







博客文章内需要的文件: 文件
pandas学习路线:
Python-Pandas{数据结构与基本功能
Python-Pandas{描述与统计功能}
Python-pandas{缺失值处理}
Python-pandas{文本数据处理}
Python-pandas{数据分组}
描述与统计
有时候我们获取到数据之后,想要查看下数据的简单统计指标(最大值、最小值、平均值、中位数等),比如想要查看年龄的最大值,如何实现呢?直接对 age 这一列调用 max方法即可。
# 先导包
import numpy as np
import pandas as pd
# 读取文件
grade = pd.read_csv('student_grade.txt',sep='\t')
grade

# 常用函数
np.max(grade.数学) # 148
# 归约函数
grade.英语.mean() # 109.0
grade.总分.sum() #21748
类似的,通过调用 min、mean、quantile、sum 方法可以实现最小值、平均值、中位数以及求和。可以看到,对一个 Series调用 这几个方法之后,返回的都只是一个聚合结果。
如果想要获取更多的统计方法,可以参见官方链接:pandas 虽然说常见的各种统计值都有对应的方法,如果我想要得到多个指标的话,就需要调用多次方法,是不是显得有点麻烦呢?
Pandas 设计者自然也考虑到了这个问题,想要一次性获取多个统计指标,只需调用 describe 方法即可
| Function | Description |
|---|---|
count | Number of non-NA observations 统计个数 |
sum | Sum of values 加和 |
mean | Mean of values 平均数 |
mad | Mean absolute deviation 平均绝对偏差 |
median | Arithmetic median of values 中位数 |
min | Minimum 最小值 |
max | Maximum 最大值 |
mode | Mode 众数 |
abs | Absolute Value 绝对值 |
prod | Product of values 乘积 |
std | Bessel-corrected sample standard deviation 标准差 |
var | Unbiased variance 方差 |
sem | Standard error of the mean 平均标准误差 |
skew | Sample skewness (3rd moment) 偏度 |
kurt | Sample kurtosis (4th moment) 峰度 |
quantile | Sample quantile (value at %) 分位数 |
cumsum | Cumulative sum 累加 |
cumprod | Cumulative product 累乘 |
cummax | Cumulative maximum 累计最大 |
cummin | Cumulative minimum 累计最小 |
# 上四分位数
# 四分位数(Quartile)也称四分位点,是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。
grade.数学.quantile(q = 0.75) # 127.25
# 众数
# 众数是在一组数据中,出现次数最多的数据,是一组数据中的原数据,而不是相应的次数
grade.数学.mode() #
查看基本统计值
可以直接使用.describe查看
# 只支持数值列
grade.describe()

统计下某列中每个值出现的次数value_counts
imdb = pd.read_csv('imdb_1000.csv')
imdb

# 我想统计在这个数据集当中, 不同的类型,分别出现了多少次
imdb.genre.value_counts()
'''
Drama 278
Comedy 156
Action 136
Crime 124
Biography 77
Adventure 75
Animation 62
Horror 29
Mystery 16
Western 9
Thriller 5
Sci-Fi 5
Film-Noir 3
Family 2
Fantasy 1
History 1
Name: genre, dtype: int64
'''
离散化
有时候,我们会碰到这样的需求,想要将年龄进行离散化(分桶),直白来说就是将年龄分成几个区间,这里我们想要将年龄分成 3 个区间段。就可以使用 Pandas 的 cut 方法来完成。
# 将英语成绩平均分成四个不同的等级
pd.cut(grade.英语, 4) # 将数据均匀切分成4份
'''
0 (116.5, 144.0]
1 (116.5, 144.0]
2 (116.5, 144.0]
3 (116.5, 144.0]
4 (116.5, 144.0]
...
63 (61.5, 89.0]
64 (33.89, 61.5]
65 (33.89, 61.5]
66 (33.89, 61.5]
67 (33.89, 61.5]
Name: 英语, Length: 68, dtype: category
Categories (4, interval[float64]): [(33.89, 61.5] < (61.5, 89.0] < (89.0, 116.5] < (116.5, 144.0]]
'''
# 我们发现,cut方法,把英语成绩分成了[(33.89, 61.5] < (61.5, 89.0] < (89.0, 116.5] < (116.5, 144.0]]这样的四份
# 其实我们可以设置参数
pd.cut(grade.英语, 4, labels=['最差','挺差','凑活','不错'] ) # 将数据均匀切分成4份
'''
0 不错
1 不错
2 不错
3 不错
4 不错
..
63 挺差
64 最差
65 最差
66 最差
67 最差
Name: 英语, Length: 68, dtype: category
Categories (4, object): [最差 < 挺差 < 凑活 < 不错]
'''
#有时候离散化之后,想要给每个区间起个名字,可以指定 labels 参数。
# 指定切割点
# [0-90) 不及格
# [90 - 120) 几个
# [120 - 135) 良好
# [135 - 150) 优秀
pd.cut(grade.英语, bins=[-1,90,120,135,151],right=False,labels=['不及格','及格','良好','优秀'] )
# 其中从-1开始一定包含0分,到151结束一定包含 150分
# right 参数为 Ture为左开右闭区间,False为左闭右开区间
'''
0 优秀
1 优秀
2 优秀
3 优秀
4 优秀
...
63 不及格
64 不及格
65 不及格
66 不及格
67 不及格
Name: 英语, Length: 68, dtype: category
Categories (4, object): [不及格 < 及格 < 良好 < 优秀]
'''
# 那么就可以在grade上新增一列
grade['英语等级'] = pd.cut(grade.英语, bins=[-1,90,120,135,151],right=False,labels=['不及格','及格','良好','优秀'] )
grade

