







引入
1.背景
大多数现有的MIL算法只能处理小规模或中等规模的数据。为了处理对于大规模的MIL问题,本文提出了两种高效、可扩展的MIL算法:miVLAD和miFV。
可扩展的算法
线性分类器的可扩展性
线性分类器
多视图数据
3.对比算法
解决实例标签丢失困难的算法
-
miSVM
通过搜索最大余量超平面来分离实例,从而为包中的实例显式分配标签 -
MIBoosting
假设每个实例对包含它的袋子的标签贡献独立且相等,并提出了一种Boosting方法来解决MIL问题 -
miGraph
将实例视为非i.i.d ,并将一个包映射到无向图来求解MIL问题
三种算法
最大余量超平面
Boosting方法
非i.i.d
包映射到无向图
将包转换为特征向量的算法
- MILES(迈尔斯算法)
- CCE方法
缺点:效率和准确性都不够成熟,不足以处理大规模的多实例学习数据集
3.本文算法
- miVLAD(基于VLAD表示的MIL)
- miFV(基于Fisher向量表示的MIL)
使用相应的映射函数将原始的MIL包映射到新的向量表示。
与CCE/MILES的主要区别在于所提出的方法将更多的信息编码到新的向量表示中
优势
- 处理大规模MIL数据
- 准确率相当,速度提高了数百倍
- 不进行参数调优
- 使用线性分类器都能得到很好的结果
- 包含更多包信息
多视图数据
互补信息
相关工作
相似度
半监督学习
多视图学习
算法1
1.VLAD and FV
VLAD 表示和FV 表示是计算机视觉中的两种方法,给定一幅图像和从该图像中提取的一组描述符(向量)(如SIFT),VLAD或FV将它们编码成高维向量。
图像表示为一组局部块,例如在被标记为高楼的图像中,其中局部块窗户、部分墙壁、天空、树的一部分等等
VLAD和FV可以将一组项目映射到一个单一向量。
2.符号集
实例空间:
X
\mathcal{X}
X
数据集:
{
(
X
1
,
y
1
)
,
…
,
(
X
i
,
y
i
)
,
…
,
(
X
N
B
,
y
N
B
)
}
\{(X_1,y_1),\dots,(X_i,y_i),\dots,(X_{N_B},y_{N_B})\}
{(X1,y1),…,(Xi,yi),…,(XNB,yNB)}
包:
X
i
X_i
Xi,
X
i
=
{
x
i
1
,
…
,
x
i
j
,
…
,
x
i
,
n
i
}
X_i=\{x_{i1},\dots,x_{ij},\dots,x_{i,n_i}\}
Xi={xi1,…,xij,…,xi,ni}
实例:
x
i
j
∈
X
x_{ij} \in \mathcal{X}
xij∈X,
[
x
i
j
1
,
…
,
x
i
j
l
,
…
,
x
i
j
d
]
[x_{ij1},\dots,x_{ijl},\dots,x_{ijd}]
[xij1,…,xijl,…,xijd]
特征值:
x
i
j
l
x_{ijl}
xijl
标签:
y
i
∈
Y
=
{
−
1
,
+
1
}
y_i \in \mathcal{Y}=\{-1,+1\}
yi∈Y={−1,+1}
训练包数量:
N
B
{N_B}
NB
对应包实例数:
n
i
n_i
ni
属性数量:
d
d
d
所有包的实例总数:
N
I
N_I
NI
对应包中的所有实例:
x
i
.
x_{i.}
xi.
所有包中的所有实例:
x
.
