







SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines
文章标题:《SiamFC++:Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines》
文章地址:https://arxiv.org/abs/1911.06188
github地址:https://github.com/MegviiDetection/video_analyst
参考链接:https://blog.csdn.net/Yemiekai/article/details/121982795
参考链接:https://blog.csdn.net/PAN_Andy/article/details/104584807
贡献以及创新点:
问题的提出:
视觉跟踪问题要求同时对给定目标进行有效的鲁棒分类和准确的目标状态估计。以往的方法提出了各种不同的目标状态估计方法,但很少考虑到视觉跟踪问题本身的特殊性。
贡献:
1、本文分析了以往的目标跟踪方法,提出了一种用于高性能通用的目标跟踪器设计的实用目标状态估计准则。
- 引入分类和目标状态估计分支(G1)
- 无歧义分类得分(G2)
- 无先验知识跟踪(G3)
- 估计质量得分(G4)
2、根据这些指导方针,我们设计了我们的 Fully Convolutional Siamese tracker++ (SiamFC++)
1、Introduction
通用视觉跟踪的目的是在给定非常有限的信息(通常只有第一帧的注释)的情况下,按顺序定位视频中的运动对象。作为计算机视觉各个领域的基本构建块,该任务具有各种应用,如基于无人机的监控和监控系统。通用对象跟踪的一个独特特征是,不允许有关于对象及其周围环境的先验知识(例如对象类)。
**跟踪问题可以视为分类任务和估计任务的组合。**第一项任务旨在通过分类为目标提供可靠的粗略定位。然后,第二项任务是估计准确的目标状态,目标状态通常由边界框表示。
尽管现代跟踪器已经取得了重大进展,但令人惊讶的是,他们用于第二项任务的方法(即目标状态估计)差异很大。基于目标状态估计这个方面,先前的方法可以大致分为三类。
- 第一类,包括判别相关滤波器(DCF)和SiamFC,采用了暴力的多尺度测试,这样做非常不准确,而且效率低下(。而且,目标的尺度和长宽比率在相邻帧中以固定速率变化这一假设通常并不现实。
- 第二类,ATOM 通过梯度递增迭代地优化多个初始边界框以估计目标边界框,这在准确性上产生了重大改进。但是,这种目标估计方法不仅带来沉重的计算负担,而且带来许多其他需要仔细调整的超参数(例如,初始box的数量,初始box的分布)。
- 第三类是SiamRPN跟踪器系列,通过引入区域提议网络(RPN)来执行准确而有效的目标状态估计。但是,预定义的anchor设置不仅引入了模糊的相似性评分,严重破坏了鲁棒性(请参见第4节),而且还需要数据分布的先验信息,这显然与通用对象跟踪的目标背道而驰。
本文方法的核心是将基于anchor的追踪框预测直接变成 基于对中心到地面真实边界框上下左右四个边的距离的预测上来。之前应用anchor的目标是为了解决SiamFC在追踪的过程中,只能进行目标的中心位置的定位,而对于边界框的尺寸和长宽比却没有办法,这一问题。但是如果能直接回归中心到地面真实边界框的距离的话,就可以直接解决这一问题了。这一个变化,直接满足了G1、G2和G3。添加回归质量评估G4主要是为了提高位置回归的准确性。
基于上述,本文为高性能通用对象跟踪器设计提出了一套准则:
-
G1:分开进行分类和状态估计。跟踪器应执行两个子任务:分类和状态估计。 没有强大的分类器,追踪器就无法将目标与背景或干扰因素区分开,这严重阻碍了目标的鲁棒性。 没有准确的状态估算结果,跟踪器的准确性将受到根本限制。 这些暴力的多尺度测试方法由于效率低下和准确性低而很大程度上忽略了状态估计的任务。
-