# 班名次切分
# 前5名: 学神
# 6 -15 学霸
# 16 - 40名 学徒
# 41 - 最后 学渣
grade['称号'] = pd.cut(grade.班名次, bins= [0,5,15,40,68], labels=['学神','学霸','学徒','学渣'])
grade

但是我们发现,自定义的划分,每一个阶段的样本数量都是不同的。比如说:
pd.cut(grade.英语, 4, labels=['最差','挺差','凑活','不错'] ).value_counts() # 将数据均匀切分成4份
'''
不错 37
凑活 14
挺差 11
最差 6
Name: 英语, dtype: int64
'''
除了可以使用 cut 进行离散化之外,qcut 也可以实现离散化。
cut是根据每个值的大小来进行离散化的qcut是根据每个值出现的次数来进行离散化的。
# 等深分箱
pd.qcut(grade.语文,4)
'''
0 (118.0, 131.0]
1 (118.0, 131.0]
2 (118.0, 131.0]
3 (118.0, 131.0]
4 (118.0, 131.0]
...
63 (65.999, 100.5]
64 (65.999, 100.5]
65 (65.999, 100.5]
66 (65.999, 100.5]
67 (65.999, 100.5]
Name: 语文, Length: 68, dtype: category
Categories (4, interval[float64]): [(65.999, 100.5] < (100.5, 111.5] < (111.5, 118.0] < (118.0, 131.0]]
'''
# 等深分箱, 每一个类别样本个数非常接近
pd.qcut(grade.语文,4).value_counts()
'''
(111.5, 118.0] 19
(100.5, 111.5] 17
(65.999, 100.5] 17
(118.0, 131.0] 15
Name: 语文, dtype: int64
'''
排序功能
在进行数据分析时,少不了进行数据排序。Pandas 支持两种排序方式:按实际值排序和按轴(索引或列)排序。
按值排序
如果想要实现按照实际值来排序,例如想要按照年龄排序,如何实现呢?使用 sort_values 方法,设置参数 by=“age” 即可。
# by, 以哪一列进行排序
# ascending=True, 升序和降序。默认为升序
# inplace = True:不创建新的对象,直接对原始对象进行修改;
# inplace = False:对数据进行修改,创建并返回新的对象承载其修改结果。
grade.sort_values(by='数学',ascending=False)

#以多列进行排序, 如果数学分数相同的, 我们谁语文高谁排前边
grade.sort_values(by=['数学','语文'],ascending=False)

#以多列进行排序, 如果数学分数相同的, 我们谁语文高谁排前边
grade.sort_values(by=['数学','语文'],ascending=False,inplace=True)
# 这里我们设置了inplace的参数设置为Ture,则在原来的数据上进行修改,并不创建新的数据
grade

按索引排序:
sort_index 方法默认是按照索引进行正序排的。
grade.sort_index(inplace=True)
grade

函数应用
虽说 Pandas 为我们提供了非常丰富的函数,有时候我们可能需要自己定制一些函数,并将它应用到 DataFrame 或 Series。常用到的函数有:
- map
- applymap
map
map 是 Series 中特有的方法,通过它可以对 Series 中的每个元素实现转换。可以理解为是映射
python中的内置函数map
L = [1,2,3,4,5,6,7,8,9]
# map(func, *iterables)
# 第一个参数为放函数,而不是调用函数。
# map: 我们写一个函数,能够对L中的一个元素,放大两倍
def f(x):
return x*2
list(map(f,L)
'''
[2, 4, 6, 8, 10, 12, 14, 16, 18]
'''
# 奇数缩小10倍,偶数放大10倍
def f2(x):
if x %2 == 1:
return x / 10
else:
return x * 10
list(map(f2,L))
'''
[0.1, 20, 0.3, 40, 0.5, 60, 0.7, 80, 0.9]
'''
s = list("海内存知己,天涯欧比例")
def f3(x):
return x * 4
','.join(list(map(f3,s)))
'''
'海海海海,内内内内,存存存存,知知知知,己己己己,,,,,,天天天天,涯涯涯涯,欧欧欧欧,比比比比,例例例例'
'''
Series中的map方法
def f(x):
if x % 2 == 0:
return '偶数'
else:
return "奇数"
grade['数学奇偶'] = grade.数学.map(f)
grade

grade.数学奇偶.value_counts()
'''
奇数 42
偶数 26
Name: 数学奇偶, dtype: int64
'''
def f(x):
if x < 90:
return "不及格"
elif x <120:
return "及格"
elif x < 135:
return "良好"
else:
return "优秀"
grade["语文等级"] = grade.语文.map(f)
grade

