









在很多应用中,都要用到一种动态集合结构,仅支持 INSERT, DELETE, SEARCH字典操作。例如,编译器需要维护一个符号表,其中元素的关键值为任意字符串。实现这样一种集合的有效数据结构为哈希表(hash table),也称散列表。接下来我们就从简单到复杂来详细地讲解哈希表。
直接寻址表
假设有一个元素的集合,每个元素都有一个取自全域U⊆{0, 1, …, m–1}的关键字,且集合中每个元素的关键字都互不相同。我们用一个数组 T[0 . .m–1] 表示这样一个元素的动态集合,数组的每个槽,或者说每个下标对应全域U中的一个关键字,即关键字 k 对应 T 中第 k 个槽。如果集合中有关键字为 k 的元素 x,则 T[k]=x,否则 T[k]=NIL。直接寻址表很简单,执行上述的字典操作只需 O(1) 的时间。
虽然直接寻址表很简单,也很高效,但实际中很少能够直接应用,因为直接寻址表存在着一些很明显的问题:
1、当U很大的时候,我们可能无法在计算机内存中存储大小为|U|的数组(表)T。
2、就算我们可以存储这么大的一张表,实际需要存储的关键字集合可能只是U的一个很小的子集,所以分配给T的大部分空间都浪费掉了。
3、如果关键字是字符串呢,那么这个关键字域可能就更大了,而且如果使用数组来表示直接寻址表,也没办法直接用字符串做下标。
这些问题的解决方法就是我们接下来要说的散列表了。
散列表
在直接寻址方式下,具有关键字k的元素被存放在槽k中。在散列方式下,我们用一个散列函数或哈希函数(hash function)h将全域U中的所有关键字映射到{0, 1,…, m–1}(散列函数h必须是确定的,即对某一给定的输入k应始终产生相同的结果h(k)),那么关键字为k的元素就存放在槽h(k)中。这里,我们说一个具有关键字k的元素被散列到槽h(k)上,如下图所示:
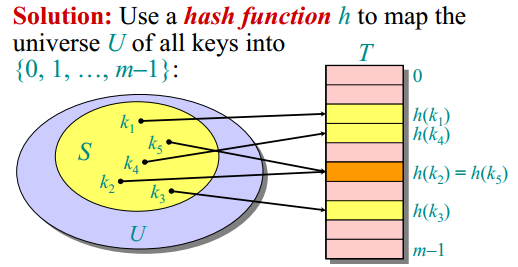
如上图所示,我们也遇到了一个问题:两个关键字可能映射到同一个位置,我们把这种情况称为碰撞(collision)。当|U|>m时,完全避免碰撞是不可能的,接下来就详细介绍一些解决碰撞问题的技术。
通过链接法解决碰撞
链接法的思想就是把散列到同一个槽中的所有元素用一个链表链接起来,如下图所示:
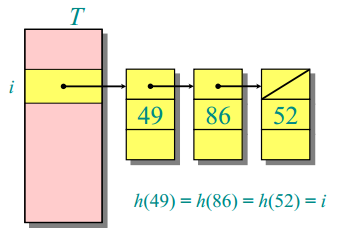
槽 i 中存储的是一个指针,指向一个链表,该链表中存放着所有散列到槽i的元素,即h(49) =h(86) = h(52) = i。插入操作的最坏运行时间为 O(1),因为无论所散列到的槽里面有没有元素,只需要把元素插入到对应的链表表头就行了。在最坏情况下,每一个关键字都散列到同一个槽,这时散列表就退化为一个链表,查找和删除所需要的时间是 Θ(n),n为集合的元素个数。因此用链接法散列的最坏情况性能很差,但平均情况下链接法有着不错的性能。
链接法的平均情况性能分析
首先我们做一个的假设,称为简单一致散列(simple uniform hashing)
简单一致散列:每一个关键字是等可能地被散列到表T中的任意一个槽的,且与其他关键字被已被散列到什么位置无关。
我们用n表示表T中元素的个数,m表示槽的数目,定义表T的装载因子(load factor) α= n/m,即每个槽中平均存储的元素个数。在简单一致散列的假设下,一次不成功查找的期望时间为 Θ(1 + α)。因为元素是等可能地被散列到任意一个槽中,需要查找的链表的平均长度为 α,加上计算 h(k) 和访问相应的槽的时间,所需的总时间为 Θ(1 + α)。
而对于成功查找,在简单一致散列的假设下,平均情况下所需的时间跟一次不成功查找所需的时间相同,也是 Θ(1 + α),可证明如下:
设 xi 表示插入到表中的第 i 个元素,则需要检查的元素的期望数目为在 xi 之后插入的元素中 (即xi+1,…,xn) 与 xi 散列到同一个槽中的元素的期望数目加1(比较 xi 本身),再对表中的 n 个元素取平均。我们定义指示器随即标量 Xij = I{h(ki)=h(kj)},ki 和 kj 分别表示元素 xi 和 xj 的关键字,在简单一致假设下,有 Pr{ h(ki) = h(kj) } = 1/m,故 E[Xij]=1/m。于是,在一次成功查找中,所检查元素的期望数目为:

因此一次成功查找平均所需的时间为 Θ(1+1+α/2-α/2n)=Θ(1 + α)。
如果α=O(1),或者说n=O(m),那么查找的期望时间就是Θ(1),也就是是平均情况下,所有的操作都可以在常数时间内完成。
选择散列函数
一般来说我们很难保证一个散列函数具有简单一致散列的性质的,但有几个通用的技术在实际中表现的很好,只要能够避免它们的缺点。
一个好的散列函数应该将所有的关键字一致(均匀)地散列到哈希表的各个槽中,并且关键字中的规律性不会影响这种一致性。
除法散列法
假设所有的关键字都是整数,我们定义散列函数h(k)= k mod m。
缺点:不要选择一个具有比较小的除数 d 的 m 值,因为如果关键字集中有很多关键字能够被 d 整除,那么散列函数的一致性就会被破坏。
例如,取 m 为偶数,即 m 有除数 d=2,如果关键字也都是偶数,那么这些关键字就只会被散列到偶数槽位,奇数槽位则永远都是空的。
另外一个极端的例子就是取 m=2r,那么散列值就不是平等地依赖于关键字k的所有二进制位。比如,k=10110001110110102,r=6,那么h(k)=0110102,即散列值就等于 k 的最低六位数,跟k的其他二进制位的数值无关。
因此,我们应该选择 m 为一个不太靠近2或者10的素数,也不要选择那些经常在计算环境中经常使用的数。
尽管有些时候让散列表的大小为素数是不太方便的,而且比起加法乘法计算机做除法运算的开销比较大,但这个方法很常用,因为它很简单,也能很方便很容易地嵌入到代码中去。下一节我们会讲一种更好的方法。
乘法散列法
假设所有的关键字都是整数,m=2r,计算机字长为w位。我们定义散列函数 h(k)=(A*k mod 2w) rsh (w-r)。其中 rsh 向右位移,A(2w-1<A<2w) 是一个奇数。一般来说,A不要选择太靠近 2w-1 和 2w 的数。相对于除法,乘法、取模运算和移位都比较快。
例子:假设m=8=23,计算机字长为w=7-bit,则对于A=1011001,k=1101011,h(k)的计算过程如下图所示:

用开放寻址法解决碰撞问题
在开放寻址法中,我们只用到了散列表本身,而不需要外部存储(不如链接法中的链表),插入操作有组织地探查散列表直到找到一个空槽,然后将元素插入到这个空槽里面。开放寻址法中的散列函数依赖于关键字和探查号,即
h: U×{0, 1, …, m–1} →{0, 1, …, m–1}
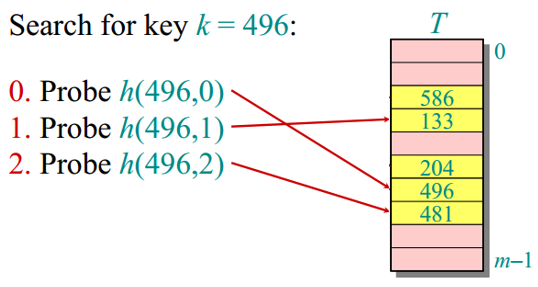
探查序列 〈h(k,0), h(k,1), …, h(k,m–1)〉必须是{0, 1, …, m–1}的一个排列,保证散列函数能够按照某种顺序探查到整个散列表个槽位。整个散列表可能被填满,而且从表中删除元素比较困难。下面的例子查找关键字k=496的元素,使用同样的探查方法进行查找,如果找到关键字k则查找成功;如果遇到一个空槽,则查找失败:
探查策略
线性探查:
给定一个普通的散列函数 h'(k),线性探查使用散列函数 h(k,i)=(h'(k)+i) mod m。
这个方法虽然简单,但是会产生一次群集(primary clustering)的现象,导致连续的槽位被占用,进而增加平均查找时间,而且连续被占用槽的序列会变得越来越长,因而平均查找时间也会随之增加。
二次探查
给定一个普通的散列函数h'(k),二次探查使用散列函数 h(k,i)=(h'(k)+c1*i+c2*i2) mod m。
双重散列:
给定两个普通散列函数 h1(k) 和 h2(k),双重散列使用散列函数 h(k,i)=(h1(k)+i*h2(k)) mod m。
开放寻址法性能分析
首先我们先做一个假设,叫做一致散列(uniform hashing)
一致散列:每一个关键字都等可能的选取 m!种排列中的一种作为它的探测序列。
于是我们有下列的定理:
给定一个装载因子为α=n/m<1的开放寻址的散列表,则一次不成功查找的期望探测数最多为1/(1-α)。
证明:
我们知道查找的时候至少需要一次探测,而第一次探测到一个被占用的槽的概率为n/m,那么我们就需要第二次探测;第二次探测到一个被占用的槽的概率为(n-1)/(m-1),则我们需要第三次探测;第三次探测到一个被占用的槽的概率为(n-2)/(m-2);···以此类推。注意到,我们有期望的探测次数为
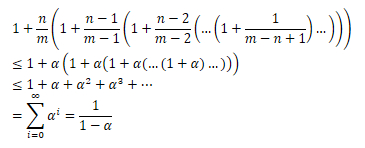
证毕。
这个定理告诉我们,如果 α 是个常数,则访问一个开放寻址散列表只需要常数时间;
如果散列表填充了一半,则期望探测次数为1/(1-0.5)=2;
如果散列表填充了90%,则期望探测次数为1/(1-0.9)=10;
因此我们应该尽量不要让散列表填充得太满,让表的大小尽量大些,比如是所需要存储的关键字数的两倍或更多,这样才能减少访问散列表时的平均探测次数。
根据以上定理,我们可以直接得出插入操作的性能:只有当表中有空槽时,才可以插入新的元素,故 α<1。插入一个关键字要先做一次不成功的查找,然后将该元素放在第一个遇到的空槽中。所以,期望的探测次数为1/(1-α)。
总结
总而言之,散列表在平均情况下有很好的性能:
对于采用链接法的散列表,当 n=O(m) 时,平均情况下所有的操作都可以常数时间内完成;
对于采用开放寻址的散列表,查找、插入的期望时间 O(1/(1-α)),当散列表比较稀疏时,也就是装载因子比较小的时候,这些操作在平均情况下也都可以在常数时间里完成。
















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











