






 本文提出了一种视听端到端神经网络模型,用于在嘈杂环境中提升语音质量。模型利用说话者的唇部动作来增强语音,减少背景噪音。通过在训练数据中添加目标说话者的声音作为背景噪声,模型能更好地利用视觉输入,适用于多种噪声类型。实验结果显示,该模型在唇读和视听数据集上的性能优于现有方法,并在巴拉克·奥巴马的演讲中展示了语音增强效果。
本文提出了一种视听端到端神经网络模型,用于在嘈杂环境中提升语音质量。模型利用说话者的唇部动作来增强语音,减少背景噪音。通过在训练数据中添加目标说话者的声音作为背景噪声,模型能更好地利用视觉输入,适用于多种噪声类型。实验结果显示,该模型在唇读和视听数据集上的性能优于现有方法,并在巴拉克·奥巴马的演讲中展示了语音增强效果。
论文研究3:Visual Speech Enhancement
使用说明:
本文为音视频混合分离语音信号(语音增强)的一篇论文
Abstract
在嘈杂的环境中拍摄视频时,可以通过可见的嘴巴动作来增强视频中说话者的声音,从而减少背景噪音。 尽管大多数现有方法都使用纯音频输入,但是基于视听神经网络的视觉语音增强功能可以提高性能。
我们在训练数据视频中添加了目标说话者的声音作为背景噪音。 由于音频输入不足以将讲话者的语音与他自己的声音分开,因此经过训练的模型可以更好地利用视觉输入并将其很好地归纳为不同的噪声类型。
所提出的模型在两个公共唇读数据集上优于先前的视听方法。 它也是第一个在非唇读设计的数据集上进行演示的数据,例如巴拉克·奥巴马(Barack Obama)的每周地址。
1. Introduction
语音增强旨在在嘈杂的环境中录制音频时提高语音质量和清晰度。 应用程序包括电话对话,视频会议,电视报道等。 语音增强功能还可用于助听器[1],语音识别和说话人识别[2,3]。 语音增强已经成为广泛研究的主题[4、5、6],并且最近得益于机器嘴唇阅读[7、8]和语音阅读[9、10、11]的进步。
我们提出了一种视听端到端神经网络模型,用于将可见说话者的语音与背景噪声分开。 一旦在特定的说话者上训练了模型,就可以用来增强该说话者的声音。 我们假定有一个视频显示目标讲话者的面部以及嘈杂的音轨,并使用可见的唇部动作将所需的语音与背景噪音隔离开。
虽然在某些情况下训练深度神经网络以区分不同来源的独特语音或听觉特征的想法可能非常有效,但性能受到来源差异的限制,如[12、13]所示。 我们表明,使用视觉信息可以在不同情况下显着提高增强性能。 为了涵盖仅使用音频信息无法将目标语音和背景语音完全分离的情况,我们在训练数据视频中添加了从目标说话者的语音中提取的合成背景噪声。 通过在训练数据中使用此类视频,训练后的模型可以更好地利用视觉输入并将其很好地推广到不同的噪声类型。
我们在不同的语音增强实验中评估模型的性能。 首先,在两个常见的视听数据集:GRID语料库[14]和TCD-TIMIT [15]上,我们展示了比现有技术更好的性能,它们均设计用于视听语音识别和唇读。 我们还在巴拉克·奥巴马(Barack Obama)的每周公开演讲中展示语音增强功能。
1.1. Related work
传统的语音增强方法包括频谱恢复[16,5],维纳滤波[17]和基于统计模型的方法[18]。 最近,深度神经网络已被用于语音增强[19,20,12],效果通常优于传统方法[21]。
1.1.1. Audio-only deep learning based speech enhancement
