







SiamRPN:High Performance Visual Tracking with Siamese Region Proposal Network
SiamRPN是2018CVPR上的一篇文章,通过孪生网络+RPN的方式实现高速、精准的目标跟踪。
论文地址:http://openaccess.thecvf.com/content_cvpr_2018/papers/Li_High_Performance_Visual_CVPR_2018_paper.pdf
代码地址:https://github.com/songdejia/Siamese-RPN-pytorch
参考资料:https://blog.csdn.net/PAN_Andy/article/details/102760746
参考资料:https://blog.csdn.net/qq_36449741/article/details/99696200
研究动机:
摒弃传统的多尺度测试和在线微调,引入RPN,在实时速度下获得最佳性能。
主要贡献:
- 1.端对端离线大样本训练。
- 2.将在线跟踪过程变为单样本检测方式,避免了多尺度检测。
- 3.以160 FPS的速度取得领先的表现,证明了其在准确性和效率上的优势。
预备知识:
作者引入了RPN网络,首先先对RPN网络的相关知识进行介绍:
gird:
grid中文译为格,如下图是YOLO论文中的一张图,grid就是指的对一张图像或者是featuremap进行平均地分割,但是并不一定是一个像素对应一个grid,也可能是多个像素对应一个grid。所有grid组成一个Proposal。

anchors:
anchors可以翻译成锚点,指的是在boundingbox生成之前会先在每个grid上生成一些候选框,然后将这些anchors候选框进行后续操作,生成boundingbox。
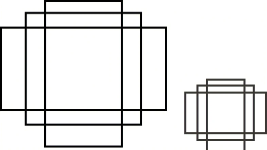
一般候选框会有一些固定的参数,首先是长宽比,例如上图左边的三个anchors对应一个grid生成的三种不同长宽比的anchors,一般长宽比的数目都是固定的而且长宽比互为倒数,比如{0.5,1,2};其次,是尺度大小,也就是anchors的面积,一般同一个featuremap下的grid都是看作生成相同尺度的anchors,经过不同层的featuremap对应不同的尺度,也就生成不同尺度的anchors,例如左边和右边尺度不同的anchors。
分类分支:
例如,在 s × s s×s s×s 的grid区域内,每一个grid都会生成 k k k 种不同长宽比的anchors。那经过分类分支会生成一个 s × s × k s×s×k s×s×k 的分类的标签,也就是说一个anchor会生成一个标签,如果是目标的anchors则为1,anchor是背景的则为0。
回归分支:
anchors具有固定的长宽比,不能直接拿来做boundingbox,要对其进行一个回归操作。早期的回归分支是通过平移、缩放等操作进行回归,网络需要学习的就是变换过程的参数。如今,回归的操作还有经过卷积等操作,直接输出boundingbox的位置和大小。
NMS:
NMS全称是Non-Maximum Suppression,译为非极大值抑制。NMS可以理解为不是极大值就抑制它。如下图所示,有两个anchors都分类为狗,这时会计算两个框之间的IoU,如果大于某个阈值,则认为两个框检测的是同一个物体,将得分高的框保留,得分低的框去除。图中红色框得分0.9,绿色得分0.7,两个框的IoU大于某个阈值,则只保留红色来检测狗的位置。

RPN:
RPN的全称是RegionProposal Network,译为区域建议网络。RPN可以理解为,从一张图像或者featuremap选择一个区域,生成anchors。RPN具有两个分支,一个是分类分支,一个是回归分支。