j
x_{.j}
x.j
聚类质心集合:
C
=
{
c
1
,
…
,
c
k
,
…
,
c
K
}
\mathcal{C}=\{c_1,\dots,c_k,\dots,c_K\}
C={c1,…,ck,…,cK},
c
k
=
N
N
(
x
i
j
)
c_k=NN(x_{ij})
ck=NN(xij),将实例分配到最近的质心
算法1 miVLAD算法
输入:
训练集 { ( X 1 , y 1 ) , … , ( X N B , y N B ) } \{(X_1,y_1),\dots,(X_{N_B},y_{N_B})\} {(X1,y1),…,(XNB,yNB)}
训练:
基于来自所有训练包的所有实例得到一个质心集合 C = { c 1 , … , c k , … , c K } \mathcal{C}=\{c_1,\dots,c_k,\dots,c_K\} C={c1,…,ck,…,cK}
遍历每一个包
通过映射函数得到一个新的特征向量
v i ← M v ( X i , C ) v_i \leftarrow \mathcal{M}_v(X_i,\mathcal{C}) vi←Mv(Xi,C)
对 v i v_i vi的每一个元素进行开根号,并通过sign()函数恢复符号
v i . l ← v_{i.l} \leftarrow vi.l←sign ( v i . l ) √ ∣ v i . l ∣ (v_{i.l})\surd{|v_{i.l}|} (vi.l)√∣vi.l∣
对特征向量进行归一化:对向量
v i ← v i / ∣ ∣ v i ∣ ∣ 2 v_i \leftarrow v_i/||v_i||_2 vi←vi/∣∣vi∣∣2
使用新的训练集合得到一个分类器 F \mathcal{F} F
测试:
遍历测试集中的测试包
通过映射函数得到 v i ′ v_{i^{'}} vi′
进行归一化得到 v i ′ v_{i^{'}} vi′
输出预测 F ( v i ′ ) \mathcal{F(v_{i^{'}})} F(vi′)
sign(x)或者Sign(x)叫做符号函数:
当x>0,sign(x)=1;
当x=0,sign(x)=0;
当x<0, sign(x)=-1
范数:参考
算法2 MiVLAD算法中的映射函数 M v \mathcal{M}_v Mv
输入:
包 X i X_i Xi中的所有实例 { x i 1 , … , x i j , … , x i , n i } \{x_{i1},\dots,x_{ij},\dots,x_{i,n_i}\} {xi1,…,xij,…,xi,ni}
簇质心的集合 C = { c 1 , … , c k , … , c K } \mathcal{C}=\{c_1,\dots,c_k,\dots,c_K\} C={c1,…,ck,…,cK}
输出:
表示包 X i 的 特 征 向 量 v i X_i的特征向量v_i Xi的特征向量vi
程序:
遍历每一个质心
通过表达式(1)计算 v i k v_{ik} vik
将 K K K个分量链接到一个向量 v i v_i vi
v i k l = ∑ x i j ∈ Ω x i j l − c k l (1) v_{ikl}=\sum_{x_{ij}\in \Omega}x_{ijl}-c_{kl}\tag1 vikl=xij∈Ω∑xijl−ckl(1)
Ω
=
{
x
i
j
∣
N
N
(
x
i
j
)
=
c
k
}
\Omega=\{x_{ij}|NN(x_{ij})=c_k\}
Ω={xij∣NN(xij)=ck}
即:
Ω
\Omega
Ω为最近簇心为
c
k
的
所
有
实
例
,
k
为
1
∼
K
c_k的所有实例,k为1\sim K
ck的所有实例,k为1∼K
v
i
k
l
v_{ikl}
vikl:特征向量
v
i
v_i
vi第k部分的第l个属性值
c
k
l
c_{kl}
ckl:是
x
i
j
x_{ij}
xij对应的最近质心
D
D
D:
v
i
v_i
vi的维度,
k
×
d
k \times d
k×d,即
v
i
是
一
个
二
维
向
量
v_i是一个二维向量
vi是一个二维向量
v
i
k
l
v_{ikl}
vikl:
v
i
v_i
vi第k部分的第
l
l
l个属性,即:包
i
i
i第
k
k
k分向量的第
l
l
l个属性值
公式(1):
x
i
j
x_{ij}
xij为既属于包
i
i
i,又属于
Ω
\Omega
Ω(即最近质心为k的实例)的实例;
其中实例属性值与质心实例对应属性值相减,每个实例得到的差值累加,即得到一个
v
i
v_i
vi元素值
v
i
k
l
v_{ikl}
vikl。
x
i
k
1
=
(
x
i
21
−
c
k
1
)
+
(
x
i
41
−
c
k
1
)
+
(
x
i
91
−
c
k
1
)
x_{ik1}=(x_{i21}-c_{k1})+(x_{i41}-c_{k1})+(x_{i91}-c_{k1})
xik1=(xi21−ck1)+(xi41−ck1)+(xi91−ck1)
x
i
k
2
=
(
x
i
22
−
c
k
2
)
+
(
x
i
42
−
c
k
2
)
+
(
x
i
92
−
c
k
2
)
x_{ik2}=(x_{i22}-c_{k2})+(x_{i42}-c_{k2})+(x_{i92}-c_{k2})
xik2=(xi22−ck2)+(xi42−ck2)+(xi92−ck2)
…
\dots
…
x
i
k
d
=
(
x
i
2