用于单通道语音增强的先前方法大部分仅使用音频输入。 Lu等[19]训练了用于对语音信号进行降噪的深层自动编码器。 他们的模型预测了代表清晰语音的梅尔音阶频谱图。 Pascual等[22]使用生成对抗网络,并在波形级别操作。 通过训练深度神经网络来区分不同来源的独特语音特征(例如语音),分离同时讲话的几个人的混音也成为可能。 频谱带,音高和chi,如[12、13]所示。 尽管它们的整体表现不错,但是当分离相似的人类声音时,纯音频方法却表现出较低的性能,这在同性别的混合物中很常见[12]。
1.1.2. Visually-derived speech and sound generation
存在用于从说话者的无声视频帧生成可理解语音的不同方法[11、10、9]。 在[10]中,Ephrat等人根据讲话者的一系列无声视频帧生成语音。 他们的模型使用视频帧和相应的光流来输出表示语音的频谱图。 Owens等 [23]使用递归神经网络从人们用鼓槌敲击和刮擦物体的无声视频中预测声音。
1.1.3. Audio-visual multi-modal learning
视听语音处理的最新研究广泛使用了神经网络。 Ngiam等人的工作[24]是这方面的开创性工作。 它们演示了跨模态特征学习,并表明如果在特征学习时同时存在音频和视频,则可以学习一种模态(例如,视频)的更好特征。 具有视听输入的多模态神经网络也已用于唇读[7],唇同步[25]和鲁棒的语音识别[26]。
1.1.4. Audio-visual speech enhancement
视听语音增强和分离方面的工作也已经完成[27]。 Kahn和Milner [28,29]使用手工制作的视觉特征来导出用于说话者分离的二进制和软掩码。 侯等人[30]提出了卷积神经网络模型来增强嘈杂的语音。 他们的网络获得一系列裁剪到说话者嘴唇区域的帧,以及代表嘈杂语音的频谱图,并输出代表增强语音的频谱图。 Gabbay等 [31]将视频帧馈送到经过训练的语音生成网络[10]中,并使用预测语音的频谱图来构建用于将纯净语音与嘈杂输入分离的掩码。
2. Neural Network Architecture
语音增强神经网络模型获得两个输入:(i)一系列视频帧,显示说话者的嘴部信息; (ii)嘈杂音频的声谱图。 输出是增强语音的频谱图。 网络层以编码器-解码器的方式堆叠(图1)。 编码器模块由一个双塔式卷积神经网络组成,该网络接收视频和音频输入,并将它们编码为表示视听特征的共享嵌入。 解码器模块由转置的卷积层组成,并将共享的嵌入解码为表示增强语音的频谱图。 整个模型是端到端训练的。
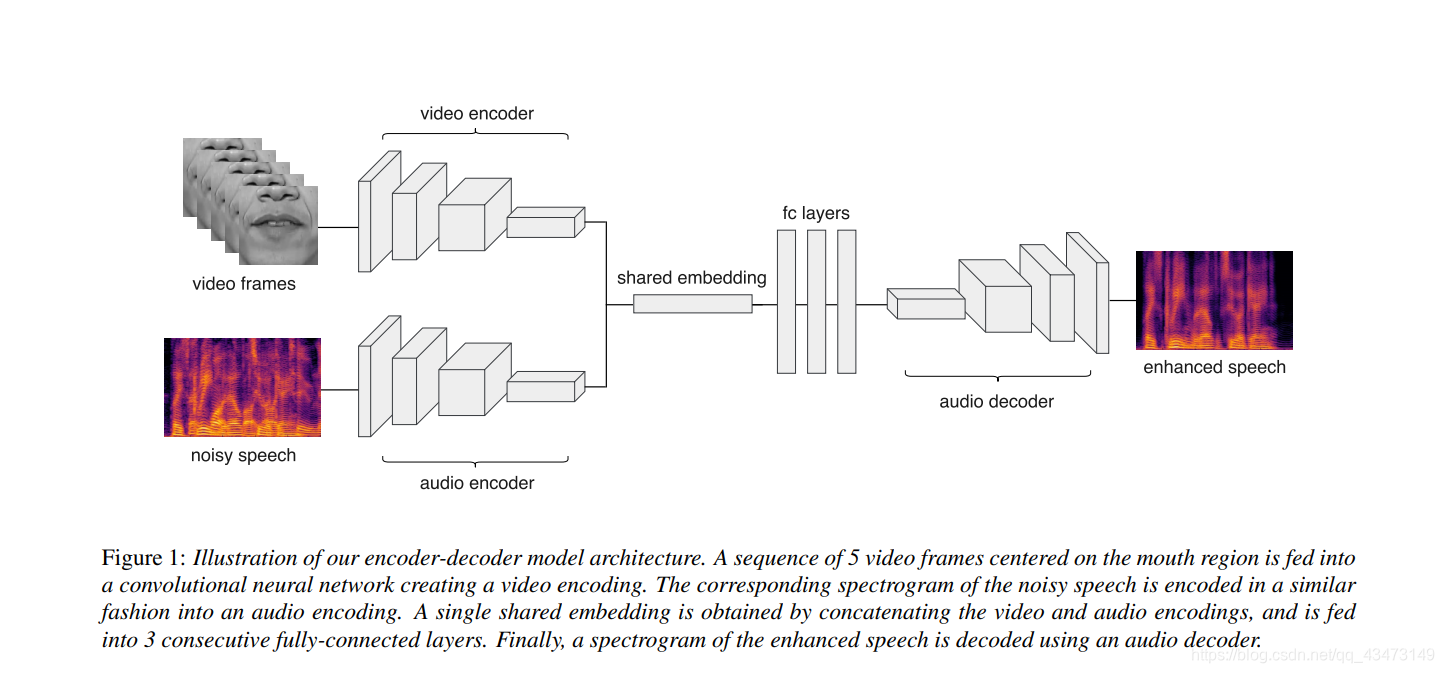
2.1. Video encoder
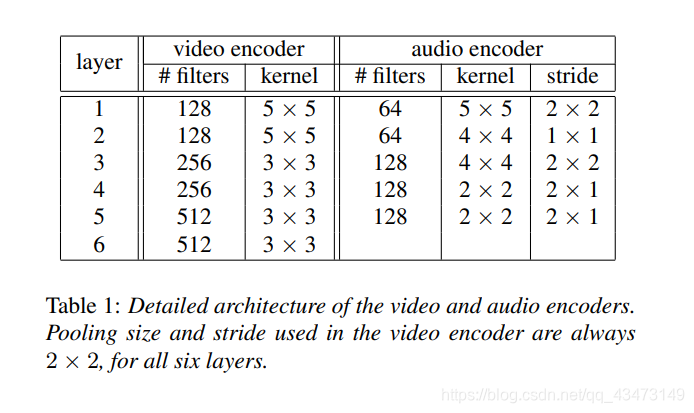
视频编码器的输入是5个大小为128×128的连续灰度视频帧的序列,裁剪并居中于嘴部区域。 虽然使用5帧效果很好,但也可以使用其他数量的帧。 视频编码器具有6个连续的卷积层,如表1所示。每层之后是批处理归一化,用于非线性的Leaky-ReLU,最大合并和0.25的Dropout。
2.2. Audio encoder
输入和输出音频都由对数梅尔标度声谱图表示,该谱图具有80个介于0到8kHz之间的频率间隔和20个跨越200 ms的时间步长。
正如之前在多个音频编码网络中所做的一样[32,33],我们将音频编码器设计为使用频谱图作为输入的卷积神经网络。 该网络由5个卷积层组成,如表1所示。每个层后面都具有批处理归一化和Leaky-ReLU,以实现非线性。 为了保持时间顺序,我们使用跨步卷积而不是最大池化。
