







论文标题
Attention-driven Graph Clustering Network
论文作者、链接
作者:Peng, Zhihao and Liu, Hui and Jia, Yuheng and Hou, Junhui
代码:https://github.com/ZhihaoPENG-CityU/MM21---AGCN
Introduction逻辑(论文动机&现有工作存在的问题)
聚类——深度聚类,关键在于从潜在数据总学习错综复杂的模式——在深度聚类中添加结构化信息,深度图聚类——现存问题:往往将图特征和结点特征重要性等同,并且只考虑了最深层提取的特征忽略了多尺度的特征
论文核心创新点
逐层融合模块:将GCN和AE的同一层特征进行融合
逐尺度融合模块:把不同层的多尺度模块融合
相关工作
深度聚类
深度图聚类
论文方法

本文提出的 attention-driven graph clustering network (AGCN)主要分成两个部分:(1)逐层融合模块heterogeneity-wise fusion module (AGCN-H)(2)逐尺度融合模块scale-wise fusion module (AGCN-S)
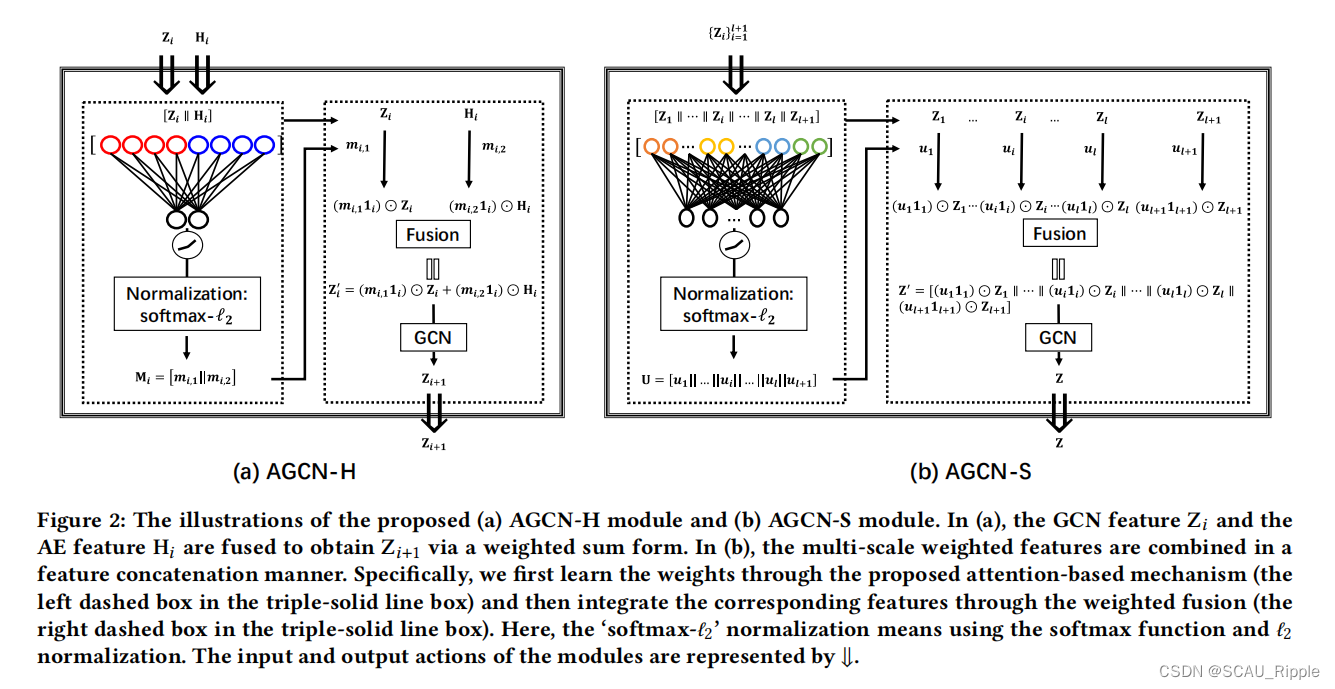
逐层融合模块AGCN-H
GCN可以有效的捕捉图的拓扑信息,AE可以提取结点的特征信息,AGCN-H模块可以将GCN学到的特征和AE学到的特征进行融合,以学到更具有区别度的特征。具体来说,利用基于注意的机制和异构策略,进行注意系数学习和随后的加权特征融合。如图2(a)所示。
首先,编码器——解码器模块通过最小化重构误差来提取潜在特征,即:
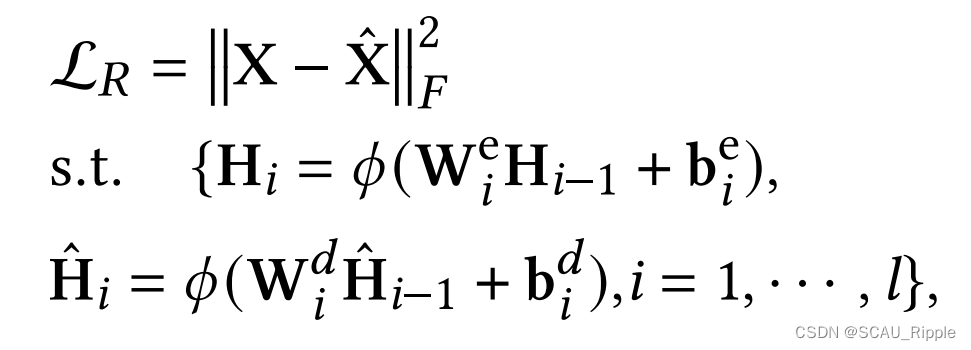
其中,表示原始数据,
表示重构数据。
分别代表编码器和解码器的第
层的输出。
表示激活函数,比如Tanh,ReLU。
分别代表编码器第
层的权重和偏置,
分别代表解码器的第
层的权重和偏置。
代表原始数据
,
代表重构的数据
。此外,GCN第
层学到的特征记作
,
代表原始数据
。
为了学习相应的注意系数,将拼接起来,即
。然后一个全连接层,参数矩阵为
,用来捕捉拼接起来的特征。然后,用LeakyReLU激活函数,应用于
和
之间的多层感知机上。LeakyReLU的输出经过一个归一化后,再经过一个softmax函数和一个
归一化,公式化如下:
![]()
其中是注意力的系数矩阵,矩阵内所有的值都大于0。
分别是衡量
的重要性的权重向量。对第
层的GCN的特征
和AE的特征
进行自适应融合,即:

其中代表全是1的向量,
代表哈达玛积。将得到的向量
做为第
层的GCN输入去学习
的特征表达,公式如下:
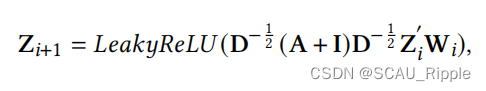
其中,正交领接矩阵通过
进行归一化,有
是单位矩阵,
是相关度矩阵,
代表网络的权重。
总的来说,通过AGCN-H模块实现GCN和AE特征的动态特征融合。
逐尺度融合模块AGCN-S
现有的深度聚类算法往往忽略不同层级的多尺度信息,于是本文设计了逐尺度融合模块AGCN-S。因为不同层级的特征维度是不同的,所以先通过concat函数对多尺度的特征做一个聚合:
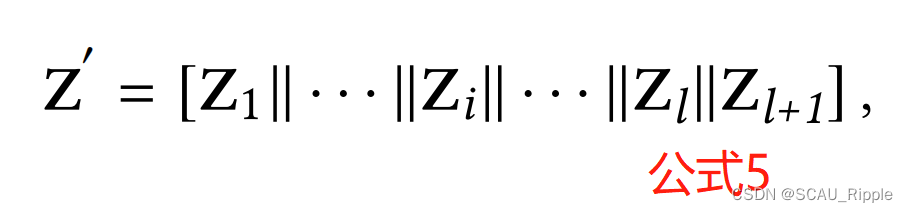
其中,有
是第
层的维度,
代表编码器的的层数。特别地,
。
不同层级对输入数据的描述信息是不同的,并且在最后的聚类任务中扮演着不同的角色,直接将不同的层级的权重相等是不行的。由此,通过注意力机制,将AGCN-S模块与多尺度动态结合。如图2(b)所示。
首先,用一个全连接层,参数矩阵为,用来捕捉不同层的特征中的关系,然后在
和
之间使用LeakyReLU函数。随后,使用
对每一行的元素做正则化,将它们归一化,以缩放到输出权值大小相等,使注意系数易于比较。注意力系数矩阵如下:

其中,所有的值都大于0,
是对
的平行的注意力系数矩阵。为了充分挖掘嵌入在多尺度特征中的信息,我们在公式5中引入了基于注意力的尺度策略,即,用学习到的注意系数对多尺度特征进行加权,于是公式5转变成:

融合特征用来作为最后一层预测层的输入,学习特征表示
,
是簇的个数。使用一个拉普拉斯平滑操作(Laplacian smoothing operator)和一个softmax函数用来得到预测的概率分布,公式如下:
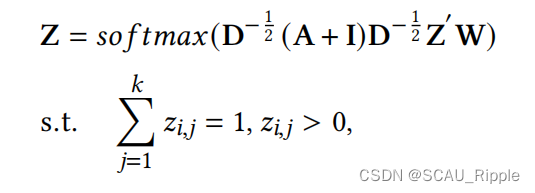
其中是可学习的参数。当网络是训练好的情况下,可以通过
直接得到预测的簇的标签:

其中是数据
对应的预测标签。
训练流程
步骤1
为了将该方法学习到的特征应用到聚类任务中,使用学生t-分布作为核,去衡量嵌入点和中心点的相似性。然后,模型交替精炼聚类结果,通过一个从当前的聚类软分配中得到的一个辅助目标分布,公式如下:

其中,,
表示
与其对应的簇中心向量
之间的相似性,
设为1。直接对
最小化KL散度会导致琐碎解,于是引入一个辅助目标分布
来避免崩溃问题:

其中,是
的元素
步骤2
在辅助目标分布的帮助下,对特征
和
进行KL散度最小化,公式如下:
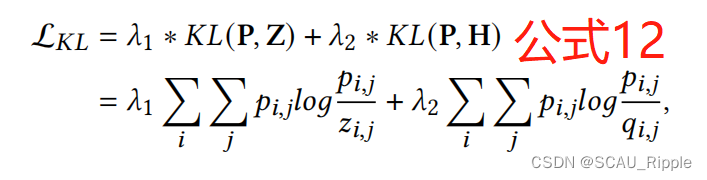
其中有,是权衡参数。通过最小化公式12,分布
可以很好的对齐。
于是全局损失函数为:
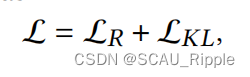
其中是AE的重构误差,
是合成特征
和AE的特征
的分布损失
本文的算法流程图

消融实验设计
对于AGCN-H和AGCN-S的消融
对不同尺度的特征消融
不同的k邻居的消融
一句话总结
本文对AE和GCN的结合方法,以及注意力机制的引入,值得参考
论文好句摘抄(个人向)
(1)Guo et al. [6] introduced a reconstruction loss to improve DEC for learning a better representation
(2)Although these works have achieved remarkable improvements, they simply focus on the node attribute feature and ignore the topological graph information embedded in the data.
(3)propose,develop,combine,design















 656
656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