G2:无歧义评分。分类分数应该直接表示目标存在的置信度分数,即在“视野”中,即对应像素的子窗口,而不是诸如anchor box之类的预定义设置。 对于一个负例,对象与锚点之间的匹配(例如,基于锚点的RPN分支)容易产生假阳性结果,从而导致跟踪失败(更多信息请参见第4节)。
基于anchor的孪生追踪方法评分的歧义主要体现在在搜索图像的一个位置上,打了很多anchor,根据anchor的得分来选择追踪预测anchor,这个过程是歧义的。
-
G3:无先验信息。跟踪方法应该没有像尺度/长宽比分布这样的先验知识,这是通用对象跟踪的目标提出的。 现有方法广泛依赖于数据分布的先验知识,这阻碍了泛化能力。
-
G4:估计质量评估。之前的研究表明,将分类置信度用于边界框选择将直接导致性能下降。 与先前关于对象检测和跟踪的许多研究一样,应该使用与分类无关的估计质量评分。 第二个分支(例如ATOM和DiMP)的惊人准确性很大程度上取决于此准则。 尽管其他人仍然忽略了它,但仍有进一步提高状态估计准确性的空间。
估计质量的评估,其实是对回归结果质量的评估,是用于最终的预测追踪框的选取。
根据上述准则,我们基于全卷积孪生跟踪器(SiamFC)设计了SiamFC ++方法,由于其全卷积性质,特征图的每个像素直接对应于搜索图像上的每个变换子窗口 。 我们与分类头(G1)并行添加一个回归头,以进行准确的目标估计。 由于预先定义的anchor设置已删除,因此有关目标尺度和长宽比分布的匹配歧义(G2)和先验知识(G3)也已删除。 最后,在G4之后,将评估质量评估分支添加到具有高质量的优先边界框。
贡献可以概括为三个方面:
- 通过识别跟踪的独特特征,我们为现代跟踪器设计设计了一套实用的目标状态估计准则。
- 我们根据提出的准则设计了一个简单但功能强大的SiamFC ++跟踪器。 大量的实验和综合分析证明了我们提出的指南的有效性。
- 我们的方法在五个具有挑战性的基准上获得了最新的结果。 据我们所知,我们的SiamFC ++是第一个在大型TrackingNet数据集(Muller等人,2018年)上以90 FPS运行时AUC得分达到75.4的跟踪器。
2、Related Works
Tracking Framework
现代跟踪器可以通过其目标状态估计的方式大致分为三个分支。
其中一些方法,包括DCF和SiamFC,使用多尺度测试来估算目标尺度。具体地,通过将搜索图像重新缩放为多个比例并组装一个小批量的缩放图像,该算法选择与最高分类得分相对应的比例作为当前帧中的预测目标比例。 该方法从根本上受到限制,因为边界框估计本质上是一项艰巨的任务,需要对对象的姿势有一个高层次的理解。
受DCF和IoU-Net的启发,ATOM通过顺序地执行分类和估计来跟踪目标。 对通过分类获得的目标的粗略初始位置进行迭代完善,以进行准确的追踪框估计。 每帧边界框的多次随机初始化以及迭代完善中的多次反向传播大大降低了ATOM的速度。 该方法在准确性上产生了显着的改进,但是也带来了沉重的计算负担。 此外,ATOM引入了许多其他需要仔细调整的超参数。
另一个名为SiamRPN的分支机构及其后续工作在孪生网络后附加了区域提议网络,从而实现了前所未有的准确性。 RPN回归预定义锚框和目标位置之间的位置偏移和大小差异。 但是,RPN结构更适合于需要高召回率的对象检测,而在视觉跟踪中,仅应跟踪一个对象。 而且,锚框和物体之间的模棱两可的匹配严重地阻碍了跟踪器的鲁棒性(请参见第4节)。 最后,锚设置不符合通用对象跟踪的精神,需要预先定义的描述其形状的超参数。
Detection Framework
视觉跟踪任务具有许多独特的特征,它与对象检测仍有很多共同点,这使得两个任务都可以从彼此受益。
例如,首先在Faster-RCNN中设计的RPN结构在SiamRPN中的应用达到了惊人的准确性。继承于Faster-RCNN,大多数最先进的现代检测器(基于锚的检测器)都采用了RPN结构和锚点的设置。基于锚点的检测器将预定义提议(称为锚点)分类为正例或负例,并通过额外的偏移量回归来优化对边界框位置的预测。但是,锚点框引入的超参数(例如锚定框的尺度/比率)对最终精度产生很大影响,并且需要启发式调整。研究人员尝试了多种方法来设计anchor-free的检测器,例如预测物体中心附近的点处的边界框,或者检测并组合边界框的一对角。在本文中,我们表明,基于精心设计的目标状态估计准则的简单技术路线可以实现最先进的跟踪性能。
