






💥1 概述
高斯混合模型(Gaussian Mixture Model,简称GMM)是一种统计模型,用于对数据集进行建模,假设数据是由多个高斯分布组合而成的。GMM 可以用于数据生成、聚类、密度估计等任务。要研究基于 GMM 的数据生成方法,你可以按照以下步骤进行:
1. **理解高斯混合模型(GMM)**:首先,深入了解高斯混合模型的原理。GMM 假设数据集中的每个数据点都是由多个高斯分布组合而成的。这些高斯分布的参数包括均值和协方差。
2. **模型参数估计**:学习如何从数据中估计 GMM 的参数。这通常使用 Expectation-Maximization (EM) 算法来完成。EM 算法的基本思想是通过迭代估计隐变量的后验概率,然后利用这些后验概率更新参数。
3. **数据生成**:理解如何利用已估计的 GMM 参数来生成数据。生成数据的过程通常包括以下步骤:
- 首先,从 GMM 中的每个高斯分布中随机选择一个成分。
- 然后,从所选高斯分布中生成一个数据点。
- 重复以上步骤直到生成足够数量的数据点。
4. **模型评估**:对生成的数据进行评估以确保其符合预期。可以通过比较生成数据的统计特征与原始数据集的特征来评估生成的数据的质量。
5. **参数调优**:根据评估结果调整 GMM 模型的参数,以获得更好的数据生成效果。这可能涉及改变高斯分布的数量、调整每个分布的参数等。
6. **应用和拓展**:考虑将 GMM 数据生成方法应用到实际问题中,并探索如何拓展这些方法以满足特定需求,例如在生成具有特定属性的数据时添加约束。
通过深入理解 GMM 的原理和参数估计方法,并结合实际数据集进行实验和评估,你可以更好地研究基于 GMM 的数据生成方法,并根据需要对其进行调整和优化。
基于高斯混合模型(Gaussian Mixture Model, GMM)的数据生成方法研究主要涉及到对GMM原理的理解、模型参数的估计、数据生成过程、模型评估以及参数调优等方面。以下是对这一研究方法的详细探讨:
一、高斯混合模型(GMM)原理
GMM是一种统计模型,用于对数据集进行建模,它假设数据是由多个高斯分布(也称为正态分布)组合而成的。每个高斯分布都有其独特的均值、协方差和混合系数,这些参数共同决定了GMM对数据集的拟合能力。GMM能够近似任意形状的概率分布,因此被广泛应用于数据生成、聚类、密度估计等领域。
二、模型参数估计
GMM的参数估计通常使用期望最大化(Expectation-Maximization, EM)算法。EM算法的基本思想是通过迭代来估计隐变量的后验概率,并利用这些后验概率来更新模型的参数。具体步骤如下:
初始化:随机选择每个高斯分布的均值、协方差和混合系数作为初始值。
期望步骤(E-step):给定当前的模型参数,计算每个数据点属于每个高斯分布的概率(即后验概率)。
最大化步骤(M-step):利用E-step得到的后验概率,重新计算每个高斯分布的均值、协方差和混合系数,以最大化观测数据的似然函数。
迭代:重复E-step和M-step,直到模型参数的变化小于某个阈值或达到预设的迭代次数,认为算法收敛。
三、数据生成过程
在GMM的参数被估计之后,可以利用这些参数来生成新的数据点。数据生成过程如下:
选择高斯分布:根据混合系数,从GMM中的多个高斯分布中随机选择一个分布。