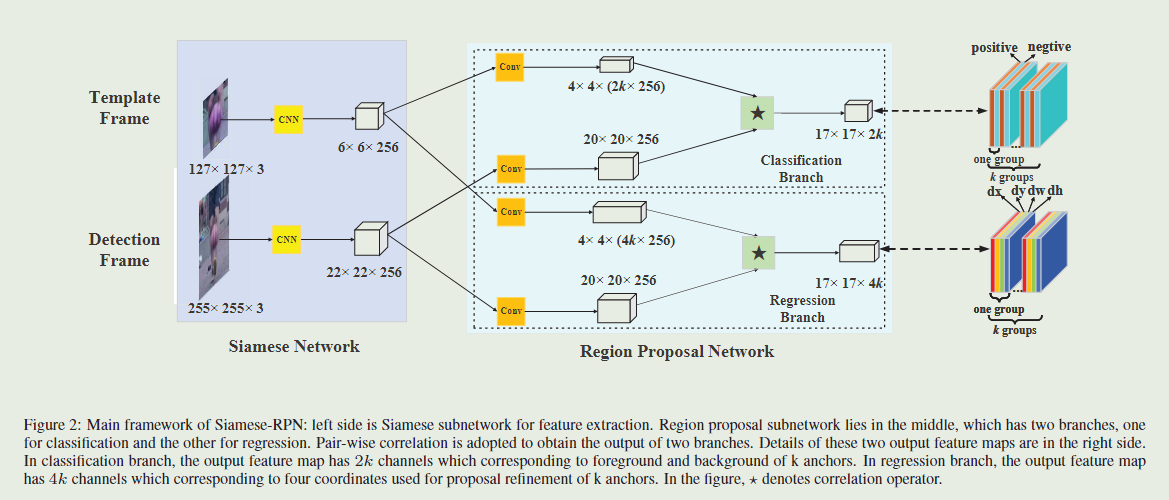
网络输入模板图像为 127 × 127 127×127 127×127,搜索图像为 255 × 255 255×255 255×255,两个图像经过CNN分别生成 6 × 6 × 256 6×6×256 6×6×256 和 22 × 22 × 256 22×22×256 22×22×256 的featuremap。之后分别将两个featuremap复制到分类分支和回归分支中,注意这里的卷积的权重是不共享的。
在分类分支中,模板featuremap和搜索featuremap经过卷积层分别输出 4 × 4 × ( 2 k × 256 ) 4×4×(2k×256) 4×4×(2k×256)和 20 × 20 × 256 20×20×256 20×20×256的featuremap,这里 k k k 为每个grid生成 k k k 个anchors,anchors的长宽比为[0.33,0.5,1,2,3],图中 ‘ ⋆ \star ⋆’ 是卷积的操作,两个featuremap相互卷积,这里先256个通道相互卷积,加权求和生成一个通道,所以生成 17 × 17 × 2 k 17×17×2k 17×17×2k的featuremap,这里相当于将搜索图像划分为 17 × 17 17×17 17×17 个grid,每个grid生成 k k k 个anchors,每两个通道是一组,一共k组对应k个anchors。第一个通道中,目标的anchors是1,背景是0;第二个通道中,背景是1,目标是0。
在回归分支中,两个featuremap经过卷积层分别生成 4 × 4 × ( 4 k × 256 ) 4×4×(4k×256) 4×4×(4k×256)和 20 × 20 × 256 20×20×256 20×20×256,这里 k k k 为每个grid生成k个anchors, ‘ ⋆ \star ⋆’ 是卷积的操作,与分类分支的操作相同,生成 17 × 17 × 4 k 17×17×4k 17×17×4k 的featuremap,每四个是一组,一共 $k 组对应 组对应 组对应k$个anchors。四组分别对应boundingbox的四个值dx、dy、dw、dh,是anchor与真值的距离。
模型创新:
区域创新:
为了使单目标检测框架适合于跟踪任务,作者提出了两种选择方案的策略。
第一个区域选择策略是丢弃anchors产生的边界框,该边界框离中心太远。例如,我们只将中心
g
×
g
g×g
g×g子区域保留在
A
w
×
h
×
2
k
c
l
s
A^{cls}_{w×h×2k}
Aw×h×2kcls 分类特征图上,以获取
g
×
g
×
k
g×g×k
g×g×k个anchors,而不是
m
×
n
×
k
m×n×k
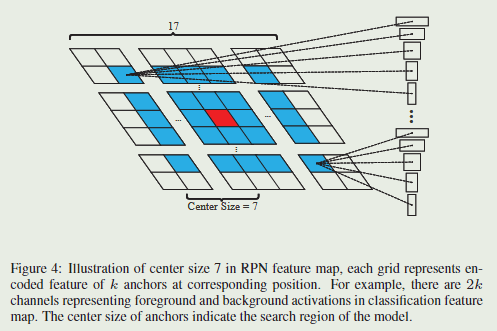
m×n×k(这里是17×17×k)个anchors。由于相邻帧总是没有大的运动,因此丢弃策略可以有效地去除异常值。下图是在分类特征图中选择距离中心不超过7的目标anchors的图示。
第二种方案选择策略是使用余弦窗并通过尺度转换惩罚对提案的得分进行重新排序,以获得最佳分数。丢弃异常值后,添加汉明窗以抑制大位移:
hanning = np.hanning(score_size)
window = np.outer(hanning, hanning)
window = np.tile(window.flatten(), self.anchor_num)
然后添加惩罚以抑制尺寸和比率的大变化:
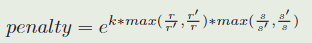
其中 r r r 和$r ′代表第一帧和最后一帧的长宽比, ′代表第一帧和最后一帧的长宽比, ′代表第一帧和最后一帧的长宽比,s$ 和 s ′ s' s′代表第一帧和最后一帧的总体规模,公式中的 k k k 是一个超参数。
