







 文章提出了AiATrack,一个基于Transformer的视觉跟踪框架,通过AttentioninAttention(AiA)模块改善注意机制,解决传统方法中噪声和模糊注意权重的问题。AiA模块增强了相关性并抑制错误相关性,从而提高跟踪性能。此外,框架利用特征重用和目标背景嵌入有效利用时间信息。
文章提出了AiATrack,一个基于Transformer的视觉跟踪框架,通过AttentioninAttention(AiA)模块改善注意机制,解决传统方法中噪声和模糊注意权重的问题。AiA模块增强了相关性并抑制错误相关性,从而提高跟踪性能。此外,框架利用特征重用和目标背景嵌入有效利用时间信息。
AiATrack: Attention in Attention for Transformer Visual Tracking
论文地址:https://arxiv.org/pdf/2207.09603
动机:
注意机制中的独立相关计算可能会导致噪声和模糊的注意权重,这阻碍了性能的进一步提高。为了解决这个问题,我们提出了注意中的注意(AIA)模块,它通过在所有相关向量之间寻求共识来增强适当的相关性并抑制错误的相关性。AiA模块可以很容易地应用于自注意块和交叉注意块,以促进视觉跟踪的特征聚合和信息传播。此外,提出了一个流线型的Transformer跟踪框架,称为AiATrack,通过引入有效的特征重用和目标背景嵌入来充分利用时间引用。
贡献:
- 提出了一种新的注意中的注意(AiA)模块,它可以减轻传统注意机制中的噪声和模糊性,并显著提高跟踪性能。
- 提出了一个简洁的Transformer跟踪框架,该框架重用了编码特征,并引入了目标-背景嵌入,以有效地利用时间引用。
1、Method
1.1、Attention in Attention
首先简要回顾视觉中的传统注意块,如图 2(a) 所示,它以查询和一组键值对作为输入并生成输出,该输出是值的加权和。分配给值的权重是通过取查询和相应键之间缩放点积的 $softmax $ 来计算的。
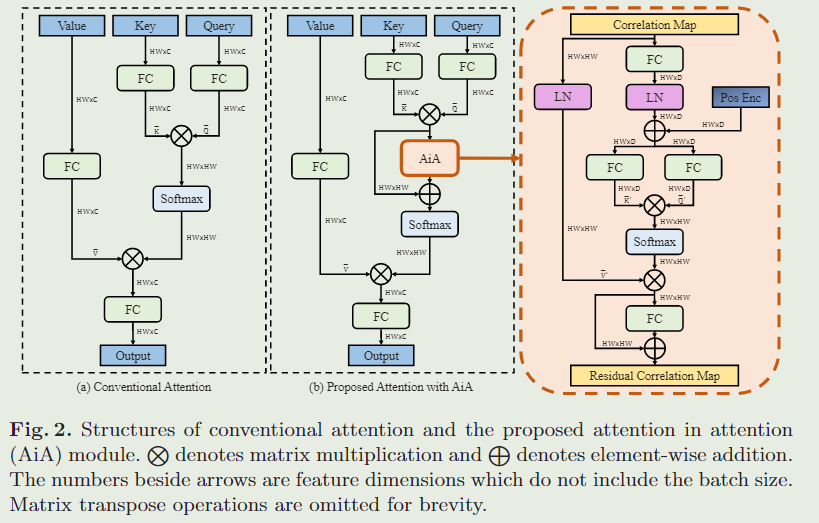
分别用 Q 、 K 、 V ∈ R H W × C Q、K、V∈R^{HW×C} Q、K、V∈RHW×C表示查询、键和值。传统的注意力可以表示为:
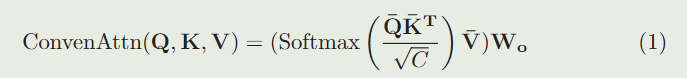
其 Q ‾ = Q W q , K ‾ = K W k , V ‾ = V W v \overline{Q}=QW_q,\overline{K}=KW_k,\overline{V}=VW_v Q=QWq,K=KWk,V=VWv是不同的线性变换。这里, W q 、 W k 、 W v 和 W o W_q、W_k、W_v和W_o Wq、Wk、Wv和Wo分别表示查询、关键字、值和输出的线性变换权重。
