







Transforming Model Prediction for Tracking
论文地址:https://arxiv.org/pdf/2203.11192
动机:
基于优化的跟踪方法通过整合目标模型预测模块已被广泛成功,通过最小化目标函数来提供有效的全局推理。虽然这种归纳偏差整合了有价值的领域知识,但它限制了跟踪网络的表达能力。
因此,在这项工作中,提出了一种使用基于 Transformer 的模型预测模块的跟踪器架构。
Transformer 捕捉全局关系时几乎没有归纳偏差,使其能够学习更强大的目标模型的预测。我们进一步扩展模型预测器以估计第二组权重,这些权重被应用于精确的包围盒回归。
DCF的目标函数整合了前一帧的前景和背景知识,在学习模型时提供有效的全局推理。然而,它也会对预测的目标模型施加严重的归纳偏差。由于目标模型是通过对前几帧的目标进行最小化而获得的,因此模型预测器的灵活性有限。例如,它不能在预测目标模型中集成任何学习的先验。
我们的方法采用了一个紧凑的目标模型来定位目标,就像DCF中一样。然而,这个模型的权重是使用基于Transformer的模型预测器获得的,与DCF相比,允许我们学习更强大的目标模型。
贡献:
- 提出了一种新颖的基于 Transformer 的模型预测模块,以替换传统的基于优化的模型预测器。
- 对模型预测器进行扩展,以估计用于包围盒回归的第二组权重。
- 在测试时提出了一个并行的两阶段跟踪过程来解耦目标定位和边界框回归,以实现稳健准确的目标检测。
1、Method
1.1、Backgroud
视觉目标跟踪的流行范式之一是基于判别模型预测的跟踪。这些方法如图 2a 所示,使用目标模型来定位测试帧中的目标对象。

该目标模型的权重(参数)是使用训练框架及其注释从模型优化器中获得的。判别跟踪器有一个共同的基本公式来产生目标模型的权重。这涉及解决一个优化问题,使得目标模型为训练样本
S
train
∈
{
(
x
i
,
y
i
)
}
i
=
1
m
\mathcal{S}_{\text{train}} \in \{(x_i,y_i)\}_{i=1}^m
Strain∈{(xi,yi)}i=1m 生成所需的目标状态
y
i
∈
Y
y_i ∈Y
yi∈Y。这里,
x
i
∈
X
x_i∈\mathcal{X}
xi∈X指的是第
i
i
i帧的深度特征图,
m
m
m表示训练帧的总数。优化问题如下:
w
=
arg
min
w
~
∑
(
x
,
y
)
∈
S
t
r
a
i
n
f
(
h
(
w
~
;
x
)
,
y
)
+
λ
g
(
w
~
)
.
w=\operatorname*{arg}\operatorname*{min}_{\tilde{w}}\sum_{(x,y)\in\mathcal{S}_{\mathrm{train}}}f(h(\tilde{w};x),y)+\lambda g(\tilde{w}).
w=argw~min(x,y)∈Strain∑f(h(w~;x),y)+λg(w~).
