









LDM 实现三维超分辨率~
论文:InverseSR: 3D Brain MRI Super-Resolution Using a Latent Diffusion Model
代码:https://github.com/BioMedAI-UCSC/InverseSR
0、摘要
从研究级医疗机构获得的高分辨率(HR)MRI 扫描能够提供关于成像组织的精确信息。然而,常规临床 MRI 扫描通常为低分辨率(LR),并且由于扫描参数根据医疗机构的本地需求进行调整,其对比度和空间分辨率存在很大差异。(提出实际问题)
针对 MRI 超分辨率(SR)的端到端深度学习方法已经有所提出,但这些方法在输入分布发生变化时,每次都需要重新训练。(当前研究不足)
为解决这一问题,本文提出了一种新颖的方法,该方法利用了最先进的三维脑部生成模型——潜在扩散模型(LDM),该模型基于 UK BioBank 数据集进行训练,用于提升临床 MRI 扫描的分辨率。(本文研究目的)
LDM 作为生成先验,能够捕捉三维 T1 加权脑部 MRI 的先验分布。基于脑部 LDM 的架构,本文发现不同的 MRI SR 场景适合不同的方法,因此提出了两种新策略:
(1)对于稀疏性较高的 SR,通过 LDM 的解码器
D
\mathcal D
D 以及确定性去噪扩散隐式模型(DDIM)进行逆向操作,这种方法称为 InverseSR(LDM);
(2)对于稀疏性较低的 SR,仅通过 LDM 解码器
D
\mathcal D
D 进行逆向操作,这种方法称为 InverseSR(Decoder);
这两种方法在 LDM 模型中搜索不同的潜在空间,以找到将给定的低分辨率 MRI 映射到高分辨率的最佳潜在编码。生成模型的训练过程与 MRI 欠采样过程无关,确保了本文的方法能够广泛应用于具有不同输入测量的多种 MRI 超分辨率问题。
本文在来自 IXI 数据集的 100 多个脑部 T1 加权 MRI 上验证了该方法。实验结果表明,LDM 提供的强大先验可用于 MRI 重建。
1、引言
1.1、当前局限
(1)基于 CNN 的监督训练需要配对图像,这导致每次输入分布发生变化时都需要重新训练,在 MRI 超分辨率中,获取能够涵盖不同机构临床脑 MRI 扫描协议和分辨率变化的配对训练数据具有挑战性;
(2)通过生成模型构建图像先验最近成为图像超分辨率领域的一种流行方法,但目前仅限于 2D 切片;
1.2、本文贡献
(1)提出了一种解决 MRI 超分辨率问题的方法,通过 LDM 构建强大的三维原生图像先验;
(2)通过在预训练生成模型的潜在空间中找到最优潜在编码 z 来解决逆问题,这可以利用已知的退化函数
f
f