生成数据点:从选定的高斯分布中随机生成一个数据点。这通常涉及到从该分布的均值和协方差中采样。
重复:重复以上步骤,直到生成足够数量的数据点。
四、模型评估
生成的数据需要通过评估来确保其符合预期。评估方法通常包括比较生成数据的统计特征与原始数据集的特征,如均值、方差、分布形态等。此外,还可以使用聚类算法(如K-means)对生成的数据进行聚类,并检查聚类结果与预期是否一致。
五、参数调优
根据模型评估的结果,可能需要对GMM的参数进行调优以获得更好的数据生成效果。参数调优可能涉及改变高斯分布的数量、调整每个分布的均值和协方差等。调优过程可以通过反复试验和评估来完成,直到找到最优的参数组合。
六、应用与拓展
GMM数据生成方法具有广泛的应用前景,可以应用于数据增强、模拟实验、风险评估等领域。此外,还可以探索如何将GMM与其他技术结合使用,以满足特定需求。例如,在生成具有特定属性的数据时,可以在GMM的基础上添加约束条件来限制生成数据的范围。
综上所述,基于GMM的数据生成方法研究是一个复杂但有趣的过程,它涉及到对GMM原理的深入理解、模型参数的精确估计、数据生成的细致操作以及模型评估和参数调优的反复迭代。通过这一研究过程,可以生成符合特定需求的高质量数据点,为数据分析、机器学习等领域提供有力支持。
📚2 运行结果
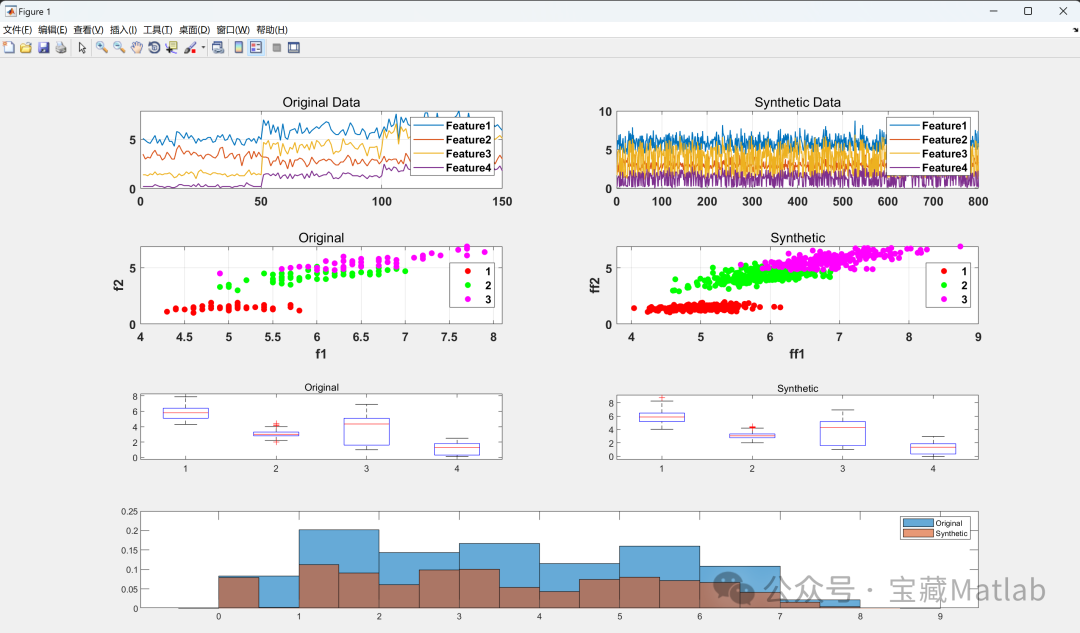
部分代码:
Input=Data;Target(1:50)=1;Target(51:100)=2;Target(101:150)=3;Target=Target'; % 标签,以1,2,3.。。表示DataSize=size(Data);DataSize=DataSize(1,1); % 样本个数Classes=3; % 类别数%% 生成数据的数量(按需求修改即可)NoofSynthetic=800;%% 高斯混合模型(GMM)拟合原始数据GMModel1 = fitgmdist(Input,Classes);%% 生成数据 (SDG)SDG = random(GMModel1,NoofSynthetic);%% 用K-means聚类方法获取合成生成数据的标签[Lbl,C,sumd,D] = kmeans(SDG,Classes,'MaxIter',10000,...'Display','final','Replicates',10);
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1]庞强,邹涛,丛秋梅,et al.基于高斯混合模型与主元分析的多模型切换方法[J].化工学报, 2013, 64(8):9.DOI:10.3969/j.issn.0438-1157.2013.08.034.
[2]曹振丽,孙瑞志,李勐.一种基于高斯混合模型的不确定数据流聚类方法[J].计算机研究与发展, 2014(S2):8.DOI:CNKI:SUN:JFYZ.0.2014-S2-013.
[3]何利平.基于混合高斯模型的智能视频多目标检测算法研究[D].广西师范大学,2014.DOI:10.7666/d.Y2584570.
🌈4 Matlab代码实现
详情请联系:


















 709
709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