3、SiamFC++: Fully Convolutional Siamese Tracker for Object Tracking
在本节中,将详细描述全卷积暹罗跟踪器++框架。我们的SiamFC++基于SiamFC,并根据建议的指导方针逐步改进。如图2所示,SiamFC++框架由一个用于特征提取的暹罗子网络和一个用于分类和回归的区域建议子网络组成。
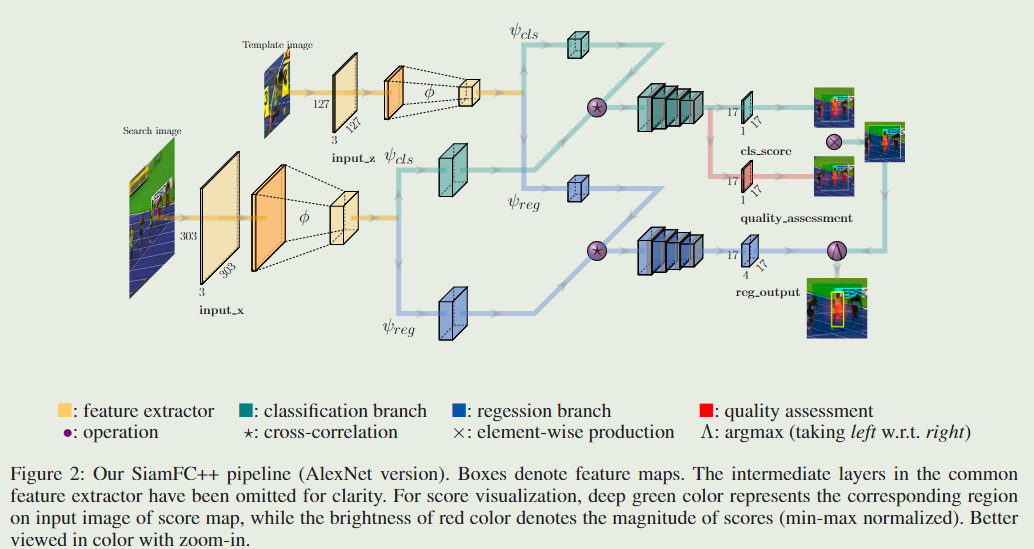
Siamese-based Feature Extraction and Matching
目标跟踪任务可以看做是相似度学习(similarity learning)问题。具体来说,我们离线训练一个暹罗网络,然后通过在线评估,在一个更大的搜索图(search image)上定位我们的模板图(template image)。暹罗网络由两个分支组成,template 分支以 z z z 作为输入,它是从第一帧图像中,目标所在位置裁剪出来的图像块。search 分支采用当前帧作为输入,记为 x x x 。两个分支共用同一个骨干(backbone),它对输入 z z z 和 x x x 进行同样的转换,把它们嵌入到同一个特征空间中,用于后续的任务。模板图和搜索图在嵌入空间 ϕ \phi ϕ 上进行相关(cross-correlation):

其中 ⋆ \star ⋆ 表示相关操作(cross-correlation)。 ϕ ( . ) \phi(.) ϕ(.) 表示用骨干网络提取通用特征。 ψ i \psi_i ψi 表示特定的任务层,用 i i i 指明哪个任务( cls \text{cls} cls 表示分类, reg \text{reg} reg 表示回归)。在我们的实现中,对模板图的 ψ cls ( . ) \psi_{\text{cls}}(.) ψcls(.)和对搜索图的 ψ cls ( . ) \psi_{\text{cls}}(.) ψcls(.) 是两个不一样的卷积层,另外两个 ψ reg ( . ) \psi_{\text{reg}}(.) ψreg(.)也是如此。另外,对同一个图的 ψ cls ( . ) \psi_{\text{cls}}(.) ψcls(.)和 ψ reg ( . ) \psi_{\text{reg}}(.) ψreg(.) ,输出尺寸是一样的。(详情看上面的图)
Application of Design Guidelines in Head Network
基于 SiamFC,我们会按照提出的指南逐步完善跟踪器的每个部分。
遵循 G1 (分类和和状态估计分开进行) ,我们在嵌入空间中进行互相关后设计分类头和回归头。 对于特征图中的每个像素,分类头将 ψ c l s \psi_{cls} ψcls 作为输入,并将相应的图像块分类为一个正例和负例,而回归头将 ψ r e g ψ_{reg} ψreg作为输入,并输出额外的偏移量回归以优化边界框位置的预测 。 分类头和回归头的结构在图2的互相关操作之后给出。
具体而言,对于分类分支,如果特征图 ψ c l s \psi_{cls} ψcls上的一个位置 ( x , y ) (x,y) (x,y)对应的输入图像位置 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) \left(\left\lfloor\frac{s}{2}\right\rfloor+ x s,\left\lfloor\frac{s}{2}\right\rfloor+ y s\right) (⌊2s⌋+xs,⌊2s⌋+ys) 落在地面真实边界框中,那个特征图的的位置 ( x , y ) (x,y) (x,y) 就认为是正例,否则,特征图的的位置 ( x , y ) (x,y) (x,y) 就是负例。这里的 s s s 是主干网络的总步幅(这篇论文中 s = 8 s=8 s=8)。