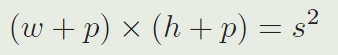
其中, w w w 和 h h h 表示目标的宽和高, p p p 表示padding,它等于 w + h 2 \frac{w+h}{2} 2w+h ,在这些操作之后,前 K K K个proposals被重新排序,在将分类得分乘以时间上的惩罚分后。(排序是由分类得分乘以时序惩罚函数之后的结果来进行的) 在得到最后的追踪bbox之后,执行非极大值抑制(NMS)。在最终的bbox被选择之后,目标的尺寸被通过使用线性内插来更新,为了保证形状平滑的被改变。
anchors的选择:
由于目标在两个相邻框架内的比例变化不大,所以在固定锚的比例时,作者只考虑锚的不同比例。尝试三种比率,[0.5,1,2]、[0.33,0.5,1,2,3]、[0.25,0.33,0.5,1,2,3,4] (分别表示为
A
3
A_3
A3,
A
5
A_5
A5,
A
7
A_7
A7)。
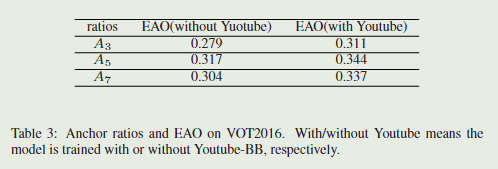
如下表所示。
A
5
A_5
A5跟踪器的性能优于
A
3
A_3
A3跟踪器,因为通过更多的锚来预测高宽比大的目标形状更容易。然而,
A
7
A_7
A7跟踪器无法持续改善性能,作者认为这可能是由于过度使用长宽比造成的。当添加更多Youtube-BB的培训数据时,
A
7
A_7
A7和
A
5
A_5
A5之间的EAO差距从0.013减小到0.007。
摘要:
主要讲述目前大部分深度学习算法无法达到高速和准确同时兼顾,本文的SiamRPN利用大量训练图片实现端对端的离线训练,通过孪生网络进行特征提取,RPN网络进行分类和回归操作。在实际跟踪阶段,可以视为单样本目标检测过程(one-shot detection),我们可以预先计算Siamese子网络的模板分支,并将相关层表示为琐屑卷积层来进行在线跟踪。通过改进方案,可以摒弃传统的多尺度测试和在线微调。
1、Introduction
主要介绍目标检测的难点在于目标受光照、变形、遮挡等因素干扰,同时实时速度是考虑的重点。
现代追踪器大致可分为两大分支。第一个分支是基于相关滤波器,它利用循环相关的性质在傅里叶域中进行运算来训练回归函数。另一个分支的方法旨在使用非常强的深度特征,不更新模型。
本文SiamRPN通过离线训练,分为两个分支:模版分支(template branch)和检测分支(detection branch)。个人理解是模版分支通过预训练encode目标特征,相当于模版分支的作用是,给定一张图片,我们可以获取这个图片中目标的特征信息。然后在跟踪过程中,模版分支通过输入第一帧的图像作为模版获取其特征信息,将该特征信息作为RPN网络的 k e r n e l kernel kernel 放到检测分支中以提取对应的检测目标的位置信息。这个过程即是one-shot detection,即只用第一帧的图像作为标准,实现一段视频后续的每一帧的目标的跟踪检测。
本文指出SiamRPN能够在三个Benchmark中达到 l e a d i n g leading leading p e r f o r m a c e performace performace 的原因有两点:1.离线训练,因此可以使用大规模的数据集(ILSVRC+Youtube-BB)2.RPN网络可以准确预测位置和边界框,避免使用多尺度检测。
随后列出三个贡献点:1.端对端离线大样本训练。2.将在线跟踪过程变为单样本检测方式,避免了多尺度检测。3.以160 FPS的速度取得领先的表现,证明了其在准确性和效率上的优势。
2、Related Works
由于本文的主要贡献是作为局部一次性检测任务的SiameseRPN,因此我们简要介绍了与我们工作相关的三个方面:基于Siamese网络结构的跟踪器、检测中的RPN和一次性学习。
2.1、Trackers based on Siamese network structure(基于Siamese网络结构的跟踪器)
