







语言探幽
前言:完整的总结总是劳神耗时的,已经熟稔的或者易于得到的部分也没有总结下来的必要。然遨游码海,总归有一些需要记忆的小点,好记性不如烂笔头,单开一篇又没必要,索性全归为一篇,作为手册。而本文正是码海拾遗姊妹篇——语言探幽。主要记载一些在编程语言中碰到的小知识小技巧。
1 C
1.1 语法&特性
宏
- 宏的拼接:
#拼接为字符串,##拼接为一个整体 ⭐️##连接符和#符的使用 ⭐️字符串化和合并操作符 - 宏的一次执行:
#define FUNC(EXP) do{xxx} while(0),用 do-while(0) 可以避免一些bug
1.2 函数速查
(可以参考本地文件[C函数速查](file://D:/books/C/C函数速查.pdf))
⭐️笔试输入输出
/* (1) 类型混排
* push 123
* pop
* front
*/
scanf("%s %d", &str, &x);
// %s 是以空白符为界定的,因此不用担心会读取一行
/* (2) 读取一行
*/
scanf("%[^\n]", &line); // scanf 可以进行简单的模式匹配
getline(&line, &size, stdin); // posix 的函数,可以自动分配大小
fgets(line, size, stdin); // 读取指定数目或一行
printf
-
打印颜色
颜色控制码-cnblogs// 一般格式为 printf("\033[控制码1;控制码2;控制码3...m %s \033[控制码m\n", str); // 例如下面将输出一个黄色的str printf("\033[32m %s \033[0m \n", str);


-
打印数据类型
维基百科-printf-format 参考-runoob.com
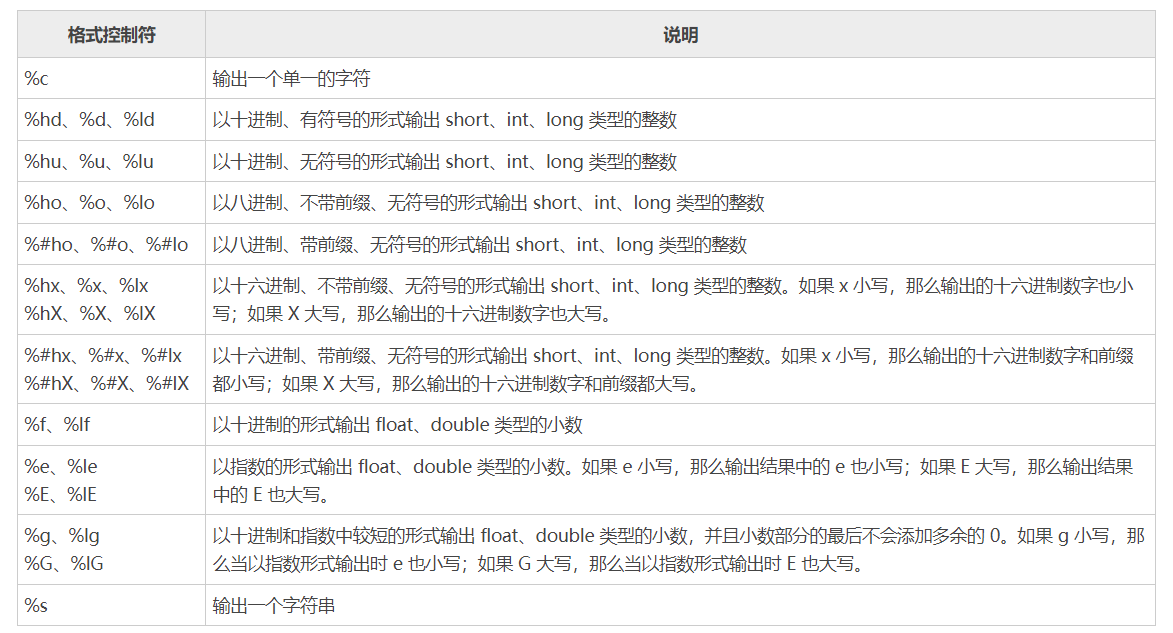
a A:以十六进制形式输出浮点数(C99)z:输出size_t类型的推荐做法
-
位宽限定符:
%[width]d:限定整数的最小位宽,可以用数字替代[width],如%5d表示整数占5位宽度。%[width].[precision]f:限定浮点数的位宽和小数点后的位数,可以用数字替代[width]和[precision],如%8.2f表示浮点数占8位宽度,小数点后保留2位。%[width]s:限定字符串的最小位宽,可以用数字替代[width],如%10s表示字符串占10位宽度。
-
填充限定符:
%-[width]d:左对齐限定整数的最小位宽,可以用数字替代[width],如%-5d表示整数左对齐并占5位宽度。%0[width]d:用零填充限定整数的最小位宽,可以用数字替代[width],如%04d表示整数用零填充并占4位宽度。
-
变参限定符:
%*c:动态指定字符的宽度,可以通过传递参数给printf()函数来指定字符的宽度,如printf("%*c", 5, '*')表示打印一个宽度为 5 的字符*。%.*s:动态指定字符串的宽度,可以通过传递参数给printf()函数来指定字符串的宽度,如printf("%.*s", 8, "Hello, World!")表示打印字符串的前 8 个字符。
-
其他特殊格式化方法:
%n:将已经打印的字符数保存到对应的int变量中,例如printf("Hello, %s%n", "World!", &count),count将保存字符串 “Hello, World!” 的字符数。%m:输出上一个发生的错误消息(通常与错误处理相关)。%p:打印指针的地址。
sprintf & vsprintf
二者都能格式化输出到字符串,区别在于,v系列能“定制”,你可以将其封装到你的函数中去,以应对参数不确定的情况。
#include <stdio.h>
int printf(const char *format, ...); // 到标准输出
int fprintf(FILE *stream, const char *format, ...); // 到文件
int dprintf(int fd, const char *format, ...); // 到文件
int sprintf(char *str, const char *format, ...); // 到字符串
int snprintf(char *str, size_t size, const char *format, ...); // 到字符串
#include <stdarg.h>
int vprintf(const char *format, va_list ap); // 也到标准输出