对于特征图 ψ r e g \psi_{reg} ψreg 上的每个位置 ( x , y ) (x,y) (x,y) 的回归任务,最后一层预测特征图 ψ r e g \psi_{reg} ψreg 上的每个位置 ( x , y ) (x,y) (x,y) 对于的输入图像位置 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) \left(\left\lfloor\frac{s}{2}\right\rfloor+ x s,\left\lfloor\frac{s}{2}\right\rfloor+ y s\right) (⌊2s⌋+xs,⌊2s⌋+ys) 到地面真实边界框上下左右四个边的距离,将这个距离表示为一个4维的向量 t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) \boldsymbol{t}^{*}=\left(l^{*}, t^{*}, r^{*}, b^{*}\right) t∗=(l∗,t∗,r∗,b∗) 。因此,对于位置 ( x , y ) (x,y) (x,y) 的回归任务可以形式化为:
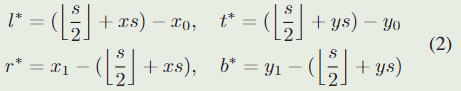
其中 ( x 0 , y 0 ) (x_0,y_0) (x0,y0) 和 ( x 1 , y 1 ) (x_1,y_1) (x1,y1) 表示与$( x , y ) $ 对应的地面真实边界框 B ∗ B^{*} B∗ 的左上角和右下角。
分类和回归头特征图上的位置 ( x , y ) (x,y) (x,y),对应于输入图像上的中心在 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) \left(\left\lfloor\frac{s}{2}\right\rfloor+ x s,\left\lfloor\frac{s}{2}\right\rfloor+ y s\right) (⌊2s⌋+xs,⌊2s⌋+ys) 的一个图像块。对于准则G2 (无歧义的评分),我们像许多以前的追踪器一样,直接对相应的图像块进行分类,并在该位置回归目标边界框。换句话说,我们的 SiamFC++ 直接将位置视为训练样本。别人那些基于锚点框(anchor-based)的做法把输入图像上的位置当做许多锚点框的中心,在同一个位置输出多个分类得分,对这些锚点框进行坐标回归,这样会导致 anchor 与目标之间的模糊匹配,我们认为认为模棱两可的匹配可能会导致严重的问题。因此在我们的逐像素预测方式中,最终特征图上的每个像素只做一个预测,每个分类分数都直接表示目标是否在对应像素的子窗口的置信度,我们的设计在这种程度上是没有歧义的。
由于SiamFC ++直接关于位置进行分类和回归,它没有预定义的锚框,因此也没有关于目标数据分布(例如尺度/长宽比)的先验知识,完全符合G3。
在上述章节中,我们还没有考虑目标状态的估计质量,直接用了分类得分来选择最终的框。这会导致定位准确性的下降,分类得分没有很好地和定位准确性关联起来,在输出特征图像素点对应的输入子窗口上,中心点附近的重要性比周围的要大。因此,我们假设围绕物体中心的特征像素比其他特征像素具有更好的估计质量。根据准则G4 (状态估计质量的评估) ,我们添加了一个简单而有效的质量评估分支,和分类头一样,用一个 1 × 1 1\times1 1×1 卷积输出多一块特征图。这块特征图的输出用于估计中心度得分(Prior Spatial Score, PSS \text{PSS} PSS),其定义如下:

PSS 并不是质量评估的唯一选择,作为一个变量,我们也可以预测真实框和预测框之间的 IoU \text{IoU} IoU 得分:
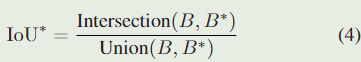
其中 B 是预测的包围框, B ∗ B^* B∗ 是对应的真实标签框。
在推理过程中,将预测出来的 分类得分 和对应位置的 PSS \text{PSS} PSS 相乘,然后依据这个最终的得分来选择包围框。 这样一来,远离目标中心点的包围框会被降低权值,提高了跟踪的准确性。
Training Objective
我们优化训练目标如下:
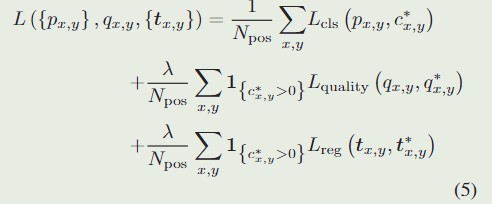
其中
1 { . } \boldsymbol{1}_{ \{ . \} } 1{.}是一个指示函数,如果括号里的式子成立,那么函数的值为 1 ,反之为 0 。
L cls L_{\text{cls}} Lcls表示 focal loss \text{focal loss} focal loss ,用于对分类做损失。
L quality L_{\text{quality}} Lquality表示二值交叉熵(binary cross entropy,BCE)损失,用于对质量评估做损失。
L reg L_{\text{reg}} Lreg表示 IoU \text{IoU} IoU 损失,用于边界框坐标回归的损失。
如果位置 ( x , y ) (x,y) (x,y) 上被认为是正样例,则 c x , y ∗ c^*_{x,y} cx,y∗的值为 1 ,对于负样例, c x , y ∗ c^*_{x,y} cx,y∗ 的值为 0 。
4、Experiments
4.1、Implementation Details
Model settings
本文用不同的网络骨干,做了两个版本的跟踪器:
(1)backbone 用改造过的 AlexNet,记为 SiamFC++ - AlexNet。
(2)backbone 用 GoogLeNet,记为 SiamFC++ - GoogLeNet。
其中 GoogLeNet 的计算成本比之前的 ResNet-50 更低,而在基准测试上与 ResNet-50 的性能相同甚至更好。
这些网络都在 ImageNet 上做了预训练,经证明,对于跟踪任务来说都是非常实用的。
Training data
我们采用 ILSVRC-VID/DET,COCO,Youtube-BB,GOT-10k 作为基本训练集。对于视频数据集,我们从 VID,LaSOT,GOT-10k 上选取一对一对的图片,每一对图片来自同一个视频序列,两张图片的间隔不超过 100 100100 帧(Youtube-BB 是 5 55 帧)。对于图像数据集(COCO,Imagenet-DET)我们弄一些负样本(两张图片是不同的目标)作为训练数据的一部分,来提高模型识别区分干扰物的能力。作为数据增强技术,我们在搜索图像上按照均匀分布进行随机移动和缩放。
Training phase
对于 AlexNet 的版本,我们冻结 conv1 到 conv3 的参数, 微调 conv4 和 conv5。对于那些没有预训练权重的网络层,我们采用零中心的高斯分布(zero-centered Gaussian distribution)进行初始化,标准差为 0.01 0.01 0.01。首先用 5 5 5 个 epoch 对网络进行预热训练,学习率从 1 0 − 7 10^{-7} 10−7 线性上升到 2 × 1 0 − 3 2\times 10^{-3} 2×10−3。然后用余弦退火学习率(cosine annealing learning rate)调整剩下的 45 45 45 个 epochs,每个 epoch 用 600 , 000 600,000 600,000 个图像对。用动量为 0.9 0.9 0.9 的随机梯度下降(SGD)作为优化器。