d
−
c
k
d
)
+
(
x
i
4
d
−
c
k
d
)
+
(
x
i
9
d
−
c
k
d
)
x_{ikd}=(x_{i2d}-c_{kd})+(x_{i4d}-c_{kd})+(x_{i9d}-c_{kd})
xikd=(xi2d−ckd)+(xi4d−ckd)+(xi9d−ckd)
v
i
k
=
{
x
i
k
1
,
x
i
k
2
,
…
,
x
i
k
d
}
v_{ik}=\{x_{ik1},x_{ik2},\dots,x_{ikd}\}
vik={xik1,xik2,…,xikd}
v
i
=
{
v
i
1
,
…
,
v
i
k
,
…
,
v
i
K
}
v_i=\{v_{i1},\dots,v_{ik},\dots,v_{iK}\}
vi={vi1,…,vik,…,viK}
目前:
改进miVLAD:选代表+映射
改进选代表的步骤:用轩哥的一个想法
1.从所有负包数据集中选出 n n n个代表实例 C = { c 1 , … , c n } \mathcal{C}=\{c_1,\dots,c_n\} C={c1,…,cn}
2.从每个正包中选出一个代表实例,得到 m m m个正包代表实例 P = { p 1 , … , p m } \mathcal{P}=\{p_1,\dots,p_m\} P={p1,…,pm}遍历每一个实例
遍历每一个 c i c_i ci
计算实例到 c i c_i ci的距离
求和
选择和最大的实例作为代表实例
3.从 m m m个正包代表中选择 k k k个代表,从 n n n个负包代表中选择 k k k个代表
4. 2 k 2k 2k个代表作为最后的代表
5.使用原来miVLAD的映射方法映射
1.试参数 ( n , m , k ) (n,m,k) (n,m,k)
2 . k = 1 .k=1 .k=1的情况下,只用其中一个作为最终代表
3.选负包代表实例和最终代表实例采用其他方式(除聚类外)
4. n n n与 m m m的大小差不多,从整个 n + m n+m n+m的空间中选k个最终代表
算法2
1.Fisher核的基础知识
-
S = { s t , t = 1 , … , T } S=\{s_t,t=1,\dots,T\} S={st,t=1,…,T}:是 T T T个观测值的一个样本
-
p p p:一个概率密度函数,用参数 λ λ λ模拟 S S S中元素的生成模型
-
G λ S G_λ^S GλS:梯度向量,如何修改参数λ,更好的拟合 S S S; G λ S G_λ^S GλS的维数只取决于 p p p中的参数个数,而不取决于样本大小 T T T;即将具有不同元素数量的集合转换成固定长度向量 G λ S G_λ^S GλS,这适用于miFV算法中的映射函数将具有不同实例数量的包映射成固定长度特征向量。
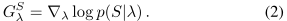
-
K F K \mathcal{K}_{FK} KFK:测量两个样本S1和S2之间的相似性
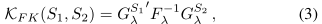
F λ F_λ Fλ:p的Fisher信息矩阵
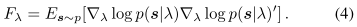
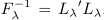
所以(3)中的FK可以显式地改写为点积
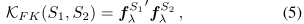
其中, -
f λ S f_λ^S fλS:即FV向量
我的理解:因为fv向量可以表示两包之间的相似性,则用fv向量表示包,作为特征向量
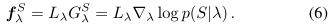
2.用FV表示包 -
K K K分量GMM理解
-
MLE:我们可以使用最大似然估计(MLE)来估计训练包上的GMM p的参数。
-
GMM的参数:λ={ w k w_k wk, μ k μ_k μk, Σ k Σ_k Σk,k=1, … , K \dots,K …,K}
w k w_k wk:混合权重
μ k μ_k μk:平均向量
Σ k Σ_k Σk:协方差矩阵

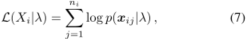
GMM可以表示为:一个概率密度函数,由K个GMM分量之和构成
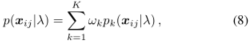
分量 p k p_k pk表示第 k k k次高斯
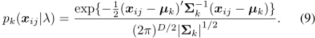
其中,
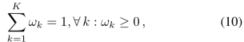
单个实例xij相对于高斯混合模型参数的梯度:
(我的理解:将 x i j x_{ij} xij代入概率密度函数 p p p之后,对其中的参数求偏导)
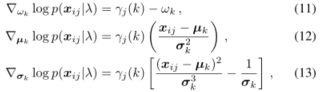
r
j
(
k
)
\mathcal{r}_j(k)
rj(k):
xij到Gaussk的软赋值,这也是由第k个高斯产生xij的概率:
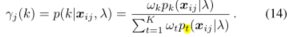
- FV向量的分量计算
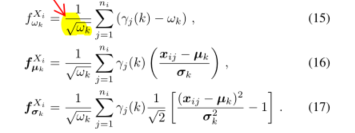
- 将FV分量串联成
f
λ
X
i
f_λ^{X_i}
fλXi
f w k X i f_{w_k}^{X_i} fwkXi:标量