f 恢复给定的低分辨率 MRI 图像
I
I
I ;(云里雾里的…)
(3)提出了两种新策略:Inverse(LDM),它通过确定性的 DDIM 模型进一步逆转输入图像,以及 InverseSR(Decoder),它通过 LDM 模型的解码器
D
\mathcal D
D 和退化函数
f
f
f 逆转输入图像;
2、方法
2.1、3D 脑 LDM
利用最先进的 LDM 为 3D 脑部 MRI 创建高质量的先验。LDM 包含两个组成部分:自编码器和扩散模型。编码器 E \mathcal E E 将每个高分辨率 T1w 脑 MRI x ∼ p d a t a ( x ) x∼p_{data}(x) x∼pdata(x) 映射到大小为 20×28×20 的潜在向量 z 0 = E ( x ) z_0 = \mathcal E(x) z0=E(x)。解码器 D \mathcal D D 被训练成将潜在向量 z 0 z_0 z0 映射回 MRI 图像域 x x x。
使用 L1 损失、感知损失、基于 patch 的对抗性损失和潜在空间中的 KL 正则化项的损失组合,在 UK Biobank 上的 31740 个 T1w MRI 上对自编码器进行训练。自编码器在经过预处理的 MRI 图像上使用 UniRes 进行训练,这些图像被转换到一个具有 1mm³ 体素大小的共同 MNI 空间中,并且在 LDM 训练过程中保持不变。
使用 T1w 脑部 MRI 的潜在表示来训练 LDM,通过以下目标训练条件 U-Net
ϵ
θ
ϵ_θ
ϵθ 以预测噪声:
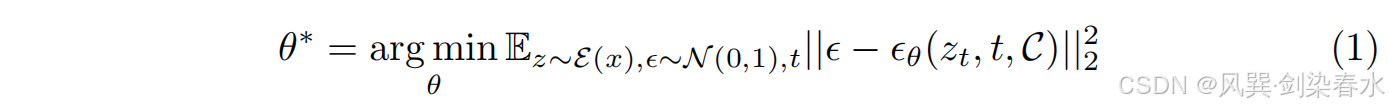
DDIM 已被用于脑部 LDM,以在推理过程中替代去噪扩散概率模型(DDPM),从而减少反向步骤的数量,同时将性能损失降至最低。
网络 ϵ θ ϵ_θ ϵθ 是基于四个条件变量 C \mathcal C C 进行条件化的:年龄、性别、脑室体积和脑体积,这些都是通过交叉注意力层引入 LDM。性别是一个二元变量,而其他协变量则缩放至 [ 0 , 1 ] [0,1] [0,1]。最后,预训练的解码器将潜在向量映射到高分辨率 MRI x ~ = D ( z 0 ) \widetilde x= \mathcal D(z_0) x =D(z0)。大脑 LDM 的架构如 图1 所示。
Figure 1 | 训练过程与 MRI SR 两种处理方法:(左)Brain LDM 有两阶段的训练过程;首先,自编码器被预训练,用于将 T1 加权脑部 MRI 映射到一个潜在编码
z
0
=
E
(
x
)
z_0 = \mathcal E(x)
z0=E(x),随后,扩散模型在潜空间中学习生成
z
0
z_0
