







Learning Attentions: Residual Attentional Siamese Network for High Performance Online Visual Tracking
参考文章:https://blog.csdn.net/discoverer100/article/details/80754701
摘要:
本文提出了一个用于高性能物体跟踪的剩余注意力连体网络(RASNet)。RASNet模型在连体跟踪框架内重新定义了相关滤波器,并引入了不同种类的注意力机制,以适应模型,而无需在线更新模型。特别是,通过利用离线训练的一般注意力、目标适应的残差注意力和通道偏爱的特征注意力,RASNet不仅缓解了深度网络训练中的过拟合问题,而且由于表示学习和判别器学习的分离,增强了其判别能力和适应性。所提出的深度架构从头到尾进行训练,并充分利用丰富的空间时间信息来实现稳健的视觉跟踪。(本文基于Siamese network网络结构,加入了注意力机制(包括Residual Attention、General Attention和通道注意力),这项注意力机制作为一个layer嵌入到Siamese network网络中,缓解了深度网络训练中的过拟合问题,还提升了网络的判别能力和适应性。)
1、Introduction:
基于相关过滤的算法已经显示出卓越的计算效率和相当好的跟踪精度,其运行速度高的主要原因是用快速傅里叶变换的元素相乘法取代了耗尽的卷积法,以及采用了相对简单的图像特征。然而,对于复杂的追踪场景,使用手工制作的特征的CF追踪器的性能往往会大大下降。大多数基于深度学习的跟踪方法仍然无法达到完美的效果。一个问题是,离线学习的深度特征有时不能很好地适应追踪过程中的特定目标。如果深度特征提取器是在线学习的,那么它往往会过度适应目标。
此外,特征提取器的在线学习,其更新过程,甚至其推理过程,都是计算上的昂贵。这使得跟踪算法无法在每一帧同时执行所有这些操作。
RASNet,被设计用来学习有效的特征表示和决策判别器。RASNet中注意力模块的骨干是一个类似沙漏的卷积神经网络(CNN)模型[37],用于学习上下文和多尺度的特征表示。RASNet内的残差学习进一步帮助从多个层面对物体进行编码,并提出了一个加权交叉关联层来学习连体结构。所提出的RASNet广泛地探索了不同的注意力机制,使离线学习的特征表征适应特定的跟踪目标。为了保证高追踪效率,所有这些学习过程都是在离线训练阶段进行的。
贡献:
1、
提出了一个专门为物体跟踪问题设计的端到端深度架构。该深度架构继承了许多最新模型的优点,如沙漏结构、残余跳过连接,以及我们新提出的加权交叉关联,为视觉跟踪产生有效的深度特征学习。
2、
在RASNet中探讨了不同种类的注意机制。这些机制包括一般注意力、剩余注意力和通道注意力。因此,离线学习的特征表征与在线跟踪目标相适应,大大缓解了过度拟合。
3、
开发了非常有效和高效的基于深度学习的追踪器。它与一些最先进的追踪器相比表现出色,运行速度超过80帧/秒。为了便于进一步研究,源代码和训练好的模型可以在以下网站上找到:https://github.com/foolwood/RASNet。
2、Related Works:
讨论了最相关的跟踪方法和技术。特别是,基于深度特征的跟踪方法、基于端到端网络学习的跟踪方法,以及注意力机制都进行了研究。
Deep feature based tracker:
介绍了一些基于深度特征的跟踪器方法,这些方法的优势在于它们使用了深度网络的出色表现。然而,这些只有在线的方法并没有在离线数据集上训练该方法。这限制了模型的丰富性,如果需要对深度网络进行在线训练或更新,跟踪速度就会降低。
End-to-End learning based tracking:
为了获得端到端学习的好处,研究人员在视频上离线训练深度模型,并在目标跟踪基准上评估模型,进行在线跟踪。关键点在于如何制定跟踪问题以及如何设计离线训练损失函数。
介绍了SINT、SiamFc、GOTURN、MDNet、CFNet网络的一些特点。
这些方法推动了端到端深度跟踪模型的发展,并在最近的基准[51,52]和挑战[15,16]上取得了非常好的结果。然而,在使用类似的基准训练他们的模型时,可能会出现过度拟合。
Attention mechanisms:
注意机制首先被用于神经科学领域[38]。它们已经扩散到其他领域,如图像分类[24, 26, 48]、姿势估计[13]、多物体跟踪[6]等。
对于短时跟踪,DAVT[17]使用了一种鉴别性的空间注意进行物体跟踪,之后ACFN[5]开发了一种注意机制,选择相关的相关滤波器的一个子集进行跟踪。另一方面,RTT[7]通过一个多方向的RNN吸引对可能目标的注意来产生突出性,CSR-DCF[33]通过使用颜色直方图来构建一个前景空间可靠性图来约束相关滤波器的学习。
与这些注意机制相比,建议通过一个端到端的深度网络来学习注意。这种注意机制包括从离线训练数据集学习的一般注意和由残差网估计的残差注意,它包含了来自离线训练数据集和实时跟踪的在线目标的好处。
3、Residual Attentional Siamese Network:
与之前的深度追踪架构相比,RASNet从回归的角度重新制定了连体追踪,并提出了一个加权交叉关联来从头到尾学习整个连体模型。如图1所示,加权交叉关联探索了不同种类的注意力机制,即一般注意力、残余注意力和通道注意力,以使离线学习的深度模型适应在线跟踪目标。