Siamese 网络由两个分支组成,它将原始patches隐含地编码到另一个空间,然后将它们与特定的张量融合,产生一个单一的输出。它通常用于比较两个分支在隐含嵌入空间中的特征,特别是用于对比性任务。近年来,Siamese 网络因其精度和速度的平衡而引起了视觉跟踪界的广泛关注。与最先进的相关滤波方法相比,这些实时跟踪器的主要缺点是其不令人满意的准确性和鲁棒性。
2.2、RPN in detection(RPN网络)
最早在Faster-RCNN中提出,然后简单提了一下别的网络中的应用,以及tracking领域应用仍比较少见。
2.3、One-shot learning
近年来,深度学习中的单样本学习受到越来越多的关注。基于贝叶斯统计的方法和元学习方法是解决这一问题的两种主要方法。虽然这些基于元学习的方法已经取得了较好的效果,但这些方法通常是在分类任务上进行评估,很少有扩展到跟踪任务上。
3、Siamese-RPN framework
3.1、Siamese feature extraction subnetwork
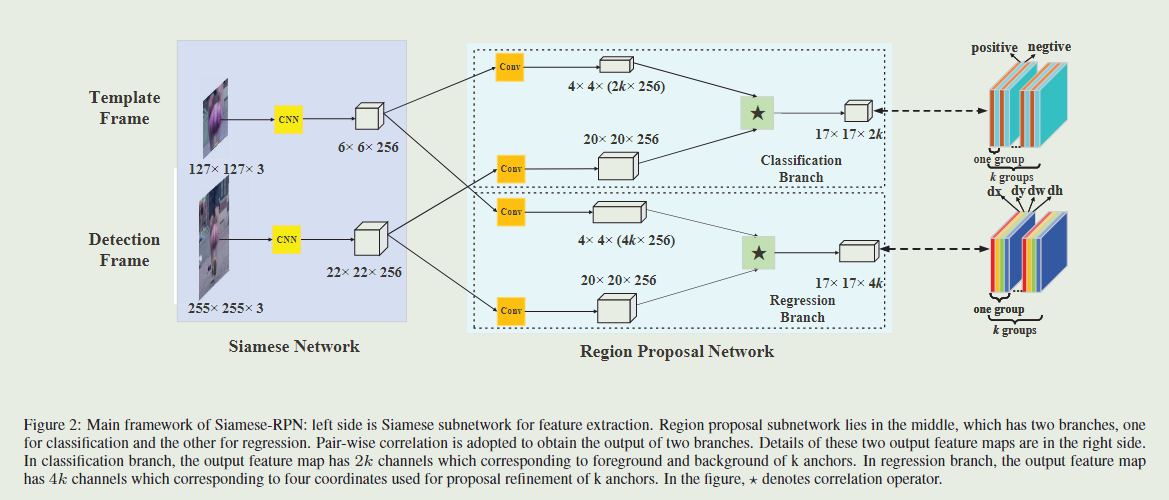
如上图的左侧部分,使用AlexNet,去掉了conv2和conv4以加速训练,分为两个分支,模板分支和检测分支共享CNN的参数,最后得到的输出分别记为 ϕ ( z ) a n d ϕ ( x ) ϕ(z) and ϕ(x) ϕ(z)andϕ(x) 。孪生特征提取子网络就是使用孪生网络提取模板分支和搜索图像分支的特征,用于后续计算。
3.2、Region proposal subnetwork
RPN子网络包含逐像素的相关部分和监督部分。监督部分有两个分支,一个用于前景背景分类,另一个用于候选区域回归。如果有 k k k个锚点,网络需要输出 2 k 2k 2k个通道来进行分类,输出 4 k 4k 4k个通道进行回归。所以,逐像素的相关部分首先通过两个卷积层增加 φ ( z ) \varphi(z) φ(z)的通道到 [ φ ( z ) ] c l s [\varphi(z)]_{cls} [φ(z)]cls和 [ φ ( z ) ] r e g [\varphi(z)]_{reg} [φ(z)]reg。φ(x)也被两个卷积层分成 [ φ ( x ) ] c l s [\varphi(x)]_{cls} [φ(x)]cls 和 [ φ ( x ) ] r e g [\varphi(x)]_{reg} [φ(x)]reg ,但是保证通道数不变。 [ φ ( z ) ] [\varphi(z)] [φ(z)] 以“组”的方式用作 [ φ ( x ) ] [\varphi(x)] [φ(x)]的相关核, [ φ ( z ) ] [\varphi(z)] [φ(z)]的组中的通道数与 φ ( x ) \varphi(x) φ(x)的通道数相同。相关操作在分类分支和回归分支上进行计算:
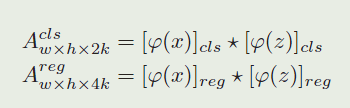
模板特征图 [ φ ( z ) ] c l s [\varphi(z)]_{cls} [φ(z)]cls和 [ φ ( z ) ] r e g [\varphi(z)]_{reg} [φ(z)]reg被用作卷积核,⋆代表卷积操作。 A w × h × 2 k c l s A_{w\times h\times 2k}^{cls} Aw×h×2kcls 中的每个点被表示为 ( w ^ , h ^ , : ) (\hat{w},\hat{h},: ) (w^,h^,:),它包含 2 k 2k 2k个通道向量,它代表原始特征图上相应位置的每个ancher的正例和负例激活 (就是用于分类这个anchor是目标还是背景)。使用softmax损失来进行分类分支的监督学习。相似地, A w × h × 4 k r e g A_{w\times h\times 4k}^{reg} Aw×h×4kreg中的每个点 ( w ^ , h ^ , : ) (\hat{w},\hat{h},: ) (w^,h^,:)包含4k kk个通道向量,表示 d x , d y , d w , d h dx,dy,dw,dh dx,dy,dw,dh,它衡量了anchor和真值之间的距离。
