







1. 简介
如果所有的键都是小整数,我们可以用一个数组来实现无序的符号表,将键作为数组的索引而
数组中键 i 处储存的就是它对应的值。这样我们就可以快速访问任意键的值
使用散列的查找算法分为两步:
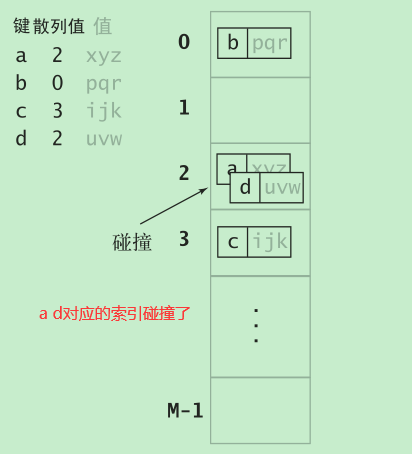
- 用散列函数将被查找的键转化为数组的一个索引(理想情况下每个键对应的索引都不一样,实际上会有不同的键转化成相同的索引)
- 多个键都会散列到相同的索引值,需要处理碰撞冲突的情况(拉链法和线性探测法)
2. 散列函数
散列函数:将键转化为数组的索引
要求:
- 散列函数应该易于计算
- 能够均匀分布所有的键,减少冲突
- 每种数据类型都需要相应的散列函数,于是 Java 令所有数据类型都继承了一个能够返回一个32 比特整数的 hashCode() 方法
- 如果 a.equals(b) 返回 true,那么 a.hashCode() 的返回值必然和 b.hashCode()的返回值相同
- 两个对象的 hashCode() 方法的返回值相同,这两个对象也有可能不同,还需要用 equals() 方法进行判断
- 如果两个对象的 hashCode() 方法的返回值不同,那么我们就知道这两个对象是不同的
Integer a=1;
Integer b=1;
System.out.println(a.hashCode());//1
System.out.println(b.hashCode());//1
String s1="hello";
String s2="hello";
System.out.println(s1.hashCode());//99162322
System.out.println(s2.hashCode());//99162322
要为自定义的数据类型定义散列函数,需要同时重写 hashCode() 和 equals() 两个方法,默认散列函数会返回对象的内存地址
hashcode方法返回一个32bit的数值,但是数组的索引往往没有那么大,因此不能直接使用hashcode值,需要进行转换,将默认的 hashCode()方法和除留余数法结合起来产生一个 0 到 M-1 的整数
private int hash(Key x) {
return (x.hashCode()&0x7fffffff)%M;
}
上面这段代码的作用:
- 将一个 32 位整数变为一个 31 位非负整数
- 用除留余数法计算它除以 M 的余数
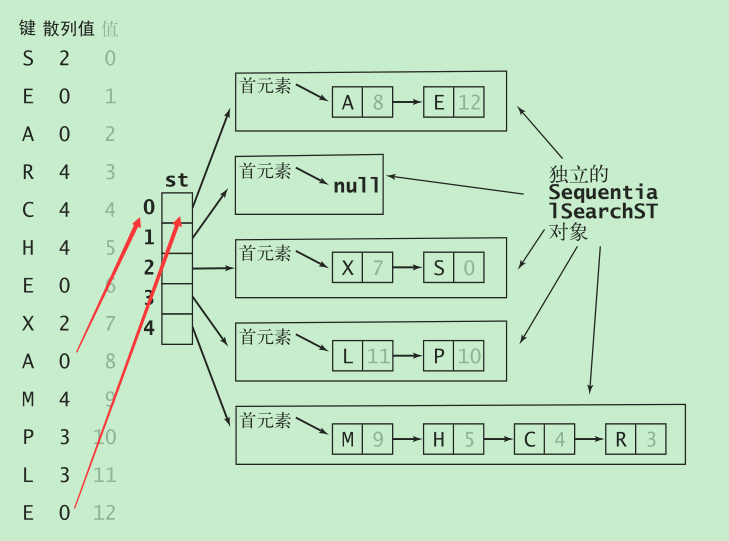
3. 基于拉链法的散列表
将大小为 M 的数组中的每个元素指向一条链表,链表中的每个结点都存储了散列值为该元素的索引的键值对。这种方法被称为拉链法
4. 基于线性探测法的散列表
用大小为 M 的数组保存 N 个键值对,其中 M>N。依靠数组中的空位解决碰撞冲突。基于这种策略的所有方法被统称为开放地址散列表,开放地址散列表中最简单的方法叫做线性探测法
当碰撞发生时(当一个键的散列值已经被另一个不同的键占用),直接检查散列表中的下一个位(将索引值加 1,到达数组结尾时折回数组的开头),直到找到该键或者遇到一个空元素

















 541
541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