3.1、Siamese Tracker Introduction
3.1.1、相关滤波跟踪
物体跟踪问题可以被表述为一个回归(岭回归)问题,即::

求解可得:

由于矩阵求逆过程很慢,因此可以将其转换到非线性空间,用对偶形式求解,得:
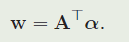
从公式中我们可以看到,二元形式将特征表示与判别器学习解耦,这里的α反映了判别器部分。对于基于回归的跟踪算法,例如KCF[22],基本问题是如何学习α的估计值。
从上述求解公式可以看出,传统相关滤波算法在建模过程中并没有考虑到目标物体图像特征的学习(主流相关滤波方法基本采用了HOG特征、CN特征,或者预训练好的CNN特征,严格来说,对于跟踪算法本身而言,没有特征学习的过程),而仅仅考虑了判别器的在线学习。
小结:传统相关滤波方法的特点:隔断了特征表示与判别学习。
3.1.2、Siamese network 跟踪方法
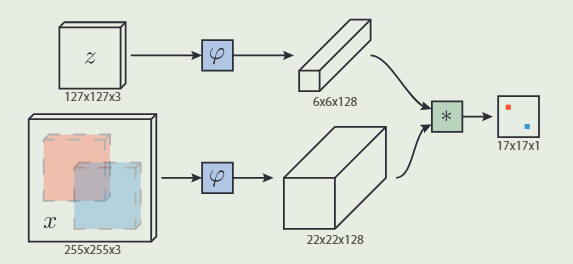
Siamese tracker 学习了一个函数 f ( z , z ′ ) f(z,z') f(z,z′) 来比较example 图像 $z $和相同尺寸的candidate图像 z ′ z' z′。与多个候选图像的比较可以通过 example 图像和具有较大尺寸的搜索图像之间的关联来实现,并获得一个响应图,如公式所描述的,其中x表示搜索图像。
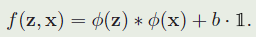
从上述公式(4)可以看出,与相关滤波方法不同,Siamese网络需要在函数 φ ( ⋅ ) φ(⋅) φ(⋅)中同时进行特征学习和判别学习,其判别结果体现在 f ( z , x ) f(z,x) f(z,x),另一方面,结合示意图可和公式以看出,Siamese网络的训练,只利用了单一样本 z z z。
小结:传统Siamese网络跟踪方法的特点:
- 同时进行特征学习和判别学习
- 训练样本比较少,容易形成过拟合
3.1.3、CFNet跟踪方法
为了解决传统Siamese网络的少样本容易形成过拟合问题,CFNet在Siamese网络中引入循环矩阵(虚拟的多样本),并且借助循环矩阵的优势提升计算性能。但是和标准相关滤波方法类似,CFNet中也不可避免地带来了边界效应(boundary effect)。
小结:CFNet跟踪方法的特点:
- 结合Siamese网络和相关滤波方法
- 具有边界效应,一定程度上限制了算法性能
3.1.4、本文提出的方法(RASNet)
为了更好地解决过拟合问题,本文基于Siamese网络,将特征学习与判别学习分离。如何分离?通过多种注意力机制的cross correlation来进行分离。
3.2、RASNet目标跟踪方法
3.2.1、RASNet总体结构

从上图可以看出,本文基于Siamese网络进行改进,且本文最重要的创新点对应于图中的三个部分:1、Residual Attention;2、 General Attention;3、 Channel Attention,各个部分的作用如下所示:
- Residual Attention:表示目标物体的全局信息(叠加、综合多帧视频画面中的目标信息)
- General Attention:表示目标的“空间信息”,可以理解为传统相关滤波中的期望的高斯响应map
- Channel Attention:表示特征通道信息,可以理解为对不同通道的特征进行加权处理
3.2.2、Residual Attention

