下采样与残差重建来解决图像细节丢失问题,涉及特征提取与图像重建两阶段。模型设计旨在降低计算复杂度并提高图像恢复精度。
本文详细介绍了拉普拉斯金字塔在图像超分辨率(SR)中的应用,特别是LapSRN网络结构。它通过下采样与残差重建来解决图像细节丢失问题,涉及特征提取与图像重建两阶段。模型设计旨在降低计算复杂度并提高图像恢复精度。
拉普拉斯金字塔(Laplacian Pyramid)
拉普拉斯金字塔的目的是解决图像下采样后高频信息丢失的问题。拉普拉斯金字塔保存了下采样图像和原图像之间的差分图像(其实就是残差的概念,对原始图像做下采样,并保存采样后图像与原图像之间的残差)。这样就可以通过低分辨图像和残差恢复出高分辨图像。图示如下:
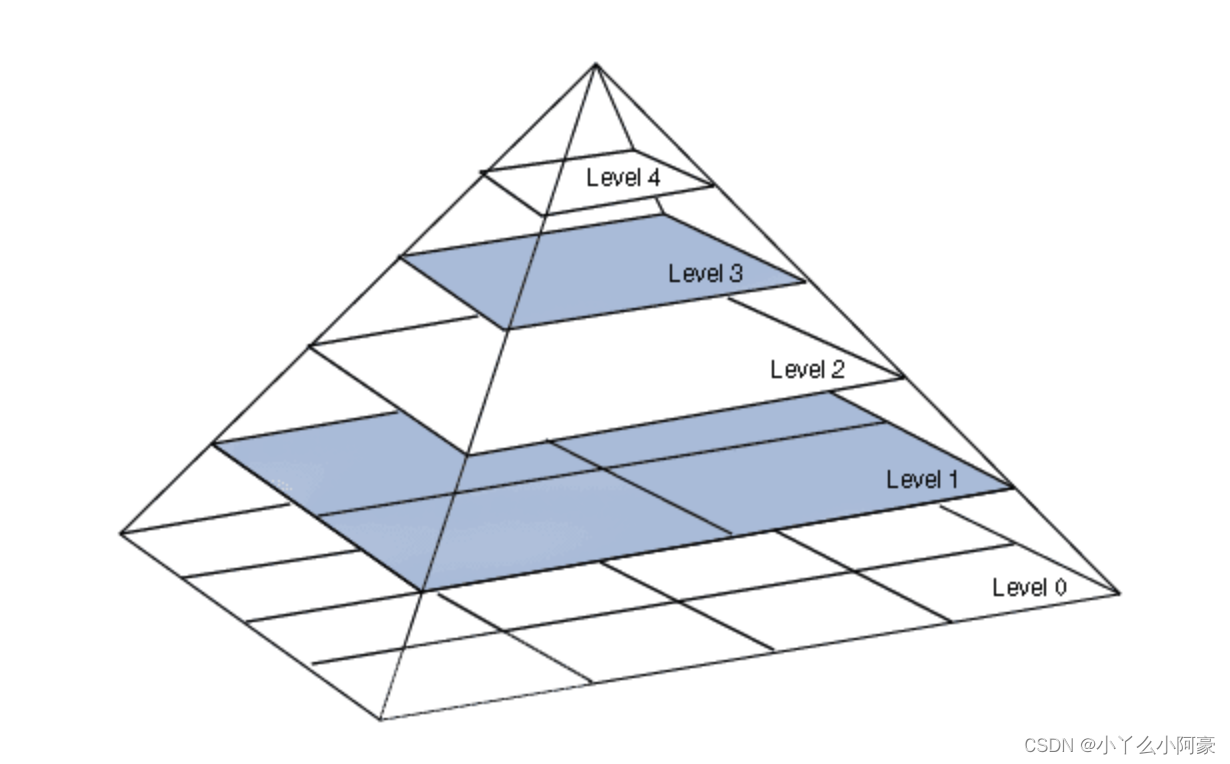

图片来源:https://www.jianshu.com/p/e3570a9216a6
LapSRN网络结构
论文链接:
Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution
Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks
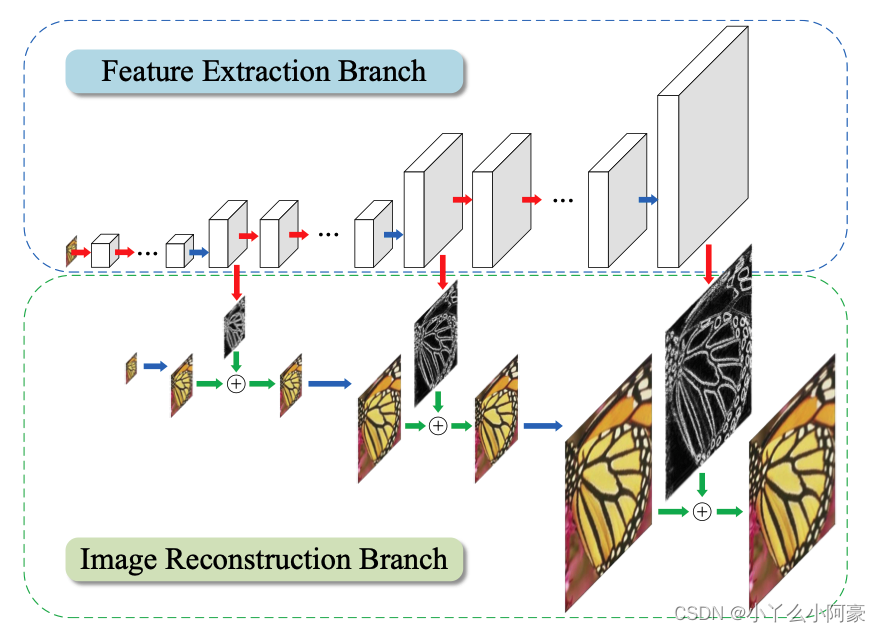
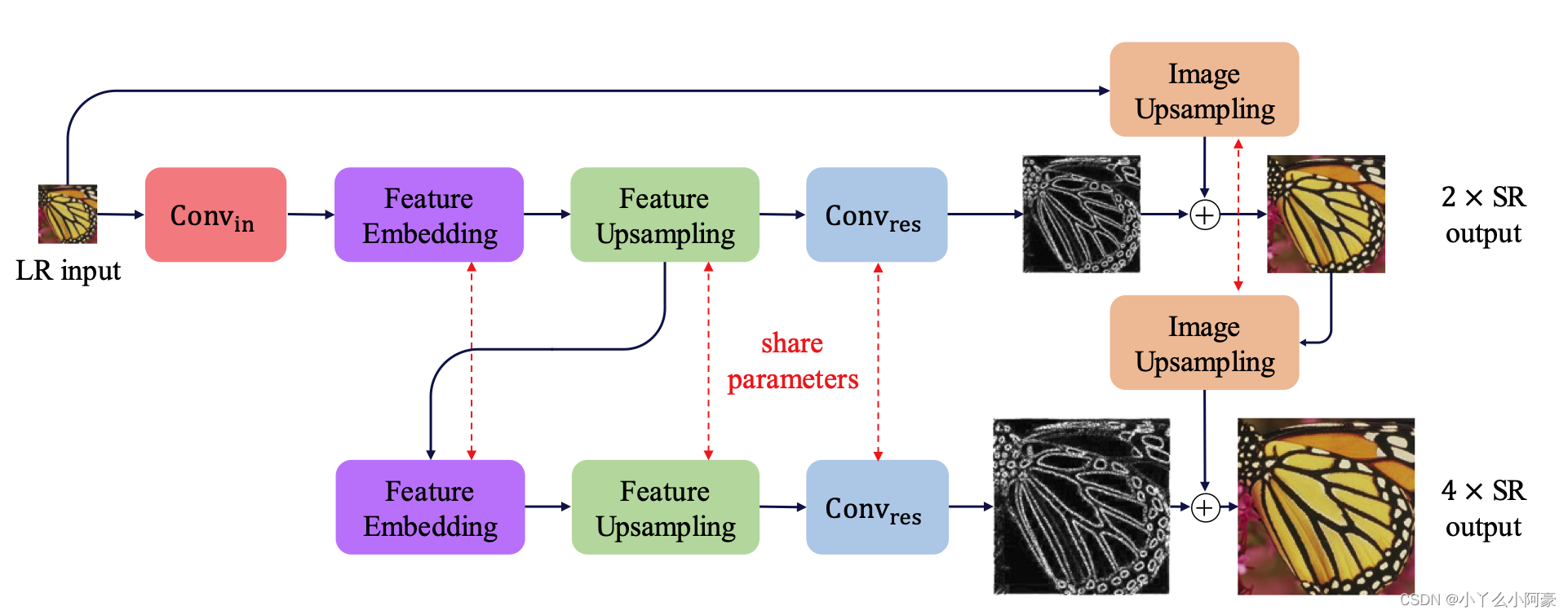
模型深度是由放大倍数决定的,其关系是
l
o
g
2
S
log_2S
log2S,S是放大倍数。(这个很好理解,因为每个progress放大2倍,放大S倍就需要做
l
o
g
2
S
log_2S
log2S次操作。每一次操作分为两个部分:特征提取和图像重建
特征提取(Feature Extraction):在第S level,特征提取由d个卷积层和一个2倍上采样转置卷积层组成。卷积层连接到两个层上:(1)一个在第S level重建残差图像的卷积层(2)一个在第S+1 level提取特征的卷积层
图像重建(Image Reconstruction):在第S level,输入图像通过一个转置卷积层上采样扩大2倍(如:2x2 -> 4x4),转置卷积层的kernal为biliner kernal,该层和其他层一起训练优化。而后上采样图像和预测的残差结合(using element-wise summation 即逐元素相加)生成高分辨图像。S level产生的高分辨图像(HR)输入到第S + 1层。
原文:
We propose to construct our network based on the Laplacian pyramid framework, as shown in Figure 1(e). Our model takes an LR image as input (rather than an upscaled version of the LR image) and progressively predicts residual images at log2 S levels where S is the scale factor. For example, the network consists of 3 sub-networks for super- resolving an LR image at a scale factor of 8. Our model has two branches: (1) feature extraction and (2) image reconstruction.
Feature extraction. At level s, the feature extraction branch consists of d convolutional layers and one transposed convolutional layer to upsample the extracted features by a scale of 2. The output of each transposed convolutional layer is connected to two different layers: (1) a convolutional layer for reconstructing a residual image at level s, and (2) a convolutional layer for extracting features at the finer level s + 1. Note that we perform the feature extraction at the coarse resolution and generate feature maps at the finer resolution with only one transposed convolutional layer. In contrast to existing networks that perform all feature extraction and reconstruction at the fine resolution, our network design significantly reduces the computational complexity. Note that the feature representations at lower levels are shared with higher levels, and thus can increase the non-linearity of the network to learn complex mappings at the finer levels.
Image reconstruction. At level s, the input image is up- sampled by a scale of 2 with a transposed convolutional (upsampling) layer. We initialize this layer with the bilinear kernel and allow it to be jointly optimized with all the other layers. The upsampled image is then combined (using element-wise summation) with the predicted residual image from the feature extraction branch to produce a high-resolution output image. The output HR image at level s is then fed into the image reconstruction branch of level s + 1. The entire network is a cascade of CNNs with a similar structure at each level.


















 1665
1665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











