







Learning Spatio-Temporal Transformer for Visual Tracking
论文地址:https://arxiv.org/pdf/2103.17154
贡献:
1、我们提出了一种新的致力于视觉跟踪的Transformer架构。它能够捕获视频序列中空间和时间信息的全局特征依赖关系。
2、整个方法是端到端的,不需要余弦窗、包围盒平滑等后处理步骤,大大简化了现有的跟踪流水线。
动机:
卷积核不能很好地建模图像内容和特征的长期依赖关系,因为它们只在空间和时间上处理局部邻域。目前流行的追踪器,包括离线的孪生追踪器和在线学习模型,几乎都是建立在卷积运算的基础上。
空间信息和时间信息对于目标跟踪都是重要的。前者包含用于目标定位的对象外观信息,而后者包含对象跨帧的状态变化。
在这项工作中,考虑到全局依赖模型的优越能力,采用transformer来整合时空信息进行跟踪,生成可区分的时空特征用于目标定位。
基本方法:
我们首先介绍了一种简单的基线方法,它直接利用原始的encoder-decoder transformer进行跟踪;该基线方法只考虑了空间信息,取得了令人印象深刻的效果。之后,我们将基线扩展到学习目标定位的空间和时间表征。引入了动态模板和更新控制器来捕捉目标对象的外观变化。
1、A Simple Baseline Based on Transformer
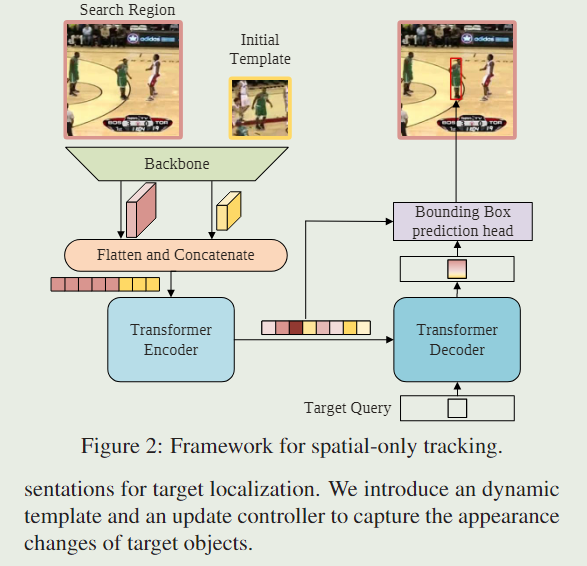
Backbone:
我们的方法可以使用任意卷积网络作为特征提取的主干。在保持通用性的前提下,我们采用了Vanilla ResNet作为主干。更具体地说,除了移除最后一级和完全连接的层外,原始ResNet没有其他更改。
Encoder:
主干的输出特征图在输入编码器之前需要预处理。具体来说,首先使用瓶颈层将通道数从 C 减少到 d。然后将特征地图沿空间维度进行展平和拼接,生成长度为 H z s W z s + H x s W x s \frac{H_z}{s}\frac{W_z}{s}+\frac{H_x}{s}\frac{W_x}{s} sHzsWz+sHxsWx、维度为d的特征序列,作为transformer编码器的输入。
编码器捕获序列中所有元素之间的特征依赖关系,并用全局上下文信息加强原始特征,从而允许模型学习用于目标定位的判别特征。
Decoder:
解码器以目标查询和编码器的增强特征序列作为输入。只在解码器中输入一个查询来预测目标对象的一个包围盒。
与编码器类似,解码器堆叠M个解码层,每个层由自我关注、编解码者关注和前馈网络组成。
在编码器-解码器注意力模块中,目标查询可以关注模板和搜索区域特征上的所有位置,从而为最终的边界框预测学习稳健的表示。
Head:
为了提高盒子估计的质量,通过估计盒子角点的概率分布,设计了一种新的预测头。

我们首先从编码器的输出序列中提取搜索区域特征,然后计算搜索区域特征与解码输出嵌入的相似度。接下来,将相似度分数与搜索区域特征进行元素级相乘,以增强重要区域并削弱较不具区分性的区域。
新的特征序列被重塑为 f ∈ R d × H s s × W s s f\in{R^{d\times{\frac{H_s}{s}\times{\frac{W_s}{s}}}}} f∈Rd×sHs×sWs的特征映射,然后馈入简单的全卷积网络。FCN 由 L 个堆叠的 Conv-BN-ReLU 层组成,并输出对象边界框左上角和右下角的两个概率图 P t l ( x , y ) 和 P b r ( x , y ) P_{tl}(x,y)和P_{br}(x,y) Ptl(x,y)和Pbr(x,y),
最后,通过计算角概率分布的期望得到预测框坐标 ( x t l ^ , y t l ^ ) 和 ( x b r ^ , y b r ^ ) (\hat{x_{tl}},\hat{y_{tl}})和(\hat{x_{br}},\hat{y_{br}}) (xtl^,ytl^)和(xbr^,ybr^),如式(1)所示:

Training and Inference
我们的基线跟踪器以端到端的方式进行训练,结合了 l 1 l1 l1 Loss和广义 I o U IoU IoU 损失 ,如 DETR 所示。损失函数可以写为:
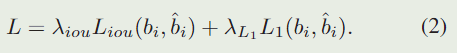
在推理过程中,模板图像及其主干的特征由第一帧初始化,并在随后的帧中固定。
在跟踪过程中,在每一帧中,网络将来自当前帧的搜索区域作为输入,并返回预测框作为最终结果,而不使用余弦窗口或边界框平滑等任何后处理。
2、Spatio-Temporal Transformer Tracking
由于目标对象的外观可能会随着时间的进行而显着变化,因此捕获目标的最新状态以进行跟踪很重要。
有三个关键的区别跟基线方法,包括网络输入,一个额外的分数头,以及训练和推理策略。

Input:
与仅使用第一帧和当前帧的基线方法不同,时空方法引入了从中间帧采样的动态更新模板作为附加输入,如图4所示。除了初始模板的空间信息外,动态模板还可以捕捉目标外观随时间的变化,提供额外的时间信息。该编码器通过在空间和时间维度上对所有元素之间的全局关系进行建模来提取可区分的时空特征。
Head:
在跟踪过程中,有些情况下不应该更新动态模板。例如,当目标被完全遮挡或移出视野时,或者当跟踪器漂移时,裁剪模板是不可靠的。只要搜索区域包含目标,就可以更新动态模板。为了自动确定当前状态是否可靠,我们添加了一个简单的分数预测头,它是一个三层感知器,后跟一个 sigmoid 激活。
Trainning and Inference
我们将训练过程分为两个阶段,将定位作为主要任务,将分类作为次要任务。
具体来说,在第一阶段,除了分数头外,整个网络都是端对端训练,只使用Eq. 2中与定位相关的损失。在这个阶段,我们确保所有的搜索图像都包含目标对象,并让模型学习定位能力。在第二阶段,仅利用定义为如下的二进制交叉熵损失来优化分数头:

这样,最终模型在两阶段训练后同时学习定位和分类能力。















 1897
1897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