在这里,目标由残差函数
f
f
f 组成,该函数计算目标模型输出
h
(
w
~
;
x
)
h(\tilde{w};x)
h(w~;x) 和真实标签
y
y
y 之间的误差。
g
(
w
~
)
g(\tilde{w})
g(w~) 表示由标量
λ
λ
λ 加权的正则化项,而
w
w
w 表示目标模型的最佳权重。请注意,训练集
S
t
r
a
i
n
S_{train}
Strain 包含带注释的第一帧,以及之前的跟踪帧,跟踪器的预测用作伪标签。
通过明确最小化 (1) 的目标来学习目标模型提供了一个稳健的目标模型,该模型可以将目标与以前看到的背景区分开来。然而,这种策略存在显着的局限性。基于优化的方法仅使用先前跟踪帧中可用的有限信息来计算目标模型。也就是说,它们不能将学习到的先验集成到目标模型预测中,以最小化未来的失败。类似地,当计算模型权重以提高跟踪性能时,这些方法通常缺乏以转换方式利用当前测试框架的可能性。基于优化的方法还需要设置多个优化器的超参数,并可能对训练样本进行过拟合/欠拟合。基于优化的跟踪器的另一个限制是它们产生判别特征的过程。通常,提供给目标模型的特征仅仅是提取的测试特征,而不是通过使用包含在训练帧中的目标状态信息来增强特征。提取这种增强的特征将允许在测试帧中的目标区域和背景区域之间进行可靠的区分。
1.2、Transformer-based Target Model Prediction
为了克服上述基于优化的目标定位方法的局限性,我们建议用一个基于Transformer的新型目标模型预测器来取代模型优化器(见图2b)。
与(1)中所述的显式最小化目标不同,我们的方法学习通过端到端训练直接从数据中预测目标模型。这允许模型预测器在预测模型中集成目标特定先验,从而除了允许将目标与所看到的背景区分开的特征之外,它还可以关注目标的特征特征。此外,我们的模型预测器还利用当前测试帧的特征,以及先前的训练特征,以一种转换的方式预测目标模型。因此,模型预测器可以利用当前帧信息来预测更合适的目标模型。最后,我们的方法不是将目标模型应用到由预训练的特征提取器定义的固定特征空间上,而是利用目标信息动态地为每帧构建更具判别性的特征空间。
所提出的基于 Transformer 的模型预测的跟踪器的概述如图 2b 所示。与基于优化的跟踪器类似,它由一个测试分支和训练分支组成。我们首先对训练帧中的目标状态信息进行编码,并将其与深度图像特征进行融合。类似地,我们还向测试帧添加编码,以便将其标记为测试帧。然后,来自训练和测试分支的特征在Transformer Encode中被联合处理,该编码器通过全局推理产生增强的特征。接下来,Transformer Decoder利用Transformer 编码器的输出预测目标模型权重。最后,将预测的目标模型应用到增强的测试帧特征上,对目标进行定位。
Target Location Encoding:
提出了一种目标位置编码,该编码允许模型预测器在预测目标模型时结合来自训练帧的目标状态信息。特别是,我们使用表示前景的嵌入
e
f
g
∈
R
1
×
C
e_{\mathrm{fg}}\in\mathbb{R}^{1\times C}
efg∈R1×C。再加上以目标位置为中心的高斯
