






MobileNetV2: Inverted Residuals and Linear Bottlenecks论文笔记以及Pytroch实现
这篇文章的切入点有点意思。作者认为使用RELU函数在某些情况下会导致模型获得的特征信息丢失,因此在某些情况下网络不能加RELU而需要添加线性激活函数(要是恒等映射的话就什么都不加)。此外,如果使用shortcut能够减少信息丢失。据此,作者进行了一系列的论证提出了自己的解决方法。感觉这个角度很新,之前一直认为RELU函数是可以用来防止过拟合的,其优点恰好是其可以丢弃负值,类似于dropout操作。故在设计网络的时候也就一股脑在BN层之后添加RELU函数。
本篇文章介绍比较简单,需要读者理解深度可分离卷积的操作步骤。
一、背景介绍
这篇文章主要目的是提出一个轻量化模型,能够支持手机等算力较小的平台使用。
作者提出了Manifold of interest这个名词来论述当特征维度较小时使用RELU函数进行激活会导致信息丢失。这里我引用一下Classification基础实验系列四——MobileNet v2论文笔记与复现对这个名词的解释。


二、Inverted residual block
故为了解决这个问题,最简单的方法就是当特征维度较高时使用RELU。此外,shortcut连接了原始特征,这可以大大降低信息丢失。而反观常见的Residual Block,都是两头宽,中间窄(宽和窄对应的特征维度)。作者一方面为了更好的节约存储空间,另一方面为了更好的使用RELU,提出了Inverted residual block。
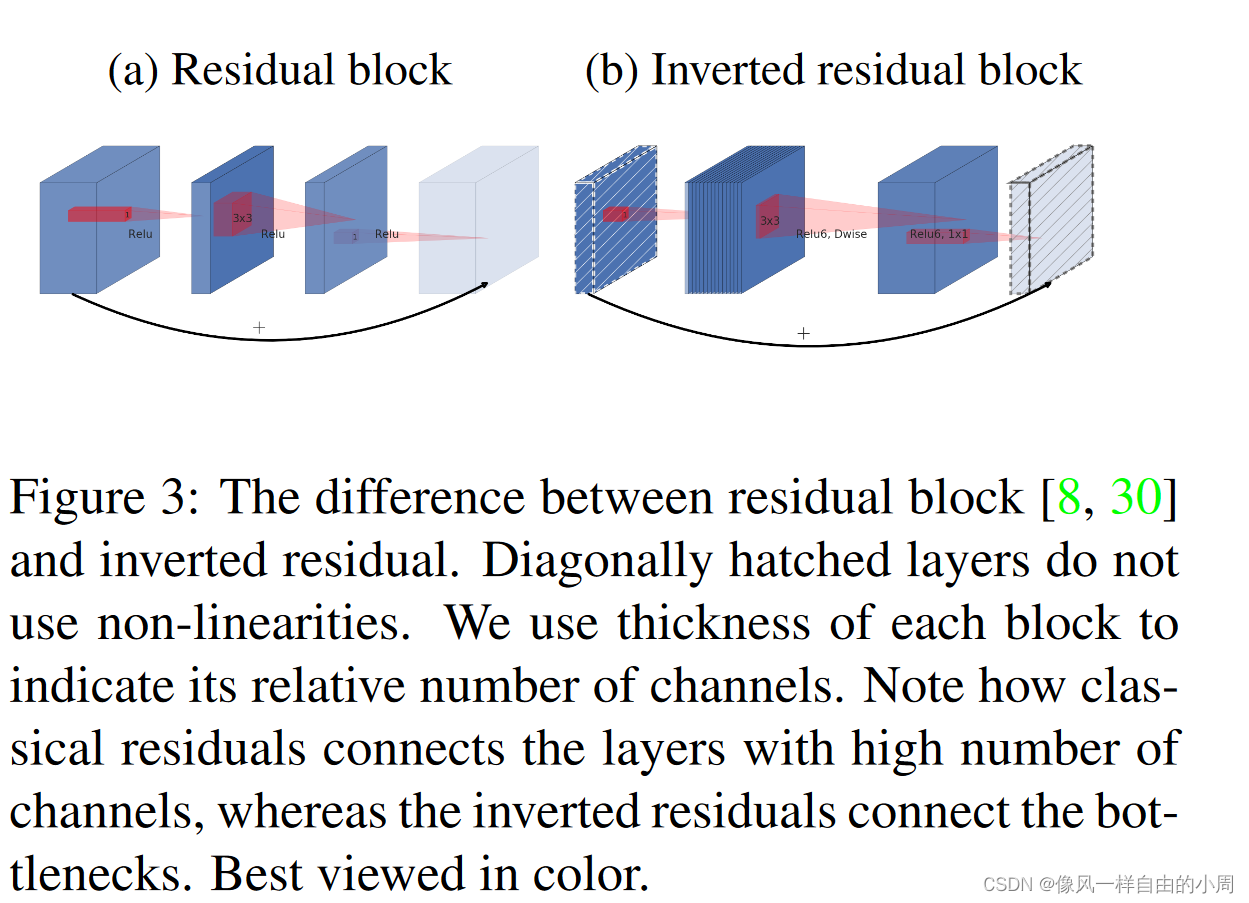
网络具体结构如下:

Pytroch代码如下,这里面因为目的是为了设计轻量化网络,故使用了深度可分离卷积。
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(inp * expand_ratio)
self.use_res_connect = self.stride == 1 and inp == oup
if expand_ratio == 1:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
三、网络结构
好了,接下来就是网络的整体结构了。

import torch.nn as nn
import math
def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
def conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
def make_divisible(x, divisible_by=8):
import numpy as np
return int(np.ceil(x * 1. / divisible_by) * divisible_by)
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(inp * expand_ratio)
self.use_res_connect = self.stride == 1 and inp == oup
if expand_ratio == 1:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, n_class=1000, input_size=224, width_mult=1.):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
interverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
# building first layer
assert input_size % 32 == 0
# input_channel = make_divisible(input_channel * width_mult) # first channel is always 32!
self.last_channel = make_divisible(last_channel * width_mult) if width_mult > 1.0 else last_channel
self.features = [conv_bn(3, input_channel, 2)]
# building inverted residual blocks
for t, c, n, s in interverted_residual_setting:
output_channel = make_divisible(c * width_mult) if t > 1 else c
for i in range(n):
if i == 0:
self.features.append(block(input_channel, output_channel, s, expand_ratio=t))
else:
self.features.append(block(input_channel, output_channel, 1, expand_ratio=t))
input_channel = output_channel
# building last several layers
self.features.append(conv_1x1_bn(input_channel, self.last_channel))
# make it nn.Sequential
self.features = nn.Sequential(*self.features)
# building classifier
self.classifier = nn.Linear(self.last_channel, n_class)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.mean(3).mean(2)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def mobilenet_v2(pretrained=True):
model = MobileNetV2(width_mult=1)
if pretrained:
try:
from torch.hub import load_state_dict_from_url
except ImportError:
from torch.utils.model_zoo import load_url as load_state_dict_from_url
state_dict = load_state_dict_from_url(
'https://www.dropbox.com/s/47tyzpofuuyyv1b/mobilenetv2_1.0-f2a8633.pth.tar?dl=1', progress=True)
model.load_state_dict(state_dict)
return model
if __name__ == '__main__':
net = mobilenet_v2(True)

















 9078
9078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









