







时间:20220406
内容:labelme工具的安装和使用、jpg和json格式转VOC数据集
0 使用工具
labelme仓库: 里面有安装教程
https://gitcode.net/mirrors/wkentaro/labelme?utm_source=csdn_github_accelerator
新建环境labelme
conda create --name=labelme python=2.7(这一步python=*选择自己的Python版本)
activate labelme
conda install pyqt
pip install labelme
在终端输入labelme启动软件
activate labelme
labelme
如下图:

1 数据集转换
准备好jpg+json数据集,一个jpg对应一个json,命名data_annotated。
把要处理的数据 data_annotated 和 要执行的python文件 labelme2voc.py 、labels.txt放在一个文件夹下。
labelme2voc.py :
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import sys
import imgviz
import numpy as np
import labelme
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("input_dir", help="input annotated directory")
parser.add_argument("output_dir", help="output dataset directory")
parser.add_argument("--labels", help="labels file", required=True)
parser.add_argument(
"--noviz", help="no visualization", action="store_true"
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "SegmentationClass"))
os.makedirs(osp.join(args.output_dir, "SegmentationClassPNG"))
if not args.noviz:
os.makedirs(
osp.join(args.output_dir, "SegmentationClassVisualization")
)
print("Creating dataset:", args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in glob.glob(osp.join(args.input_dir, "*.json")):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_lbl_file = osp.join(
args.output_dir, "SegmentationClass", base + ".npy"
)
out_png_file = osp.join(
args.output_dir, "SegmentationClassPNG", base + ".png"
)
if not args.noviz:
out_viz_file = osp.join(
args.output_dir,
"SegmentationClassVisualization",
base + ".jpg",
)
with open(out_img_file, "wb") as f:
f.write(label_file.imageData)
img = labelme.utils.img_data_to_arr(label_file.imageData)
lbl, _ = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=label_file.shapes,
label_name_to_value=class_name_to_id,
)
labelme.utils.lblsave(out_png_file, lbl)
np.save(out_lbl_file, lbl)
if not args.noviz:
viz = imgviz.label2rgb(
lbl,
imgviz.rgb2gray(img),
font_size=15,
label_names=class_names,
loc="rb",
)
imgviz.io.imsave(out_viz_file, viz)
if __name__ == "__main__":
main()
制作labels.txt文件:
__ignore__
_background_
class1
class2
...
classn
在终端cd到这一文件夹。
执行:
python ./labelme2voc.py data_annotated data_dataset_voc --labels labels.txt

即可。
转换结果:
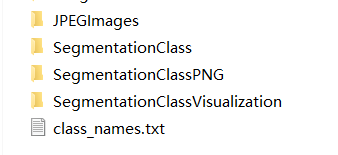
也可以转换CoCo数据集。希望能帮到你。
2 补充 VOC数据集使用和训练集划分
除了生成的几个文件和文件夹,VOC数据集 还需要一个叫 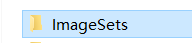
的文件夹,里面是train.txt val.txt
这两个文件里面是没有后缀的文件名。
制作:
import os
import shutil
from random import randrange
import os.path as osp
import mmcv
def divide_img(scale, images_path, save_txt_path):
modnum = randrange(scale) # 首先随机生成一个随机数
# 开始划分训练集和测试集并保存名字
# 遍历根文件夹
i = 0
for imagename in os.listdir(images_path): # 获取具体的文件名称
# 去除后缀
imagename_null = str(imagename[:-4])
print(imagename_null)
if i % scale == modnum: # 划分为测试集
# save_path = save_txt_path + '/'
# shutil.copy(src=src_image, dst=save_path)
with open(osp.join(save_txt_path, 'test.txt'), 'a') as f:
# train_length = int(len(filename_list))
f.writelines(str(imagename_null) + '\n')
print("write in!")
elif i % scale == modnum + 1:
with open(osp.join(save_txt_path, 'val.txt'), 'a') as f:
# train_length = int(len(filename_list))
f.writelines(str(imagename_null) + '\n')
print("write in!")
else: # 划分为训练集
with open(osp.join(save_txt_path, 'train.txt'), 'a') as f:
# train_length = int(len(filename_list))
f.writelines(str(imagename_null) + '\n')
print("write in!")
# 一轮结束
if i % scale == 0 and i != 0: # 将数据集划分,每次处理完scale张图片后变化一次随机数
modnum = randrange(scale)
i = i + 1
if __name__ == '__main__':
ann_dir = 'img/SegmentationClassPNG' # 即图片所在文件夹 img/SegmentationClassPNG
txt_path = 'splits' # 后为img/divide
# 随机生成训练集和测试集,比例为8:1
scale = 14
divide_img(scale, ann_dir, txt_path)
print("finish")
2022年9月1日:
划分的代码不够完善 补充了test集














 1879
1879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