然而,在传统的关注块中,关联映射 M = Q ‾ K ‾ T C ∈ R H W × H W M=\frac{\overline{Q}\overline{K}^T}{\sqrt{C}}\in R^{HW\times HW} M=CQKT∈RHW×HW中每个查询关键字对的相关性是独立计算的,这忽略了其他查询关键字对之间的相关性。这种相关计算过程可能会由于不完美的特征表示或在背景杂波场景中存在分散的图像补丁而引入错误的相关性。如图4所示,这些错误的关联可能导致嘈杂和模糊的注意。
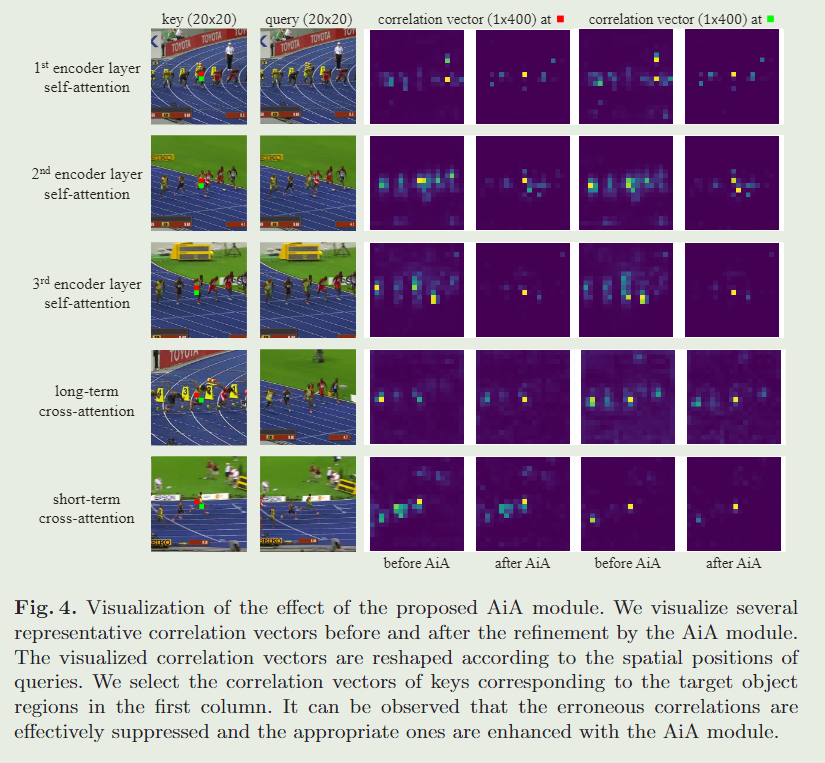
它们可能对自注意中的特征聚合和交叉注意中的信息传播产生不利影响,导致Transformer跟踪器的性能不理想。
为了解决上述问题,我们提出了一种新的注意中注意(AIA)模块来提高相关图M的质量。通常,如果一个键与查询有高相关性,那么它的一些相邻键也将与该查询有相对高的相关性。否则,这种相关性可能是一种噪音。受此启发,我们引入了AIA模块来利用M中相关性之间的信息线索。提出的 AiA 模块寻求每个键之间的相关性一致性,以增强相关查询键对的适当相关性并抑制不相关查询键对的错误相关性。
具体地说,我们引入了另一个注意模块来在Softmax操作之前提炼相关图M,如图2(b)所示。
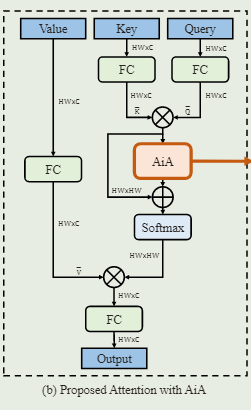
随着新引入的注意模块被插入到传统的注意块中,我们称之为内部注意模块,在注意力结构中形成注意力。内部注意力模块本身是传统注意力的一种变体。我们将 $M $中的列视为一系列相关向量,这些向量由内部注意模块作为查询 Q ′ Q' Q′、键 K ′ K' K′ 和值 V ′ V' V′ 以输出残差相关图。
给定输入 Q ′ , K ′ , V ′ Q',K',V' Q′,K′,V′,我们首先生成转换后的查询 Q ‾ ′ \overline{Q}' Q′ 和键 K ‾ ′ \overline{K}' K′,如图 2(b) 的右侧块所示。
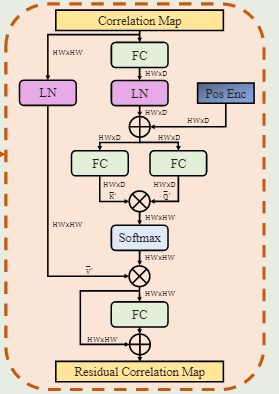
具体来说,首先应用线性变换将 Q ′ Q' Q′和 K ′ K' K′ 的维度减少到 H W × D ( D ≪ H W ) HW×D(D≪HW) HW×D(D≪HW),以提高效率。在归一化之后,我们添加了二维正弦编码来提供位置线索。然后 Q ‾ ′ , K ‾ ′ \overline{Q}',\overline{K}' Q′,K′由两个不同的线性变换生成。我们还规范化 V ′ V' V′以生成归一化相关向 V ‾ ′ \overline{V}' V′ ,即 V ‾ ′ = L a y e r N o r m ( V ’ ) \overline{V}'=LayerNorm(V’) V′=LayerNorm(V’)。使用 Q ‾ ′ , K ‾ ′ , V ‾ ′ \overline{Q}',\overline{K}',\overline{V}' Q′,K′,V′ ,内部注意模块生成一个残差相关图,如下:
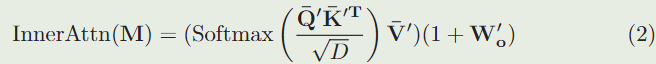
其中 W o ′ W'_o Wo′ 表示线性变换权重,用于调整聚合相关性以及相同的连接。
本质上,对于相关图 M 中的每个相关向量,AiA 模块通过聚合原始相关向量来生成其残差相关向量。这可以看作是寻求与全局感受野的相关性的共识。通过残差相关图,我们的带有 AiA 模块的注意块可以表述为:
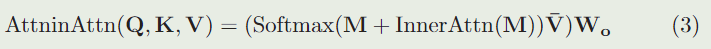
对于多头注意力块,我们在并行注意力头之间共享 AiA 模块的参数。
1.2、Proposed Framework
使用所提出的 AiA 模块,设计了一个简单而有效的视觉跟踪 Transformer 框架,称为 AiATrack。的跟踪器由网络主干、Transformer 架构和两个预测头组成,如图 3 所示。
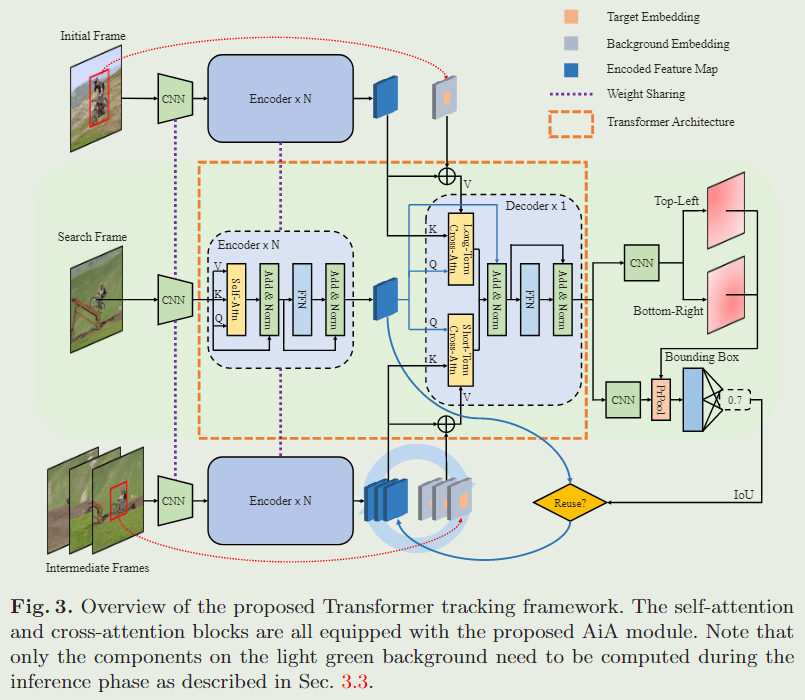
在给定搜索帧的情况下,将初始帧作为长期参考,将多个中间帧的集合作为短期参考。网络主干提取长、短期参考和搜索帧的特征,然后用Transformer编码器对其进行增强。我们还引入了可学习的目标-背景嵌入,以区分目标和背景区域。Transformer解码器将参考特征以及目标-背景嵌入映射传播到搜索帧。然后将 Transformer 的输出分别馈送到目标预测头和用于目标定位和短期参考更新的 IoU 预测头。
Transformer Architecture
采用 Transformer 编码器来加强卷积主干提取的特征。对于搜索帧,我们对其特征进行展平以获得特征向量序列,并添加正弦位置编码。然后,Transformer 编码器将特征向量序列作为其输入。Transformer 编码器由几个层堆栈组成,每个堆栈由多头自注意力块和前馈网络组成。自注意力块用于捕获所有特征向量之间的依赖关系以增强原始特征,并配备所提出的 AiA 模块。
Transformer 解码器将来自长期和短期参考的参考信息传播到搜索框架。为简单起见,我们去掉了自注意力块,并引入了如图 3 所示的双分支交叉注意力设计来从长期和短期参考中检索目标背景信息。长期分支负责从初始帧检索参考信息。由于初始帧对跟踪目标的注释最可靠,因此鲁棒视觉跟踪至关重要。但是来自长期分支的参考信息可能不是最新的。这可能会导致跟踪器在某些场景中漂移。为了解决这个问题,我们引入了短期分支来利用来自更接近当前帧的帧的信息。两个分支的交叉注意块具有相同的结构,遵循Vanilla Transformer 中的查询键值设计。我们以搜索帧的特征作为查询,以参考帧的特征作为关键字。这些值是通过将参考特征与目标-背景嵌入地图相结合来生成的。将 AiA 模块插入到交叉注意力中以获得更好的参考信息传播。
