







论文标题
A deep variational approach to clustering survival data
论文作者、链接
作者:
Manduchi, Laura and Marcinkevi{\v{c}}s, Ri{\v{c}}ards and Massi, Michela C and Weikert, Thomas and Sauter, Alexander and Gotta, Verena and M{\"u}ller, Timothy and Vasella, Flavio and Neidert, Marian C and Pfister, Marc and others
链接:https://arxiv.org/abs/2106.05763
Introduction逻辑(论文动机&现有工作存在的问题)
生存分析(Survival analysis),在很多医疗场景下有广泛的应用,用来推断解释变量(explanatory variables )和潜在的检查结果(censored survival outcome)之间的关系——后者表示某一事件发生的时间,如死亡或癌症复发,并在只知道部分相关情况时可以审查出来——用机器学习来学习这些数据的非线性关系
聚类——不适用于生存结果(the survival outcomes)——无法保证聚类结果中的子簇是与患者的信息相关——本文专注于聚类survival data的半监督学习方法,该方法联合考虑解释变量和审查结果作为患者状态的指标
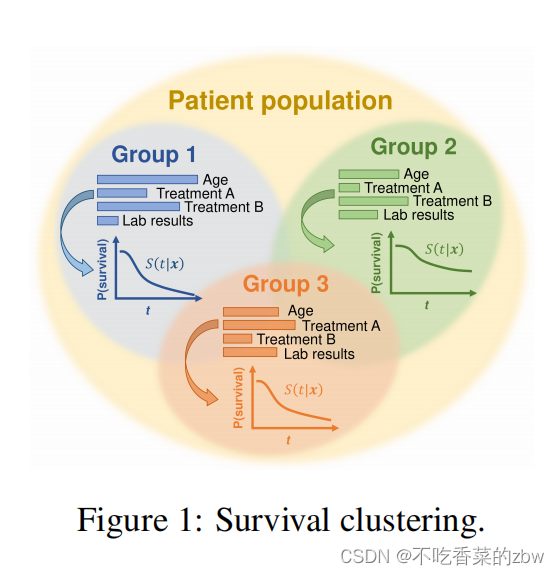
图1描述了这个聚类问题:整个患者群体由三个group组成,其特征是协变量和survival之间的不同关联,导致不同的临床情况
对于survival data的聚类——现有方法的局限:在高纬度的容量有限,无结构的数据以及专注于发现纯结果驱动的聚类——当仅凭survival distribution不足以对人群进行分层时,后者可能无法应用——相似survival outcome的患者可能需求不同的治疗手段
论文核心创新点
提出一个survival聚类方法,联合建模解释变量和censored survival outcomes
相关工作
针对survival data的聚类
论文方法

预备知识
对于每一个患者有个三元组的数据集
。
代表特征的可解释变量。
是检查指示变量,如果第
个患者的survival time被审查了,值为0,否则值为1。
是潜在的检查survival time。在survival analysis上用一个最大似然方法,来建模一个survival distribution,即
。
对于survival analysis的两个主要的挑战,(i)survival times 的检查(ii)之间的复杂非线性关系。当对survival data进行聚类的时候,我们额外的考虑了一个在训练过程中观测到的潜在聚类分配变量
,
是簇的总数目。于是目标问题变成了:(i)推测未观测到的聚类分布(ii)在给定
的情况下对survival distribution进行建模
生成模型

假设数据是由下列步骤随机生成的。
1,从分类分布中采样簇分布
2,从高斯分布生成一个连续的潜在嵌入,这个嵌入的均值和方差依赖于采样的簇:
3,解释变量是从在
上的条件分布生成的,
,其中对于二值特征有
,对于实值特征有
。
至此,由
生成,为一个解码器神经网络,参数为
。
4,survival time 依赖于聚类分布
,潜在变量
和检查指示变量
,即
Survival Model
参考于具体的簇的survival model。假设给定
,依据韦伯分布的未审查的survival time由
给定,其中
,
是形状参数,
是具体的簇的survival参数。 为了简洁省略偏置项
。观察
项,对应的是韦伯分布的尺度参数。带有尺度参数
以及形状
的韦伯分布,有一个概率稠密函数,在
的情况下,有
。于是,从下列分布对right-censoring区域做出调整:

其中,并且
是surviva函数。至此,使用
作为
的缩写。本文中只考虑right-censoring的情况
联合概率分布
的联合概率分布写成
。值得注意的是
是与给定的
所独立的。我们重写联合概率分布,参考似然函数,有:

置信下界
根据之前数据生成的假设,目标是推理参数。由于方程2中的似然函数是难以处理的,我们将数据的对数边际概率的下界最大化:

我们给出了具有变化分布的观测值z和c的近似概率。其中第一项是由神经网络参数化的编码器。第二项等于真实概率
:
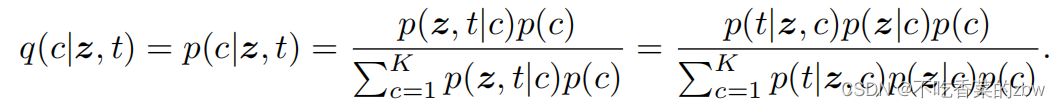
因此,证据下界(ELBO)可表示为:
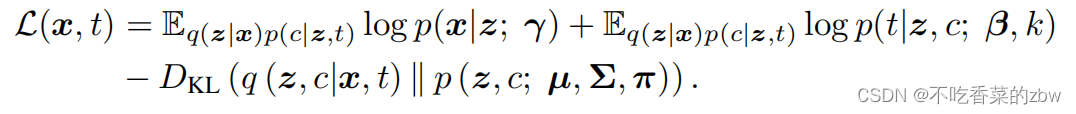
缺失的Survival Time
硬聚类分配可由式4的分布计算。然而,在测试时可能无法观察到存活时间;
而我们对分布的推导依赖于
。因此,当个体的生存时间未知时,我们使用贝叶斯规则计算,即:
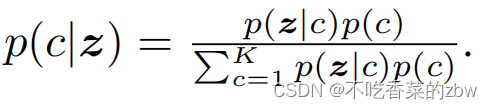
一句话总结
说实话没看懂
论文好句摘抄(个人向)
(1)Clustering, on the other hand, serves as a valuable tool in data-driven discovery and subtyping of diseases















 2159
2159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