当使用几个anchor训练网络时,我们使用和Faster R-CNN中相同的损失函数。分类损失函数是交叉熵损失,使用smooth L 1 L1 L1 loss with normalized coordinates 进行回归。我们让 A x , A y , A w , A h A_x,A_y,A_w,A_h Ax,Ay,Aw,Ah表示anchor的中心和形状, T x , T y , T w , T h T_x,T_y,T_w,T_h Tx,Ty,Tw,Th表示真值框,正则化距离是 (中心的位移,宽高的缩放对数比例。):
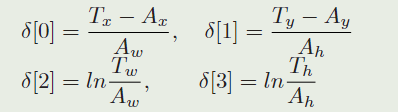
则smooth L 1 L1 L1 loss可以被写作:
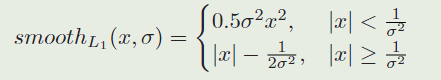
最终我们优化损失:
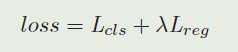
其中 λ \lambda λ是用来平衡两部分的超参数。 L c l s L_{cls} Lcls是交叉熵损失, L r e g L_{reg} Lreg 是
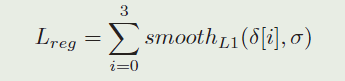
3.3、Training phase: End-to-end train Siamese-RPN
这里提到由于视频跟踪过程中目标大小并不会有很大改变,因此只采用一种尺度的anchor,其ratio分别为[0.33,0.5,1,2,3]五种。其次IOU>0.6记为正样本,IOU<0.3记为负样本。
4、Tracking as one-shot detection
这一小节中,我们首先将追踪任务形式化为一个局部检测任务。然后,对这种解释下的推理阶段进行了详细分析和简化,以加快速度。最后,引入一些特定策略来使这一框架适用于追踪任务。
4.1、Formulation
在有的论文中,我们将one-shot检测任务看作一个判别任务。它的目标是找到参数 W W W,使预测函数 ψ ( x ; W ) \psi(x;W) ψ(x;W)的平均损失 L \mathcal{L} L最小化。它是在由 n n n个样本$ x_i$和对应的标签 ℓ i \ell_{i} ℓi 组成的数据集上计算的:
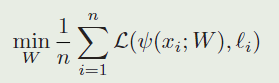
(对样本 x i x_i xi,在参数为 W W W的情况下,通过预测函数 ψ \psi ψ,得到预测值 ( ψ ( x i ; W ) (\psi\left(x_{i} ; W\right) (ψ(xi;W),然后计算和真实标签的损失 L \mathcal{L} L,计算在整个数据集上的均值,得到平均损失)
One-shot学习旨在从一个感兴趣模板 z z z中学习 W W W。判别式one-shot学习的挑战是找到一个机制来使用学习器中的类别信息,例如,learning to learn。为了解决这一挑战,我们提出了一种方法使用meta-learning过程从一个单独模板 z z z 中学习预测器的参数 W W W ,例如,一个前向传播函数 ω \omega ω,它能将 ( z ; W ′ ) (z;W' ) (z;W′)映射到 W W W 。让 z i z_i zi 作为一个bacth里的模板样本,问题能够被形式化为:
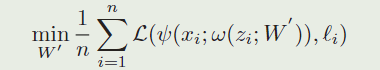
