






hadoop伪分布式集群搭建(三、hadoop伪分布式搭建)
# 系列文章目录
hadoop伪分布式集群搭建(一、虚拟机安装)
hadoop伪分布式集群搭建(二、jdk,hadoop安装)
hadoop伪分布式集群搭建(三、hadoop伪分布式搭建)
==>前提
hadoop伪分布式集群搭建(一、虚拟机安装)中的操作已经完成。
hadoop伪分布式集群搭建(二、jdk,hadoop安装)中的操作已经完成。
一、修改主机名及网络ip映射(/etc/hostname、/etc/hosts)
-
使用
ifconfig查看当前虚拟机网络ip
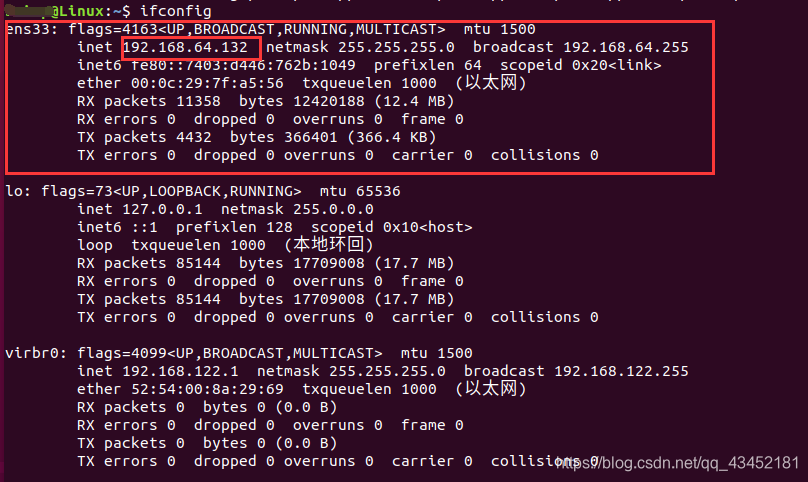
-
修改主机名为Linux
sudo vi /etc/hostname
将文件中的内容改为所用的主机名Linux即可, -
修改ip映射
sudo vi /etc/hosts -
将当前ip与主机名映射添加到其中
192.168.64.132 Linux
二、修改hadoop配置文件,搭建伪分布式集群
先进入到/home/hadoop/softwares/hadoop/etc/hadoop目录下 (为了防止hadoop下的文件访问没有权限,可以先执行 sudo chmod -R 777 ~/softwares/hadoop),下面就修改文件就可以不用使用sudo
- 修改hadoop-env.sh文件
sudo vi hadoop-env.sh
使用:set nu命令设置行号,找到37行,在38行追加内容:
export JAVA_HOME=/home/hadoop/softwares/jdk - 修改core-site.xml文件
sudo vi core-site.xml
在<configuratiom></configuration>标签中添加以下内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://Linux:9000</value>
<!-- Linux为主机名,对应主机名映射ip -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 需要在相应位置创建目录 -->
<value>/home/hadoop/softwares/hadoop/da/tmp</value>
</property>
- 修改hdfs-site.xml文件
sudo vi hdfs-site.xml
在<configuratiom></configuration>标签中添加以下内容:
<!--hdfs的备份因子,1就是只有一个备份。也就是只有一份-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- hdfs集群的名称 -->
<property>
<name>dfs.nameservices</name>
<!-- hdfs集群的名称可以随意取 -->
<value>hadoop-cluster</value>
</property>
<!-- 配置nameNode第二节点的位置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Linux:50090</value>
<!-- Linux为主机名 -->
</property>
<!-- hdfs集群web访问的地址,
这句不配置访问的路径就是localhost:9870-->
<!--<property>
<name>dfs.http.address</name>
<value>Linux:9870</value>
</property>-->
<!-- hdfs集群上 块的大小 -->
<property>
<name>dfs.blocksize</name>
<value>32m</value>
</property>
<!-- hdfs集群的namenode(主节点) 运行过程中的中间数据存放位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<!-- 需要在相应位置创建目录 -->
<value>/home/hadoop/softwares/hadoop/da/namenode</value>
</property>
<!-- hdfs集群的datanode(从节点) 数据存放位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<!-- 需要在相应位置创建目录 -->
<value>/home/hadoop/softwares/hadoop/da/datanode</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<!-- 需要在相应位置创建目录 -->
<value>/home/hadoop/softwares/hadoop/hdfs/snamenode</value>
</property>
<property>
<name>dfs.name.dir</name>
<!-- 需要在相应位置创建目录 -->
<value>/home/hadoop/softwares/hadoop/da/namenodeData</value>
</property>
<property>
<name>dfs.data.dir</name>
<!-- 需要在相应位置创建目录 -->
<value>/home/hadoop/softwares/hadoop/da/datanodeData</value>
</property>
- 修改mapred-site.xml文件
sudo vi mapred-site.xml
在<configuratiom></configuration>标签中添加以下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
<description>每个Map任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1536</value>
<description>每个Reduce任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx512M</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx1024M</value>
</property>
- 修改yarn-site.xml文件
sudo vi yarn-site.xml
在<configuratiom></configuration>标签中添加以下内容:
<!-- yarn集群的 resource manager 地址,主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- 这个Linux是计算机名 etc中hostname可以查看到 -->
<value>Linux</value>
</property>
<!-- 指定resourceManager的网页地址 -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<!-- Linux为主机名 -->
<value>Linux:8088</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs.hostname</name>
<value>/home/hadoop/softwares/hadoop/da/namenode</value>
</property>
<!-- MapReduce运行的模式是什么,混洗 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<!-- 需要在相应位置创建目录 -->
<value>/home/hadoop/softwares/hadoop/da/yarn/logs</value>
</property>
<property>
<name>yarn.application.classpath</name>
<!-- 下列内容在命令行输入hadoop classpath可以得到,复制粘贴到这即可 -->
<value>/home/hadoop/softwares/hadoop/etc/hadoop:/home/hadoop/softwares/hadoop/share/hadoop/common/lib/*:/home/hadoop/softwares/hadoop/share/hadoop/common/*:/home/hadoop/softwares/hadoop/share/hadoop/hdfs:/home/hadoop/softwares/hadoop/share/hadoop/hdfs/lib/*:/home/hadoop/softwares/hadoop/share/hadoop/hdfs/*:/home/hadoop/softwares/hadoop/share/hadoop/mapreduce/lib/*:/home/hadoop/softwares/hadoop/share/hadoop/mapreduce/*:/home/hadoop/softwares/hadoop/share/hadoop/yarn:/home/hadoop/softwares/hadoop/share/hadoop/yarn/lib/*:/home/hadoop/softwares/hadoop/share/hadoop/yarn/*</value>
</property>
<!—下列内容是以虚拟机2G内存为基础配置的,防止MapReduce运行时内存不足 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
三、启动集群(启动集群先一定要先检查IP是否改动!!!)
- 一般启动方式:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
yarn-daemon.sh start resourcemanager
yarn-daemons.sh start nodemanager
- 一般关闭方式:
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop datanode
yarn-daemon.sh stop resourcemanager
yarn-daemons.sh stop nodemanager
- 一键启动:
-
需要先配置ssh免密登录
建议先登录到root用户再执行下载安装命令
apt-get install openssh-server
apt-get install ssh -
使用
ssh 用户名@主机名进行ssh登录
ssh briup@Linux -
退出登录后,执行
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
再次使用登录验证免密登录 -
如果免密登录失败,执行:
rm -r ~/.ssh -
回到第三步重新执行
-
一键启动:
start-all.sh -
一键关闭:
stop-all.sh
四、使用jps及以下两个网页等检测集群启动情况(Linux为主机名,可以改为ip)
-
在虚拟机中浏览器可使用:
http://Linux:9870
http://Linux:8088 -
在自己本机上浏览器可使用:
http://192.168.64.132:9870
http://192.168.64.132:8088 -
如果集群启动正常,有如下五个进程:
jps、namenode、datanode、resourcemanager、nodemanager