小练习
# 提取每一个人的姓氏
def f(x):
return x[0]
grade.姓名.map(f)
# 提取每一个人的命
def f(x):
return x[1:]
grade.姓名.map(f)
# 将男,女,转换为0,1
# grade中先添加一列性别,随机生成
temp = np.random.choice(['男','女'],68)
grade['性别'] = temp
def f(x):
if x == "男":
return 0
else:
return 1
grade.性别.map(f)
grade["性别编码"] = grade.性别.map(f)
grade[["姓名","性别","性别编码"]]
applymap方法
applymap 方法针对于 DataFrame,它作用于 DataFrame 中的每个元素,它对 DataFrame 的效果类似于 apply 对 Series 的效果。
def f(x):
if x >= 100:
return "好"
else:
return "差"
grade[['语文','数学','英语']].applymap(f)

小练习
提取出 语文数学英语。凡是分数低于90分的,一律改为90分
def f(x):
if x < 90:
x = 90
return x
grade[['语文','数学','英语']].applymap(f)
修改列/索引名称
在使用 DataFrame 的过程中,经常会遇到修改列名,索引名等情况。使用 rename 轻松可以实现。
修改列名只需要设置参数 columns 即可。
grade.rename(columns={'姓名':'name','语文':'Chinese','数学':'math'}) # 字典形式修改

# rename 也支持函数形式
def fs(x):
return x[0]
grade.rename(columns = fs)

上面显示的修改列名,那么我们试一下修改行
# index 为索引
def f(x):
return x * 2
grade.rename(index = f)

表合并方式
appendDataFrame的方法,直接在该表后面进行追加。
# 这里我们重新导入数据
grade = pd.read_csv('student_grade.txt',sep='\t')
# 首先获取前五条作为第一个表格
grade_one = grade.head().copy()
# 首先获取第三个到第七个数据作为第一个表格
grade_two = grade.iloc[3:8]
# 列索引进行拼接
grade_one.append(grade_two) # 默认上下拼接

# 假如说,我们现在有一个表并不是按照正常顺序排列
grade_three = grade_two.sort_index(axis = 1)
grade_three

# grade_one 和 grade_three 的列顺序是完全不一样的
# 这里进行表连接的时候 ,就要用到sort参数了
# sort = Ture 不以原表为准,那就是以grade_three为准
# sort = False 就是以原表为准,这里就是以grade_one为准
grade_one.append(grade_three,sort = True)

grade_one.append(grade_three,sort = False)

# 此外我们发现,表连接之后,行索引就是原来表的索引
# ignore_index=False 不改变索引,默认就是False
# ignore_index=Ture 重新改变索引,以0为开始
grade_one.append(grade_three,sort = False, ignore_index=True)

.concat函数, 可以通过指定轴,来进行不同方向的拼接, 拼接是以索引值相同作为拼接的方法. 拼接的是结构和内容相同的表。
# concat 主要就是确定知道轴来连接表,默认是 axis = 0
pd.concat([grade_one,grade_two])

pd.concat([grade_one,grade_two],axis=1) # 以axis = 1进行连接

# join参数主要有两个选择
# inner:交集
# outer : 并集
pd.concat([grade_one,grade_two],axis=1,join='inner')

.merge函数, 数据库拼接: 使用场景: 把几个关系型数据表格按照某个字段进行拼接, 拼接的是不同的表。其实与SQL表连接是一个意思
grade_one
d = {'姓名':['韩林霖','王雪','沙龙逸','杨璐','张三'],
'寝室':[302,201,302,201,404]}
room = pd.DataFrame(d)
# how = left 左连接
# how = right 右连接
# how = inner ,交集,默认为inner
# how = outer ,并集
# on 字段
grade_merge = pd.merge(grade_one,room,on='姓名') # 使用哪一个字段进行连接
grade_merge
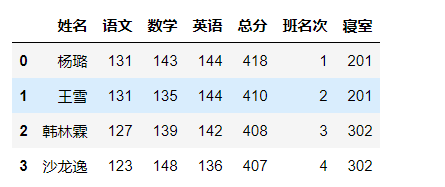
grade_merge = pd.merge(grade_one,room,on='姓名',how='left')
grade_merge

grade_merge = pd.merge(grade_one,room,on='姓名',how='right')
grade_merge

grade_merge = pd.merge(grade_one,room,on='姓名',how='outer')
grade_merge
















 6806
6806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