(就是将原来的参数W,变成了从模板 z i z_i zi中映射出来的,这个映射是 ω ( z i ; W ′ ) \omega\left(z_{i} ; W^{\prime}\right) ω(zi;W′);然后进一步用孪生网络的形式对函数进行表示,就得到再下一步的形式化表示)
与上面的公式相同,让 z z z表示模板patch, x x x表示检测patch,函数 φ \varphi φ表示孪生特征提取子网络,函数 ζ \zeta ζ表示区域提取子网络,然后one-shot检测任务能够被形式化为:
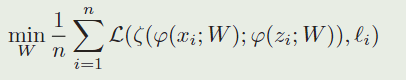
( ζ \zeta ζ是上一个公式的 ψ \psi ψ的具体化, φ \varphi φ是上一个公式中 ω \omega ω的具体化):
我们现在能够在孪生子网络里重新将模板分支解释为训练参数,来预测局部检测任务的内核,这是一个典型的learning to learn的过程。在这一解释下,模板分支用于将类别信息嵌入到内核中,而检测分支则使用嵌入的信息执行检测。在训练阶段,meta-learner除了pair-wise bbox监督以外,不需要任何其他的监督信息。在推理阶段,孪生网络被修剪为只保留初始帧之外的检测分支,从而提高了速度。从第一帧开始的目标patch被送入模板分支,并且检测内核已预先被计算好,以便我们能够在其他帧中执行one-shot检测。
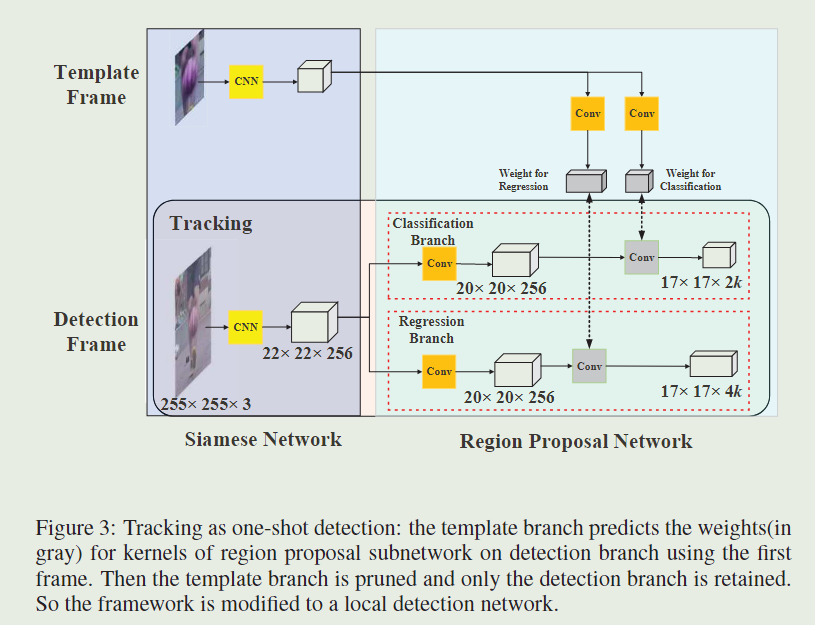
4.2、Inference phase: Perform one-shot detection
正如4.1节中形式化的一样,我们将模板分支的输出看作local detection的内核。这两个核都在初始帧中提前计算好,然后在整个追踪阶段都固定住。利用当前特征图和预先计算的内核进行卷积,检测分支将在线推理作为one-shot detection,正如Fig.3所示的。执行检测分支上的前向传播以获得分类和回归输出,从而获得前M个候选区。具体而言,在这们定义了Eq.2之后,我们将分类和回归特征图视为一个点集(在实现的过程中$ (x,y)$这两个信息可以由坐标的网格来隐式的表示):
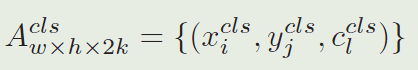
其中 i ∈ [ 0 , w ) , j ∈ [ 0 , h ) , l ∈ [ 0 , 2 k ) i\in[0,w),j\in[0,h),l\in[0,2k) i∈[0,w),j∈[0,h),l∈[0,2k)。
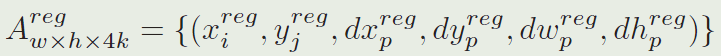
其中 i ∈ [ 0 , w ) , j ∈ [ 0 , h ) , p ∈ [ 0 , k ) i\in[0,w),j\in[0,h),p\in[0,k) i∈[0,w),j∈[0,h),p∈[0,k)
那么在得到 17 × 17 × 2 k 17\times17\times2k 17×17×2k和 17 × 17 × 4 k 17\times17\times4k 17×17×4k 的feature map之后,如何计算proposals呢:
由于分类特征图上的奇数通道表示正的激活,我们收集 A w × h × 2 k c l s A_{w \times h \times 2 k}^{c l s} Aw×h×2kcls中奇数位置的前 K K K个点其中 l l l是奇数,将这个点集表示为 C L S ∗ = ( x i c l s , y j c l s , c l c l s ) i ∈ I , j ∈ J , l ∈ L CLS^{*}={(x_i^{cls},y_j^{cls},c_l^{cls})_{i∈I,j∈J,l∈L}} CLS∗=(xicls,yjcls,clcls)i∈I,j∈J,l∈L, I , J , L I,J,L I,J,L是一些索引集 ( I , J , L I,J,L I,J,L就是那些奇数位置上的前 K K K个点)。