-
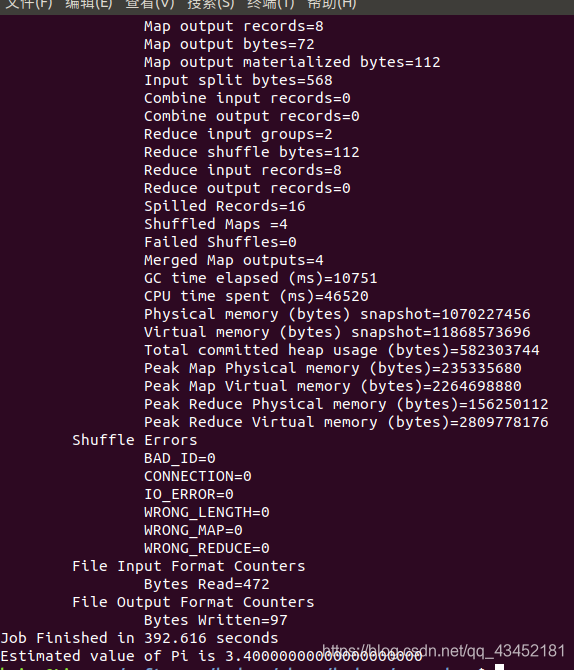
使用一个简单的例子进行测试,依次执行以下命令:
cd ~/softwares/hadoop/share/hadoop/mapreduce
yarn jar hadoop-mapreduce-examples-3.0.3.jar pi 4 10
得到如下结果,pi的值为3.400000000000000000
#系列文章目录
hadoop伪分布式集群搭建(一、虚拟机安装)
hadoop伪分布式集群搭建(二、jdk,hadoop安装)
hadoop伪分布式集群搭建(三、hadoop伪分布式搭建)















 2151
2151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