y
i
∈
R
H
×
W
×
1
y_i\in\mathbb{R}^{H\times W\times1}
yi∈RH×W×1,我们定义目标编码函数
ψ
(
y
i
,
e
f
g
)
=
y
i
⋅
e
f
g
\psi(y_i,e_{\mathrm{fg}})=y_i\cdot e_{\mathrm{fg}}
ψ(yi,efg)=yi⋅efg
其中“
⋅
\cdot
⋅”表示带广播的逐点乘法。其中
H
i
m
=
s
⋅
H
,
W
i
m
=
s
⋅
W
H_{im} = s·H, W_{im} = s·W
Him=s⋅H,Wim=s⋅W分别代表图像patch的空间维度,
s
s
s代表提取深层特征的骨干网络跨距
x
∈
R
H
×
W
×
C
x \in \mathbb{R}^{H \times W \times C}
x∈RH×W×C。接下来,我们将目标编码和深度图像特征
x
x
x组合如下
v
i
=
x
i
+
ψ
(
y
i
,
e
f
g
)
v_i=x_i+\psi(y_i,e_{\mathrm{fg}})
vi=xi+ψ(yi,efg)
这为我们提供了包含编码的目标状态信息的训练帧特征
v
i
∈
R
H
×
W
×
C
v_i \in \mathbb{R}^{H \times W \times C}
vi∈RH×W×C,类似地,我们还添加了测试编码以将与测试帧相对应的特征标识为,
v
t
e
s
t
=
x
t
e
s
t
+
μ
(
e
t
e
s
t
)
,
v_{\mathrm{test}}=x_{\mathrm{test}}+\mu(e_{\mathrm{test}}),
vtest=xtest+μ(etest),
其中,
μ
(
⋅
)
μ(\cdot)
μ(⋅)对
x
t
e
s
t
x_{test}
xtest的每个patch重复标记
e
t
e
s
t
e_{test}
etest。
Transformer Encoder:
我们的目标是使用来自训练和测试帧的前景和背景信息来预测我们的目标模型。为了实现这一点,我们使用Transformer Encode模块首先联合处理来自训练帧和测试帧的特征。在我们的方法中,Transformer Encoder有两个用途。首先,如后面所述,它计算Transformer Decoder模块所用来预测目标模型的特征。其次,受STARK的启发,我们的Transformer编码器也输出增强的测试帧特征,在定位目标时作为目标模型的输入。
给定多个编码训练特征$ v_i \in \mathbb{R}^{H \times W \times C}$ 和编码测试特征 $v_{test} \in \mathbb{R}^{H \times W \times C}
,我们将特征重塑为
,我们将特征重塑为
,我们将特征重塑为\mathbb{R}^{(H\cdot W) \times C}$ 并沿第一个维度连接所有 $m $个训练特征 $v_i $和测试特征
v
t
e
s
t
v_{test}
vtest。然后,这些连接的特征在 Transformer Encoder 中联合处理
[
z
1
,
…
,
z
m
,
z
test