2.3. Shared representation
视频编码器输出具有2,048个值的特征向量,而音频编码器输出3,200个值的特征向量。 特征向量被连接到一个共享的嵌入中,该嵌入代表具有5248个值的视听特征。 然后,将共享的嵌入馈入3个连续的完全连接的层的块中,分别具有1312、1312和3200的大小。 然后将所得的向量馈入音频解码器。
2.4. Audio decoder
音频解码器由5个转置的卷积层组成,镜像了音频编码器的各层。 最后一层与输入频谱图的大小相同,代表增强的语音。
2.5. Optimization
训练网络以最小化输出频谱图和目标语音频谱图之间的均方误差(l2)损失。 我们使用初始学习率为5e-4的Adam优化器进行反向传播。 一旦学习停滞,即学习错误在5个时期内没有改善,学习率将降低50%。
3. Multi-Modal Training
具有多模式输入的神经网络通常可以由输入之一控制[34]。在先前的工作中已经考虑了不同的方法来克服此问题。 Ngiam等[24]提出在训练过程中偶尔将一种输入模式(例如,视频)清零,而仅将另一种输入模式(例如,音频)清零。这个想法已经在唇读[7]和语音增强[30]中采用。为了强制使用视频功能,侯等人[30]添加了一个与输入类似的辅助视频输出。
我们通过引入新的训练策略来强制开发视觉功能。我们在训练数据样本中包括其中增加的噪声是同一说话者的声音的样本。由于仅使用音频信息就不可能将同一人说的两个重叠句子分开,因此网络被迫利用音频功能之外的视觉功能。我们表明,使用这种方法训练的模型可以很好地概括不同的噪声类型,并且能够将目标语音与无法区分的背景语音区分开。
4. Implementation Details
4.1. Video pre-processing
在我们所有的实验中,视频均重新采样为25 fps。 视频被分为每个5帧(200毫秒)的非重叠段。 在每帧中,我们使用[35]提出的68个面部标志中的20个嘴部标志来裁剪大小为128×128像素的以嘴为中心的窗口。 因此,用作输入的视频片段的大小为128×128×5。 我们通过减去平均视频帧并除以标准差,在整个训练数据上对视频输入进行归一化。
4.2. Audio pre-processing
相应的音频信号被重新采样到16 kHz。 短时傅立叶变换(STFT)应用于波形信号。 频谱图(STFT幅度)用作神经网络的输入,并且保留相位以重建增强信号。 我们将STFT窗口大小设置为640个样本,这等于40毫秒,并且对应于单个视频帧的长度。 我们将窗口一次跳跃160个样本的跳跃长度,从而产生75%的重叠。 对数梅尔尺度谱图是通过将谱图乘以梅尔间隔的滤波器组来计算的。 对数梅尔音阶频谱图包含0到8000 Hz的80个梅尔频率。我们将频谱图切成与5个视频帧的长度相对应的200毫秒长的片段,从而生成尺寸为80×20的频谱图:20个时间样本,每个样本具有80个频点。
4.3. Audio post-processing
语音段被一一推断并连接在一起以创建完整的增强频谱图。 然后通过将梅尔标度谱图乘以梅尔间隔滤波器组的伪逆来重构波形,然后应用逆STFT。 我们将原始相位用作有噪声的输入信号。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