变量 i i i和 j j j分别编码对应anchor的位置, l l l编码对应anchor的比例,所以我们能够得到对应的anchor集为 A N C ∗ = ( x i a n , y j a n , w l a n , h l a n ) i ∈ I , j ∈ J , l ∈ L ANC^{∗}={(x_i^{an},y_j^{an},w_l^{an},h_l^{an})_{i∈I,j∈J,l∈L}} ANC∗=(xian,yjan,wlan,hlan)i∈I,j∈J,l∈L。另外,我们发现在 A w × h × 2 k c l s A_{w \times h \times 2 k}^{c l s} Aw×h×2kcls上的 A N C ∗ ANC^* ANC∗的激活能够得到相应的精调坐标为 R E G ∗ = { x i r e g , y i r e g , d x l r e g , d y l r e g , d w l r e g , d h l r e g i ∈ I , j ∈ J , l ∈ L } REG^∗=\lbrace x_i^{reg},y_i^{reg},dx_l^{reg},dy_l^{reg},dw_l^{reg},dh_l^{reg}i∈I,j∈J,l∈L\rbrace REG∗={xireg,yireg,dxlreg,dylreg,dwlreg,dhlregi∈I,j∈J,l∈L}。后,精调的前K KK个候选区域集 P R O ∗ = { x i p r o , y i p r o , w l p r o , h l p r o } PRO^*=\left\{x_i^{pro},y_i^{pro},w_l^{pro},h_l^{pro}\right\} PRO∗={xipro,yipro,wlpro,hlpro}能够由以下等式获得:
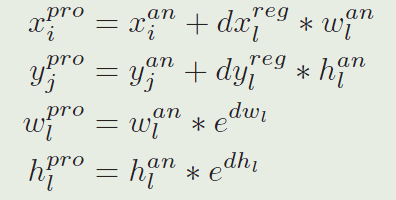
(这样计算的原理估计是:网络预测的 A w × h × 4 k A_{w\times h \times 4k} Aw×h×4k是每个位置的锚点与真实值的锚点(中心位移,宽高的缩放对数比),通过上面的计算,对这样的预测表示进行还原,就可以得到每个位置的预测bbox,包括中心坐标和bbox的尺寸)
在生成前 K K K个proposals之后,我们使用一些提议选择策略来使它们适合于追踪任务。
4.3、Proposal selection
为了使one-shot检测框架更适合于追踪任务,我们提出了两个策略来选择proposals。
第一个proposals选择策略是丢弃距离中心太远的anchor生成的边界框。例如,我们在 A w × h × 2 k c l s A_{w \times h \times 2 k}^{c l s} Aw×h×2kcls分类特征图上只保留中心 g × g g\times g g×g 的子区域来得到 g × g × k g\times g\times k g×g×k 个anchor ,而不是 m × n × k m\times n \times k m×n×k 个anchor 。因为邻近的帧总是不会有太大的运动,这个丢弃策略能有效地移除异常值。Fig.4是选择那些分类特征图上距离中心不多于7的目标anchor一个说明。
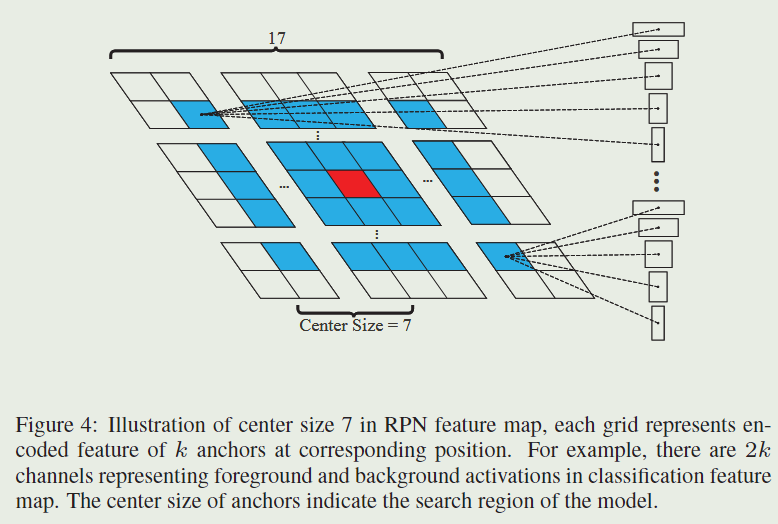
第二个proposal选择策略是我们使用consine窗口和尺度变化惩罚(scale change penalty)来重新排序proposal的得分,以便得到最好的一proposal。在异常值被丢弃以后,使用一个cosine窗口来抑制大的位移,然后使用一个penalty来抑制在尺度和比例上的巨大变化 (consine窗被用于消弱大的位移和尺度变化,有点抑制其他相似目标的感觉):
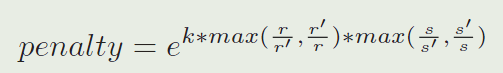