]
=
T
enc
(
[
v
1
,
…
,
v
m
,
v
test
]
)
.
[z_1,\ldots,z_m,z_\text{test}]=T_\text{enc}([v_1,\ldots,v_m,v_\text{test}]).
[z1,…,zm,ztest]=Tenc([v1,…,vm,vtest]).
Transformer 编码器由多头自注意力模块组成,该模块使其能够在完整帧之间进行全局推理,甚至可以跨多个训练和测试帧进行推理。此外,编码的目标状态识别前景和背景区域,并使 Transformer 能够区分这两个区域。
Transformer Decoder:
Transformer 编码器的输出(
z
i
和
z
t
e
s
t
z_i 和 z_{test}
zi和ztest)被用作 Transformer Decoder 的输入来预测目标模型权重。
w
=
T
d
e
c
(
[
z
1
,
…
,
z
m
,
z
t
e
s
t
]
,
e
f
g
)
w=T_{\mathrm{dec}}([z_1,\ldots,z_m,z_{\mathrm{test}}],e_{\mathrm{fg}})
w=Tdec([z1,…,zm,ztest],efg)
请注意,输入
z
i
z_i
zi 和
z
t
e
s
t
z_{test}
ztest 是通过对整个训练和测试样本进行联合推理获得的,使我们能够预测判别目标模型。我们使用与用于目标状态编码的相同学习前景嵌入
e
f
g
e_{fg}
efg 作为 Transformer 解码器的输入查询,以便解码器预测目标模型权重。
Target Model:
我们使用 DCF 目标模型来获得目标分类分数:
h
(
w
,
z
t
e
s
t
)
=
w
∗
z
t
e
s
t
h(w,z_{\mathrm{test}})=w*z_{\mathrm{test}}
h(w,ztest)=w∗ztest
这里,卷积滤波器
w
∈
R
1
×
C
w \in \mathbb{R}^{1\times C}
w∈R1×C 的权重由 Transformer 解码器预测。请注意,目标模型应用于 Transformer Encoder 的输出测试特征
z
t
e
s
t
z_{test}
ztest。这些特征是在训练和测试框架的联合处理后获得的,因此支持目标模型可靠地定位目标。
1.3、Joint Localization and Box Regression
在上一节中,我们介绍了基于 Transformer 的架构来预测目标模型。虽然目标模型可以定位每一帧中的对象中心,但跟踪器还需要估计目标的准确边界框。基于DCF的跟踪器通常采用专用的边界框回归网络来完成这项任务。虽然可以遵循类似的策略,但我们决定联合预测这两个模型,因为目标定位和边界框回归是可以相互受益的相关任务。为了实现这一点,扩展了的模型如下。首先,不仅在生成目标状态编码时使用目标中心位置,还对目标大小信息进行编码,为我们的模型预测器提供更丰富的输入。其次,除了目标模型权重之外,我们扩展了我们的模型预测器来估计边界框回归网络的权重。由此产生的跟踪体系结构如图3所示。接下来,我们将详细描述这些更改。