z0,在推理过程中,DDIM 被用于减少采样步骤,同时保证性能下降很小。(右)基于脑部 LDM 的架构提出了两种处理 MRI SR 不同场景的方法:1) InverseSR(LDM):对于高稀疏度的 SR,使用确定性的 DDIM 和解码器
D
\mathcal D
D 优化潜在编码
z
T
∗
z_T^∗
zT∗ 及其相关的条件变量
C
∗
\mathcal C^*
C∗,将潜在编码映射到脑部 MRI;2) InverseSR(Decoder):对于低稀疏度的 SR,仅使用解码器
D
\mathcal D
D 优化
z
0
∗
z_0^∗
z0∗,将潜在编码映射到脑部 MRI;

2.2、确定性 DDIM 采样
为了获得能够将给定的噪声样本重建为高分辨率图像的潜在表示
z
T
z_T
zT,采用确定性的 DDIM 采样:
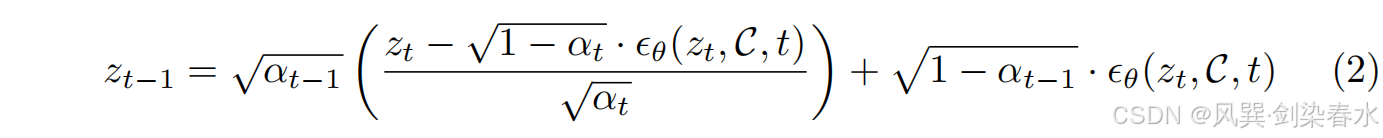
其中
α
1
:
T
∈
(
0
,
1
]
T
α_{1:T}∈(0,1]^T
α1:T∈(0,1]T 是一个随时间递减的序列,右边第一项表示 “预测的
x
0
x_0
x0”,第二项可以理解为“指向
x
t
x_t
xt 的方向”。
2.3、退化函数 f f f
假设存在一个已知的退化函数 f f f,它被应用于从生成模型中获得的高分辨率图像 x ~ \widetilde x x ,并基于退化后的图像 f ∘ x ~ f∘\widetilde x f∘x 和给定的低分辨率输入图像 I I I 来计算损失函数。
在临床实践中,一种常见的获取 MRI 的方法是优先考虑高平面内分辨率,同时牺牲平面外分辨率,以加快成像过程并减少运动伪影。为了应对这一过程,本文引入了一个退化函数,该函数为未采集的切片生成掩模,从而使得本文的方法能够对缺失的切片进行填充。例如,在 1×1×4 mm³ 的欠采样体积中,本文在生成的高分辨率 1×1×1 mm³ 体积中,每四个切片中为三个切片创建掩模。
2.4、InverseSR(LDM)
在高稀疏性 MRI SR 的情况下,优化噪声潜在编码
z
T
∗
z_T^∗
zT∗ 及其相关条件变量
C
∗
\mathcal C^*
C∗,以使用以下优化方法从给定的 LR 输入图像
I
I
I 中恢复 HR 图像:
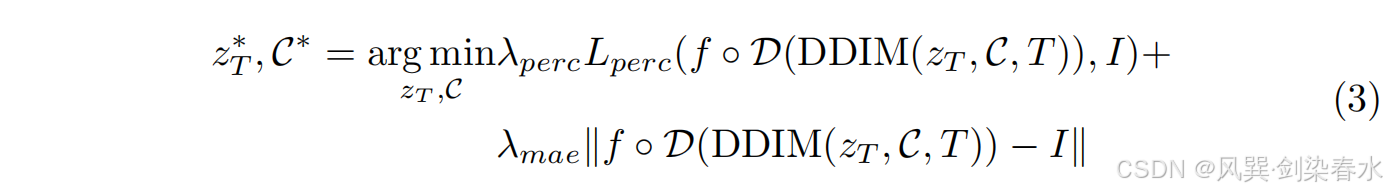
其中 DDIM
(
z
T
,
C
,
T
)
(z_T,C,T)
(zT,C,T) 表示在 公式2 中对潜在编码
z
0
z_0
z0 进行的
T
T
T 个确定性 DDIM 采样步骤。遵循脑 LDM 模型,使用感知损失
L
p
e
r
c
L_{perc}
Lperc 和
L
1