f μ k X i f_{μ_k}^{X_i} fμkXi:d维向量
f σ k X i f_{σ_k}^{X_i} fσkXi:d维向量
f λ X i f_λ^{X_i} fλXi: ( 2 d + 1 ) K (2d+1)K (2d+1)K维
f λ X i = [ f w 1 X i f μ k X i f σ k X i … … … f w K X i f μ K X i f σ K X i ] {f_λ^{X_i}}=\left[ \begin{matrix} {f_{w_1}^{X_i}} & {f_{μ_k}^{X_i}} &{f_{σ_k}^{X_i}}\\ \dots& \dots&\dots\\{f_{w_K}^{X_i}} & {f_{μ_K}^{X_i}} &{f_{σ_K}^{X_i}}\end{matrix} \right] fλXi=⎣⎡fw1Xi…fwKXifμkXi…fμKXifσkXi…fσKXi⎦⎤
我对miFV的理解:
- 利用FV向量表示包,FV向量的表示需要求概率密度函数 p p p,利用GMM求该密度函数 p p p。
- 训练K个高斯模型,每一个高斯模型对应一组参数 w k w_k wk, μ k μ_k μk, Σ k Σ_k Σk。概率密度函数 p p p为由K个带权GMM分量之和。
- 使用最大似然估计(MLE)来估计训练包上的GMM p的参数
得到每一个高斯模型的参数后,对包 X i X_i Xi中的每个实例 x i j x_{ij} xij,分别求关于 w k w_k wk, μ k μ_k μk, Σ k Σ_k Σk的偏导,
分别 得到 K K K个 f w k X i f_{w_k}^{X_i} fwkXi, f μ k X i f_{μ_k}^{X_i} fμkXi, f σ k X i f_{σ_k}^{X_i} fσkXi,后串联为(2d+1)K的特征向量
其中GMM中的参数可以通过Python中的sklearn模块求得。
算法3 miFV中的映射函数 M f \mathcal{M}_f Mf
输入:
包 X i X_i Xi中的所有实例 { x i 1 , … , x i j , … , x i , n i } \{x_{i1},\dots,x_{ij},\dots,x_{i,n_i}\} {xi1,…,xij,…,xi,ni}
GMM参数λ={ w k w_k wk, μ k μ_k μk, Σ k Σ_k Σk,k=1, … , K \dots,K …,K}
输出:
描述包 X i X_i Xi的FV向量 f λ X i f_λ^{X_i} fλXi
过程:
遍历包中的 n i n_i ni个实例
(14)计算每个实例对应的 r j ( k ) \mathcal{r}_j(k) rj(k),即每个实例对应 K K K个 r j ( k ) \mathcal{r}_j(k) rj(k)
遍历 K K K个高斯模型
(15)计算分量 f w k X i f_{w_k}^{X_i} fwkXi
(16)计算分量 f μ k X i f_{μ_k}^{X_i} fμkXi
(17)计算分量 f σ k X i f_{σ_k}^{X_i} fσkXi
将3个分量串联成一个FV向量 f λ X i f_λ^{X_i} fλXi
算法4 miFV算法
输入:
训练数据 { ( X 1 , y 1 ) , … , ( X N B , y N B ) } \{(X_1,y_1),\dots,(X_{N_B},y_{N_B})\} {(X1,y1),…,(XNB,yNB)}
训练:
用MLE估计训练包上GMM p p p的参数λ={ w k w_k wk, μ k μ_k μk, Σ k Σ_k Σk}
遍历每一个包
将包映射为FV向量 f λ X i f_λ^{X_i} fλXi
对 f λ X i f_λ^{X_i} fλXi的每一个元素进行开根号,并通过sign()函数恢复符号
对特征向量进行归一化
其他
1.MIV&F:将包的VLAD和FV表示直接连接起来,形成一个新的表示。在大多数情况下,它可以获得比miVLAD/miFV更好的准确率。
2.主成分分析(PCA):在使用miVLAD和miFV中的映射函数之前,我们可以使用PCA来降低包中原始实例的噪声,或者降低它们的维数。miVLAD和miFV中只有两个参数,即中心数和PCA能量。
实验
数据集
-
MIL基准数据集:Musk1、Musk2、Elephant、Fox、Tiger
-
WebKB:文档分类,其中一个网页被视为一个正向包,不同的定长段落被视为实例。从WebKB中其余6个类别中随机抽取相同数量的阴性袋。
- Course、Faculty
-
图像分类数据集:
- 1000-Image、2000 -Image
-
大规模数据集
- Speaker:录音作为输入来识别说话者的性别
- Process:文本分类数据集
- TRECVID2005:用于视频注释任务
对比算法
MIWrapper 、CCE 、EM-DD、 miSVM、MIBoosting、miGraph、Simple-MI
对比方面
-
准确性比较
当在几个数据集上比较不同的算法时,可以使用Friedman检验来比较它们的整体性能 -
效率比较
-
可扩展性
为了验证我们提出的算法在不平衡测试数据集上的有效性,我们使用F1-Score作为标准:















 3687
3687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