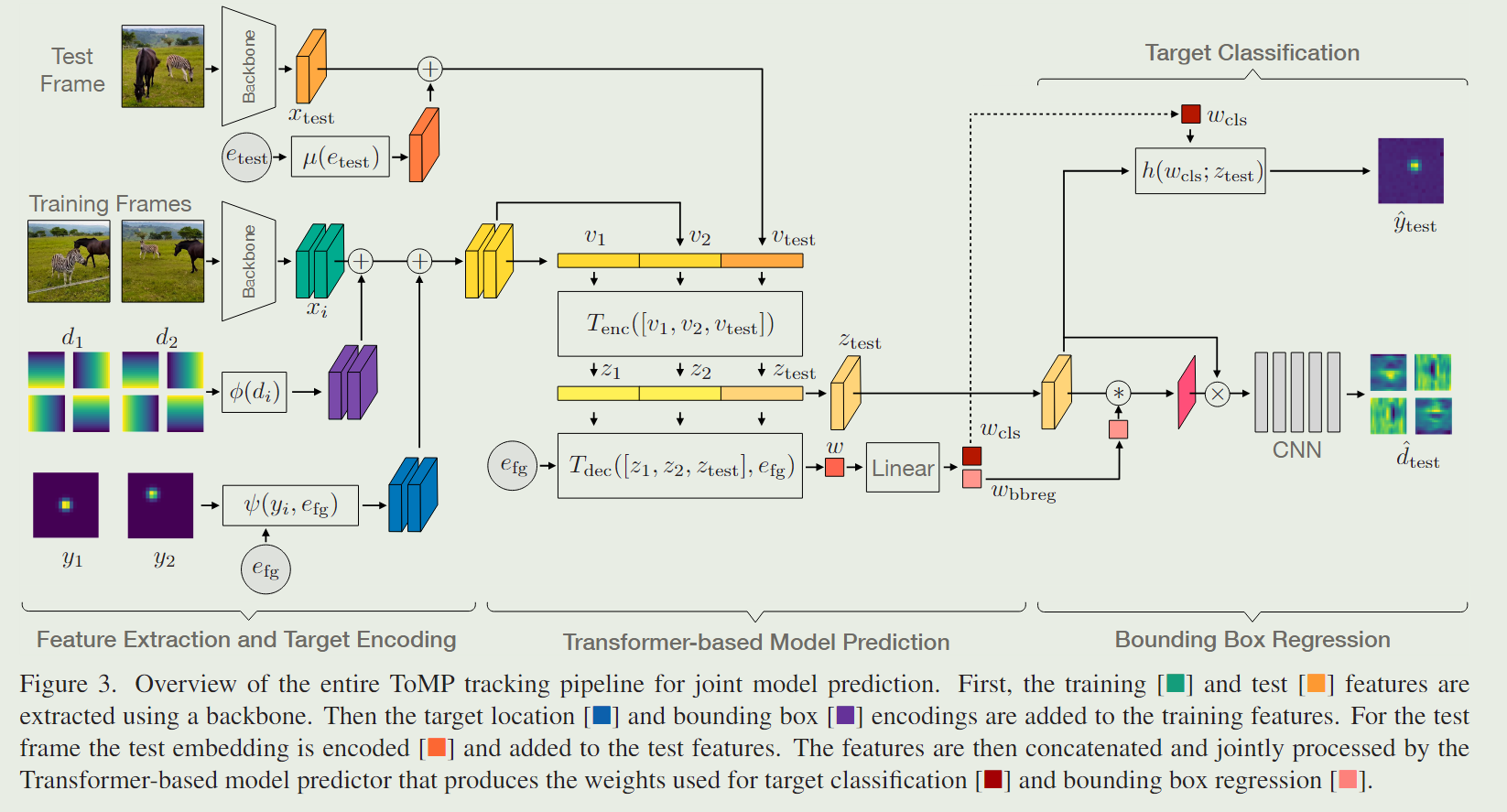
Target Extent Encoding:
除了提取的深度图像特征 x i x_i xi 和目标位置编码 ψ ( y i , e f g ) ψ(y_i, e_{fg}) ψ(yi,efg)之外,我们增加了另一个编码,以纳入关于目标的边界盒的信息。为了对包含训练帧 i i i 中的目标对象的边界框 b i = { b i x , b i y , b i w , b i h } b_i=\{b_i^{x},b_i^{y},b_i^{w},b_i^{h}\} bi={bix,biy,biw,bih}进行编码,我们采用 l t r b ltrb ltrb 表示。首先,我们使用 ( k x , k y ) = ( ⌊ s 2 ⌋ + s ⋅ j x , ⌊ s 2 ⌋ + s ⋅ j y ) (k^x,k^y)=(\lfloor\frac{s}{2}\rfloor+s\cdot j^x,\lfloor\frac{s}{2}\rfloor+s\cdot j^y) (kx,ky)=(⌊2s⌋+s⋅jx,⌊2s⌋+s⋅jy) 将特征图 x i x_i xi 上的每个位置 ( j x , j y ) (j^x, j^y ) (jx,jy) 映射回图像域。
然后,我们计算每个重新映射位置到边界框
b
i
b_i
bi 的四边的归一化距离,如下所示,
l
i
=
(
k
x
−
b
i
x
)
/
W
i
m
,
r
i
=
(
k
x
−
b
i
x
−
b
i
w
)
/
W
i
m
,
t
i
=
(
k
y
−
b
i
y
)
/
H
i
m
,
b
i
=
(
k
y
−
b
i
y
−
b
i
h
)
/
H
i
m
,
\begin{gathered} l_{i} =(k^x-b_i^x)/W_\mathrm{im},\quad r_i=(k^x-b_i^x-b_i^w)/W_\mathrm{im}, \\ t_{i} =(k^y-b_i^y)/H_\mathrm{im},\quad b_i=(k^y-b_i^y-b_i^h)/H_\mathrm{im}, \end{gathered}
li=(kx−bix)/Wim,ri=(kx−bix−biw)/Wim,ti=(ky−biy)/Him,bi=(ky−biy−bih)/Him,
其中
W
i
m
=
s
⋅
W
W_{im} = s·W
Wim=s⋅W 和
H
i
m
=
s
⋅
H
H_{im} = s·H
Him=s⋅H。这四边用于生成密集的边界框表示$ d = (l, t, r, b)
,其中
,其中
,其中d \in \mathbb{R}^{H \times W \times 4}$。
在这个表示中,我们使用多层感知器 (MLP)
ϕ
\phi
ϕ 对边界框进行编码,从而在将得到的编码添加到式(3)中使维度的数量从 4 增加到 C :
v
i
=
x
i
+
ψ
(
y
i
,
e
f
g
)
+
ϕ
(
d
i
)
.
v_i=x_i+\psi(y_i,e_{\mathrm{fg}})+\phi(d_i).
vi=xi+ψ(yi,efg)+ϕ(di).