对于 GoogLeNet 的版本,我们冻结 stage 1 和 2 的参数,微调 3 和 4 。基础学习率增加到 2 × 1 0 − 2 2\times 10^{-2} 2×10−2 ,骨干网络的学习率的大小设为全局学习率的 0.1 。每个 epoch 的图像对数量减少为 300,000 对,epoch 总数减少为 20 (其中 5 个 epoch 用于预热,15 个 epoch 用于训练),在第 10 个 epoch 时解冻骨干网络的参数以防止过拟合。对于 LaSOT 的基准实验,我们冻结骨干网络的参数,将每个 epoch 的图像对进一步降低至 150 , 000 对,使训练数据量相对较少的训练得以稳定。
在 VOT2018 的 sort-term 基准测试中,用 AlexNet 作为骨干的跟踪器运行速度为 160 FPS,用 GoogLeNet 的运行速度为 90 FPS,用的 GPU 都是 NVIDIA RTX 2080Ti。
Test phase
模型的输出是一系列包围框,以及它们对应的得分 s 。基于每个框的尺度和比例的变化,以及它们与最后一帧预测目标位置的距离,对得分进行惩罚。根据惩罚后的得分来选择最终的结果,更新目标状态。
4.2、From SiamFC towards SiamFC++
虽然它们两者都用了逐个像素预测的方式,但是 SiamFC 和我们的 **SiamFC++**之间存在显著的性能差距。在本小节中,我们对 VOT2018 数据集进行了消融研究,以 SiamFC 为基线,旨在找出改善跟踪性能的关键部分。

如 (表1) 所示,在 SiamFC++ 基线中,跟踪器只做分类任务,目标状态估计是用多尺度测试来做的。我们逐渐对它添加额外训练数据(第 2 ,4 行),采用一个更好的网络头(第 3 行),增加回归头升级成我们的 SiamFC++(第 5 行)。进一步地,还把骨干从 AlexNet 换成了 GoogLeNet 来更好地提取视觉特征(第 6 行)。
下面以降序地方式罗列影响跟踪器性能的关键组件:回归分支(0.094 ),数据源的多样性(0.063 / 0.010 ),更强的骨干(0.026 ),更好的网络头结构(0.02 ),其中括号里面表示这些组件带来的 Δ EAO \Delta \text{EAO} ΔEAO。注意这些额外组件都是来自建立在 SiamFC 之上的 SiamRPN++。在 SiamFC 上添加了所有这些组件后,我们的 SiamFC++ 以更少的计算预算实现了优异的性能。此外,值得一提的是:(1) 第 2 行的鲁棒性 ( R \textbf{R} R) 超过了 SiamRPN (0.46 );(2) 第 3 行的 R \textbf{R} R 与 DaSiamRPN (0.337) 水准相同,但是用了更少的数据(没有用COCO 和 DET)。这些结果表明,引入 RPN 和 Anchor 无疑会提高精度,但其鲁棒性并没有得到提高,甚至受到阻碍。可以认为这是由于它们违反了我们提出的设计准则。
4.3、Quality Assessment Choice
在 GOT-10k 的验证集上,通过对SiamFC++ — GoogLeNet进行实验,用 PSS \text{PSS} PSS 的方法达到 77.8 的 AO,用 IoU \text{IoU} IoU 的方法达到 78.0 的 AO。 我们在最后的实现中采用 PSS \text{PSS} PSS,因为在实验中发现它跨数据集的稳定性较好。
5、Conclusion
在本文中,我们通过分析视觉跟踪任务的独特特征和以前跟踪器的缺陷,提出了一套用于跟踪器设计中目标状态估计的准则。 遵循这些准则,我们提出了一种为分类和目标状态估计(G1)提供有效方法的方法,给出了不含歧义的分类评分(G2),没有先验知识的跟踪(G3),并且明确估计质量(G4)。 我们通过广泛的消融研究验证了提出的指南的有效性。 而且,我们证明了基于这些准则的跟踪器可以在五个具有挑战性的基准上达到最先进的性能,同时仍以90 FPS的速度运行。















 2531
2531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