Target-Background Embeddings.
为了在保留上下文信息的同时指示目标区域和背景区域,我们引入了一个目标嵌入$ \varepsilon{tgt}∈RC $和背景嵌入 $ \varepsilon{bg}∈RC$,这两者都是可学习的。使用 $ \varepsilon{tgt}∈RC $和 $ \varepsilon{bg}∈RC$,我们为参考帧生成目标背景嵌入图 $ \varepsilon∈R^{HW\times X} ,计算成本可以忽略不计。让我们考虑 ,计算成本可以忽略不计。让我们考虑 ,计算成本可以忽略不计。让我们考虑 H × W$ 网格中的位置 p p p,嵌入分配公式为

之后,我们将目标-背景嵌入图附加到参考特征,并将它们馈送到交叉注意力块作为值。目标背景嵌入图通过提供上下文线索来丰富重用的外观特征。
Prediction Heads
如上所述,我们的跟踪器有两个预测头。目标预测头取自STARK,具体来说,解码的特征被输入到双分支全卷积网络中,该网络输出目标边界框左上角和右下角的两个概率图。然后通过计算两个角的概率分布的期望来获得预测的框坐标。
为了使模型适应跟踪过程中的出现变化,跟踪器需要通过选择包含目标的可靠参考来不断更新短期参考。此外,考虑到我们在Eq. 4中的嵌入分配机制,所选参考帧的边界框应尽可能准确。
受IoU-Net和ATOM的启发,对于每个预测的边界框,我们通过 IoU 预测头估计其与真实情况的 IoU。预测边界框内的特征被传递到精确的 RoI 池化层,其输出由全连接网络获取以产生 IoU 预测。然后使用预测的 IoU 来确定是否将搜索框架包含为新的短期参考。
我们联合训练两个预测头。目标预测的损失由预测边界框和基本事实之间的 GIoU 损失 和 L1 损失的组合定义。IoU预测头的训练示例是通过对ground truth周围的边界框进行采样来生成的。IoU预测的损失由均方误差定义。
1.3、Tracking with AiATrack
给定带有ground truth注释的初始帧,我们通过裁剪初始帧作为长期和短期参考来初始化跟踪器,并预先计算它们的特征和目标-背景嵌入图。对于每个后续帧,我们估计目标预测头预测的边界框的 IoU 分数以进行模型更新。更新过程比以前的工作更有效,因为我们直接重用了编码的特征。具体来说,如果预测边界框的估计 IoU 分数高于预定义的阈值,我们为当前搜索帧生成目标-背景嵌入图,并将嵌入图存储在内存缓存中及其编码特征。对于每个新出现的帧,我们统一采样几个短期参考帧,并将它们的特征和嵌入映射从内存缓存连接起来,以更新短期参考集成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