这里,
v
i
v_i
vi 是生成的特征图,用作 Transformer 编码器的输入,见图 3。
Model Prediction:
我们扩展了我们的体系结构,以预测目标模型的权重,以及边界框回归。具体来说,我们将 Transformer Decoder 的输出 w w w 通过一个线性层来获得边界框回归 w b b r e g w_{bbreg} wbbreg 和目标分类 w c l s w_{cls} wcls的权重。然后,如前所述,在目标模型 h ( w c l s ; z t e s t ) h(w_{cls};z_{test}) h(wcls;ztest)内直接使用权重 w c l s w_{cls} wcls。另一方面,权重 w b b r e g w_{bbreg} wbbreg用于用边界盒回归的目标信息来约束Transformer Encoder的输出测试特征。
Bounding Box Regression:
为了使编码器输出特征 z t e s t z_{test} ztest目标感知,我们遵循Yan等人[63],首先使用预测的权重 w b b r e g w_{bbreg} wbbreg计算注意图 w b b r e g ∗ z t e s t w_{bbreg}∗z_{test} wbbreg∗ztest。然后将注意力权重与测试特征 z t e s t z_{test} ztest逐点相乘,然后将其输入卷积神经网络(CNN)。CNN的最后一层使用指数激活函数生成与Eq.(8)相同的 l t r b ltrb ltrb表示的归一化边界框预测。为了获得最终的包围盒估计,我们首先在目标模型预测的目标得分图 y ^ t e s t \hat{y}_{test} y^test上应用 a r g m a x ( ⋅ ) argmax(·) argmax(⋅)函数来提取中心位置。接下来,我们在目标对象的中心位置查询密集边界框预测 d ^ t e s t \hat{d}_{test} d^test,以获得边界框。
我们使用两个专用网络进行目标定位和边界盒回归,而Yan等人使用一个网络试图预测两者。正如第3.5节所解释的那样,这允许我们在跟踪期间将目标定位与边界框回归解耦。
1.4、Offline Training
我们使用训练帧的目标状态对目标信息进行编码,并且仅使用测试帧的边界框来监督训练,方法是基于预测的边界框和导出的测试帧中目标的中心位置计算两次损失。
我们采用了来自DiMP的目标分类损失,它由背景和前景区域的不同损失组成。此外,我们使用
l
t
r
b
ltrb
ltrb边界盒表示来监督边界盒回归,并使用广义交联损失(generalized Intersection over Union loss),
L
t
o
t
=
λ
c
l
s
L
c
l
s
(
y
^
,
y
)
+
λ
g
i
o
n
L
g
i
o
n
(
d
^
,
d
)
L_{\mathrm{tot}}=\lambda_{\mathrm{cls}}L_{\mathrm{cls}}(\hat{y},y)+\lambda_{\mathrm{gion}}L_{\mathrm{gion}}(\hat{d},d)
Ltot=λclsLcls(y^,y)+λgionLgion(d^,d)
其中
λ
c
l
s
λ_{cls}
λcls和
λ
g
i
o
u
λ_{giou}
λgiou是对每个损失的贡献进行加权的标量。
请注意,与FCOS和相关的跟踪器相比,我们忽略了额外的中心度损失,因为它与我们的分类损失有相同的目的,是多余的。
Training Details:
通过从一个视频序列的200帧窗口中随机抽取两个训练帧和一个测试帧来构建训练子序列。然后,在相对于目标边界框随机平移和缩放图像后提取图像补丁。此外,我们使用随机图像翻转和颜色抖动进行数据增强。我们将目标分数的空间分辨率设置为18×18,并将搜索区域比例因子设置为5.0。
1.5、Online Tracking
在跟踪期间,我们使用带注释的第一帧以及先前跟踪的帧作为我们的训练集 S t r a i n S_{train} Strain。虽然我们总是保留初始帧及其注释,但我们包括一个先前跟踪的帧,并将其替换为达到目标分类器置信度高于阈值的最新帧。因此,训练集 S t r a i n S_{train} Strain最多包含两帧。
我们观察到,将先前的跟踪结果纳入 S t r a i n S_{train} Strain可以显着提高目标定位。然而,由于不准确的预测,包括预测的边界框估计降低了边界框回归的性能。因此,我们运行模型预测器两次。首先,我们在 S t r a i n S_{train} Strain中加入中间预测以获得分类器权重。在第二次中,我们只使用带注释的初始帧来预测边界框。请注意,为了提高效率,这两个步骤可以在单个向前传递中并行执行。特别地,我们将两个训练帧和一个测试帧对应的特征映射重构为一个序列并复制它。然后,我们将它们叠加在批处理维度上,与模型预测器共同处理它们。为了在预测包围盒回归模型时只允许在带有真实注释的初始帧和测试帧之间进行注意力,我们使用了所谓的键填充掩码,该掩码允许在计算注意力时忽略特定的键。















 3325
3325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