论文用 ρ ~ \widetilde{\rho} ρ 表示Residual Attention,它是一个二维的map,本质上是某种置信图,用于估计目标的共同(全局)特征。
论文原文:The intuition behind this idea is that any one estimation might not capture both the common characteristics and distinctions of targets in different videos while a superposition of estimations might. The residual attention encodes the global information of the target and has low computation complexity. (from Section 3.3)
由于物体形状可能不是特别规范,难以简单粗暴地用一个矩形框来进行描述,因此在进行图像采样时,很容易就将背景图像也一并包含进来了,这样就对跟踪器的训练产生困扰,这些边边角角的图像成分究竟是不是物体?然而我们能够想到一种规律或者称为一种假设:物体在持续运动过程中,其自身特征成分应该是稳定的(色彩啊纹理啊什么的),背景部分很可能千变万化,如果我们能够想到将这种共同的部分提取出来,那么算法也就能够大体得到物体的形状轮廓了。
论文的解决思路是利用Residual Attention,将众多帧中采样图像的共同部分提取出来,形成较为稳定的形状轮廓,这部分也是本文最大的亮点。联想到之前的 C S R − D C F CSR-DCF CSR−DCF算法(可以参考文章https://blog.csdn.net/discoverer100/article/details/78182306),本文在这方面期望达到的目的与之类似,本文的思路更进了一步, C S R − D C F CSR-DCF CSR−DCF通过颜色成分来确定物体的形状轮廓,在处理颜色不太单一的目标时可能会出现不理想,本文通过多帧画面中的共同成分来进行轮廓分析,理论上更优越一些。
值得注意的是,论文在计算Residual Attention时,用到了沙漏网络(Hourglass Networks),这种网络最明显的特点是:先对图像进行下采样,再对图像进行上采样,因此呈沙漏形。
3.2.3、General Attention

论文用 ρ ‾ \overline{\rho} ρ 表示,该变量也是一个二维矩阵,表示空间区域中的某种置信分布,其物理意义与相关滤波中基于高斯分布的期望输出比较类似,两者的区别在于:传统相关滤波中的期望输出通常为固定数值的二维矩阵,而本文的general attention是通过学习得到的。
3.2.4、Dual Attention = Residual Attention + General Attention
dual attention ρ \rho ρ 就是将上述residual attention和general attention进行叠加:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ESydEfHL-1679627337091)(null)]
两种Attention进行叠加的示意图下所示:

Dual Attention的实际效果如下图所示:
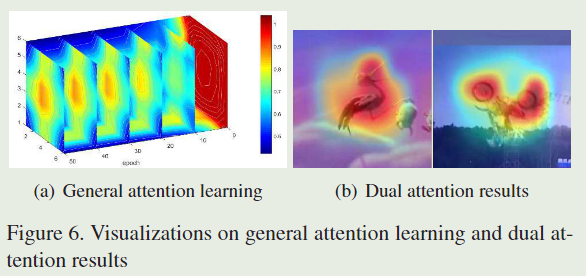
在上图中,图(a)描述General Attention的学习状况,可以发现,迭代次数达到50次后,效果可以达到最好。
3.2.5、Channel Attention
一般情况下,经过卷积神经网络提取的特征通常都包含很多channel,其中每一层channel都代表了某种特定的模式,在不同的场景下,不同的channel可能具有相异的显著性(重要性),因此可以通过引入注意力机制对各个channel进行选择(这部分思想的出发点与 C S R − D C F CSR-DCF CSR−DCF比较接近)。该部分的示意图如下所示:

这里,论文用 i i i 表示channel层号,第 i i i 层的特征输出为:

3.2.6、融合
三种Attention融合的思路示意图:
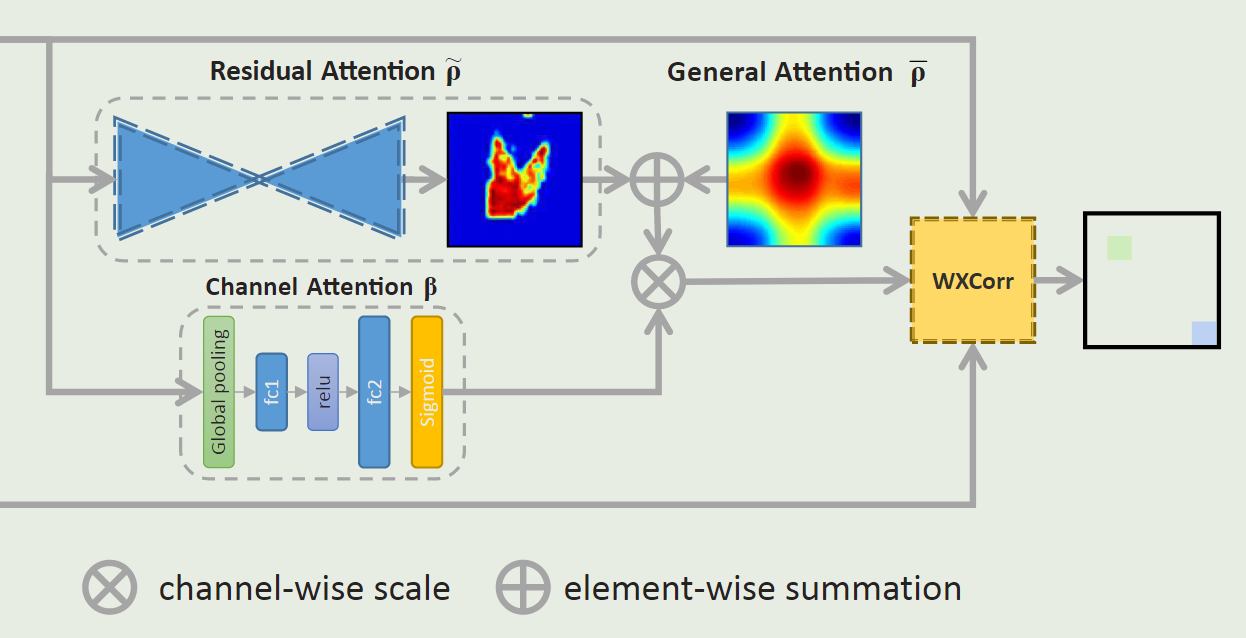
融合思路,可以认为:首先将Residual Attention和General Attention进行“叠加”,得到Dual Attention,然后将Dual Attention与Channel Attention进行加权相乘。以下是论文的公式:
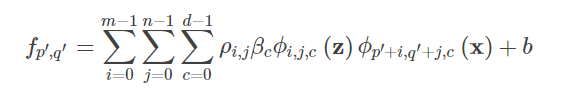
其中, ρ ρ ρ表示Dual Attention, β β β表示Channel Attention, z z z表示模板图像, x x x表示搜索图像。
在论文中,这样的融合思想就是Weighted Cross Correlation,其中weighted就体现在论文创新的Attention机制。
回顾SiamFC跟踪算法的基本建模:

通过比较可以发现,论文所做的工作主要是:基于SiamFC,在模板图像中增加了注意力机制处理,以解决边界效应,实现更加鲁棒的目标跟踪方法。
3.2.7、Network Architecture
首先回顾SiamFC网络的loss function,下面是一个样本对的损失函数:
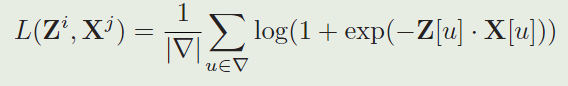
这种方式可能存在过拟合的问题,如下图所示:

从图中可以看出,论文选择了8帧画面,对于SiamFC算法而言,一个training pair可能随机地包含了两帧画面,比如,#1和#4就有可能被选择为一组training pair,然而#4是目标处于完全遮挡下的状态,用这种方式来训练会导致过拟合,降低跟踪器的性能。
基于SiamFC跟踪算法的上述不足,论文采用了一种类似加权的思路进行改进,以下是论文中所有样本对的loss function:
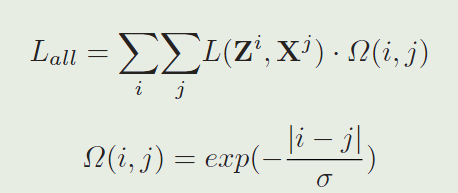
表示时间上的有效性权重,其基本思想是:两帧之间隔得越远,权重就越低。如此,就可以很大程度上避免SiamFC算法存在的上述训练过拟合问题。
跟踪器执行流程:范例和实例首先被传送到它们各自的Siamese网络分支中,以获得特征图。例子的特征图同时进入Residual Attention和Channel Attention。通道注意描述了通道之间的优先级,通过它,样本特征被逐通道相乘。通道注意的特征与通过双重注意从实例中提取的特征相融合。这一操作由加权交叉关联层实现,并产生一个响应图。
4、算法效果:
- 论文在OTB-2013数据集上的success score为0.672,在OTB-2015数据集上的success score为0.642。整体上与CREST算法接近,超过了SINT/SRDCF/SiamFC/CFNet/CSR-DCF等算法
- 论文算法的跟踪速度为83fps,稍高于SiamFC算法的75fps,远高于CSR-DCF的24fps
5、总结:
本文提出了一个新的深度架构,名为RASNet,特别为在线视觉跟踪而设计。论文在Siasmes Network基础上,通过引入了三种注意力机制(Residual Attention、General Attention和Channel Attention),进一步描述了目标物体的外观轮廓,优先选择了更加强有力的特征通道,并对它们进行加权融合,作为一个layer嵌入到Siamese Network中进行end-to-end训练,最终取得了良好的效果。















 5225
5225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