这里的 k k k 是一个超参数。 r r r 表示proposal的高宽比, r ′ r' r′ 表示表示上一帧。 s s s 和 s ′ s' s′ 表示proposal和上一帧的整体尺度,它是按下面的方法计算的:
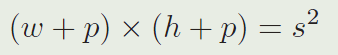
其中, w w w 和 h h h 表示目标的宽和高, p p p 表示padding,它等于 w + h 2 \frac{w+h}{2} 2w+h ,在这些操作之后,前 K K K个proposals被重新排序,在将分类得分乘以时间上的惩罚分后。(排序是由分类得分乘以时序惩罚函数之后的结果来进行的) 在得到最后的追踪bbox之后,执行非极大值抑制(NMS)。在最终的bbox被选择之后,目标的尺寸被通过使用线性内插来更新,为了保证形状平滑的被改变。
5、Experiment
实验在四个有挑战性的追踪数据集:VOT2015,VOT2016,VOT2017 real-time,和OTB2015,前三个各60个视频,最后一个有100个视频。所有的这些追踪的结果都使用报告的结果,以保证一个公平的比较。
5.1、Implementation details
5.2、Result on VOT2015
5.3、Result on VOT2016
5.4、Result on VOT2017 real-time experiment
5.5、Result on OTB2015
5.6、Discussion
在本小节中,我们将讨论几个对性能至关重要的因素,包括数据大小、锚定比和位置。
5.6.1、Data size
视频稀疏标记:
该跟踪框架只需要图像对,而不需要连续的视频流。所以可以从大规模的稀疏标记视频中获益。Youtube-BB包含超过10万个视频,每30帧注释一次。且实验表明添加来自Youttube-bb的数据可以逐步提高性能。性能不是饱和的,这意味着随着训练数据的增加,跟踪器的性能可能会变得更好。因此可以通过逐步添加更多来自Youtube-BB的数据来训练不同数据集大小的Siamese-RPN。
5.6.2、Anchor selection
比率:尝试了三种
- A3:[0.5,1,2]
- A5:[0.33,0.5,1,2,3]
- A7:[0.25,0.33,0.5,1,2,3,4]
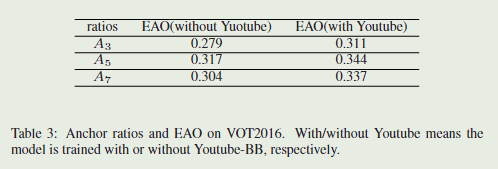
实验结果表明,A5的追踪器表现最好,虽然A7跟踪器可以通过添加更多的训练数据来减少差距,但其性能并没有持续提高,这可以是过拟合造成的。所以最终选择A5作为最终锚框比率。
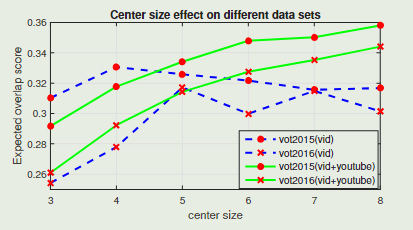
anchor position(锚位置)
实验表明,当使用Youtube-BB对网络进行训练时,随着中心尺寸的增大,性能也随之提高。但是,如果只使用ILSVRC训练,RPN的性能并没有像预期的那样提高,这意味着RPN的判别能力不足以使用大的搜索区域。
6、Conclusion
在这项工作中,提出了一个孪生区域提议网络(Siamese-RPN),该网络通过ILSVRC和YoutubeBB的大规模图像对进行了端到端的离线训练。Siamese-RPN可以通过应用box refinement procedure来获得更准确的边界框。在在线追踪时,提出的构架被形式化为一个局部one-shot检测任务。在实验中,该方法可以在160 FPS下运行,在VOT2015,VOT2016和VOT2017实时挑战中达到领先的性能。
目标检测与目标跟踪的异同:
目标检测实现已知类别的定位识别,而目标跟踪可以根据运动特征来进行跟踪,无需知道跟踪的是什么。如果对每帧画面进行目标检测可以实现目标追踪,但计算十分昂费耗时。















 8483
8483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