L1
L1 像素级损失。损失函数是在生成模型和给定LR输入生成的被破坏图像上计算的,该方法的详细伪代码描述见 算法1。

2.5、InverseSR(Decoder)
对于低稀疏性 MRI SR,直接使用解码器
D
\mathcal D
D 找到最优的潜在编码
z
T
∗
z_T^∗
zT∗:
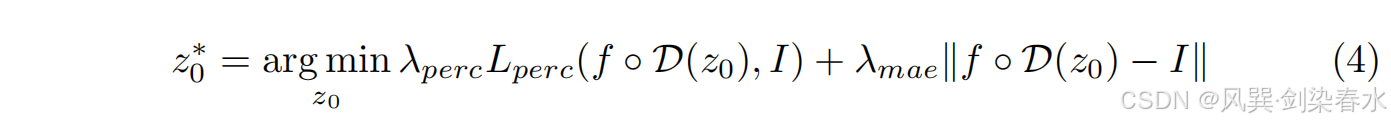
3、实验与结果
3.1、验证数据集
(1)IXI 数据集:100 个 HR T1 MRI来验证本文的方法;
3.2、实施细节
(1)条件变量均初始化为 0.5,所有输入体积中的体素均归一化为 [0,1];
(2)DDIM 采样,
T
=
46
T = 46
T=46;(这个设置挺神奇)
(3)InverseSR(LDM),
z
T
z_T
zT 用随机高斯噪声初始化;
(4)InverseSR(Decoder),从正态分布
N
(
0
,
I
)
\mathcal N(0,I)
N(0,I) 中采样 S=10,000 个
z
T
i
z_T^i
zTi 样本,然后将它们通过 DDIM 模型,计算平均潜在编码
z
ˉ
0
\bar z_0
zˉ0;
(5)在 InverseSR(LDM) 中使用了 600 步梯度下降,以确保收敛,InverseSR(Decoder) 中也使用了 600 步优化;
(6)使用 Adam 优化器,
α
=
0.07
α = 0.07
α=0.07,
β
1
=
0.9
β_1 = 0.9
β1=0.9 和
β
2
=
0.999
β_2 = 0.999
β2=0.999;
3.3、实验结果
Figure 2 | InverseSR 和 Cubic 、 UniRes 基线在厚度为 4 mm 和 8 mm 的扫描上的定性结果:
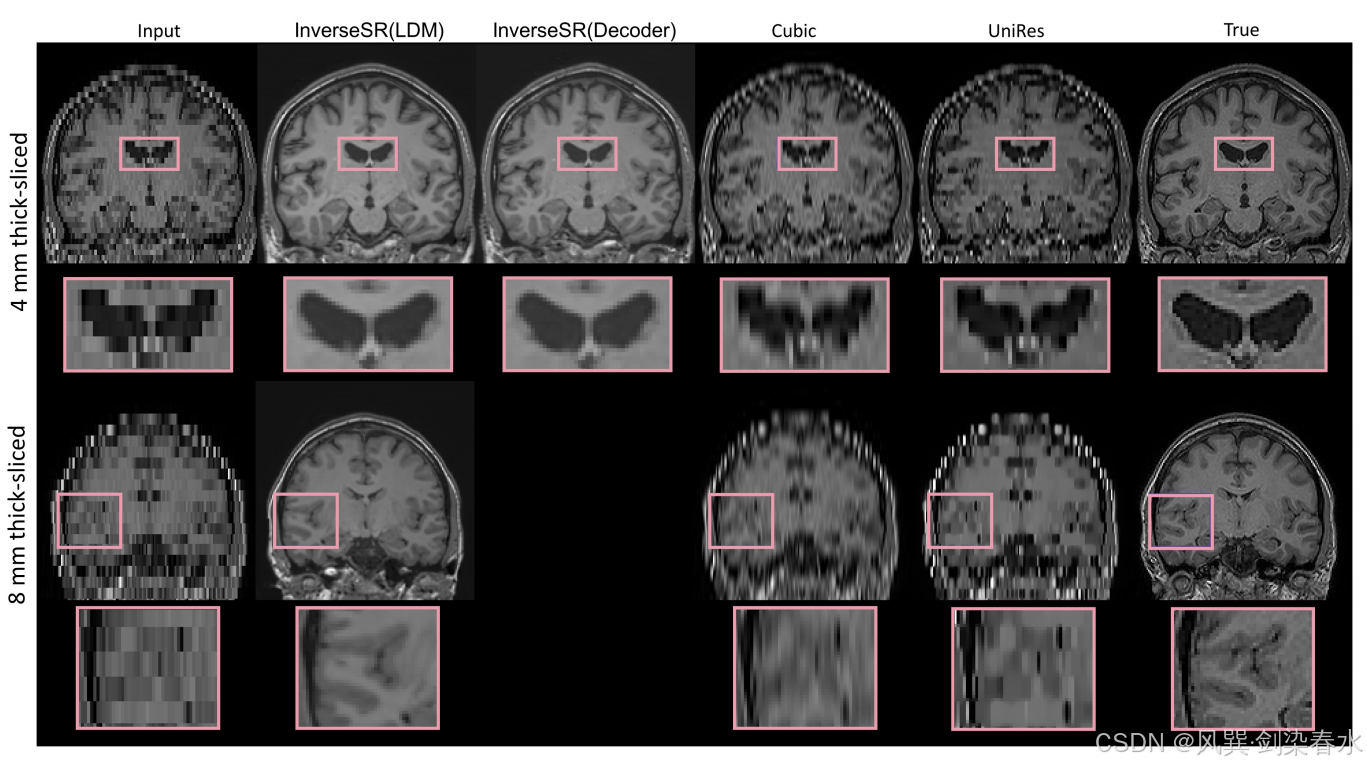
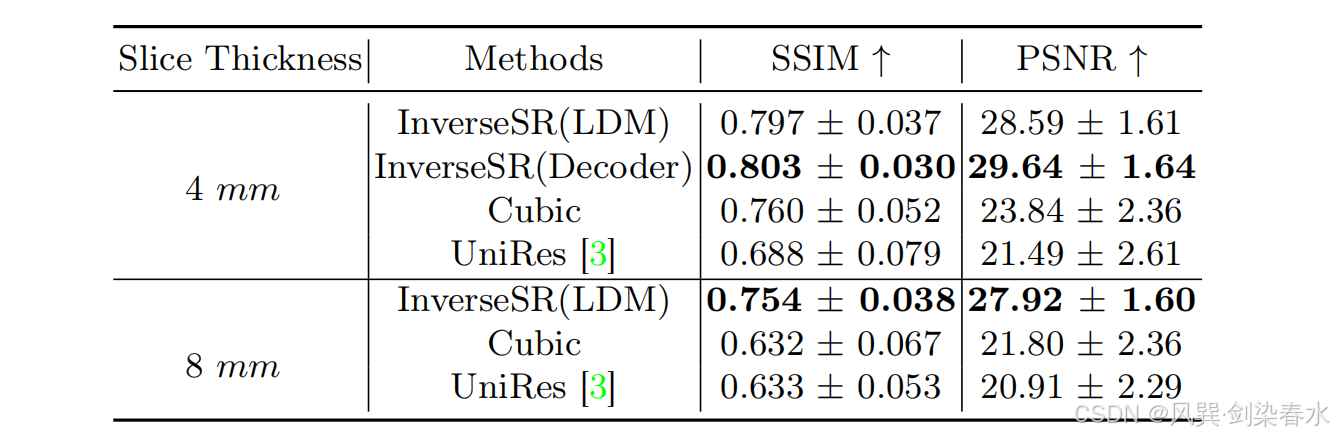
Table 1 | InverseSR 以及两个基线方法在 1 毫米扫描图像及其对应的超分辨率(SR)图像(分别从 4毫米 和 8毫米 轴向扫描图像生成)上的定量评估结果(均值 ± 标准误差):
Brain LDM 是之前的研究预训练好的,计算的损失是真实 LR 图像与 LDM 出来的 SR 经过退化后的 LR 图像,优化的是输入 LDM 的 z z z 以及条件 C C C
不太理解的是,高稀疏性就是层厚更厚么(⊙o⊙)

















 2047
2047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