int vfprintf(FILE *stream, const char *format, va_list ap); // 也到文件
int vdprintf(int fd, const char *format, va_list ap); // 也到文件
int vsprintf(char *str, const char *format, va_list ap); // 也到字符串
int vsnprintf(char *str, size_t size, const char *format, va_list ap); // 也到字符串
字符串处理
(1)输入输出:
//(1) <stdio.h>:
// 成功返回 s,失败返回 NULL;会把换行符读进 s 里面(做字符串比较的时候要注意)
char *fgets( char *s, int size, FILE *stream);
// 成功返回 nonnegative number,失败返回 EOF;不会输出 '\0',但会输出 '\n'到 stream 里面
int fputs(const char *s, FILE *stream);
//会读取换行符进入目标; 当 lineptr 已经被 malloc,但是不够大,则会自动 relloc;当目标为空指针,且 n 为 0 的时候会自动 malloc;无论getline成功与否,都要由用户来负责 free 这块内存
ssize_t getline (char **lineptr, size_t *n, FILE *stream);
ssize_t getdelim(char **lineptr, size_t *n, int delim, FILE *stream);
(2)处理:
// (1)查找
// 返回指向首次出现needle的指针。如strstr("hello", "ll");则返回指向第一个l的指针
char *strstr (const char *str, const char *needle);
// 返回指向首次出现字符c位置的指针
char *strchr (const char *str, int c);
// 查找 str 中,第一个不在 accept 列表中的字符位置
char *strpbrk(const char *str, const char *accept);
// 查找 str 中,开头出现 accept 中字符的个数。如str=“ABABCDE”,accept=“ABD”,则返回 4
size_t strspn (const char *s, const char *accept);
// 查找 str 中,开头 不 出现 reject 中字符的个数
size_t strcspn(const char *s, const char *reject);
// (2)比较字符串,相等返回 0
int strcmp (const char *s1, const char *s2); // 比较
int strncmp (const char *s1, const char *s2, size_t n); // 比较前 n 个字符
int strcasecmp (const char *s1, const char *s2); // 比较,但不区分大小写
int strncasecmp(const char *s1, const char *s2, size_t n); // 比较前 n 个字符且不区分大小写
// (3)以 delim 为分隔符,分割 str (一般要用到循环,即while(token != NULL) )
// 第一次调用要指明 str; 后面的每一次想分割同一个字符串的调用,都要把 str 置为 NULL
// 返回值是分割得到的子串,剩余部分是保存在内核(?)中,因此后续调用不再传递 str
char *strtok(char *str, const char *delim);
(3)格式转换:
// 字符串转为别的数据类型
#include <stdlib.h>
double atof (const char *nptr);
int atoi (const char *nptr);
long atol (const char *nptr);
long long atoll(const char *nptr);
2 C++
2.1 语法&特性
返回值-NRV
有一条语句,A a = f();其中f()是一个函数,函数里边申请了一个A的对象b,然后把对象b返回。在对象返回的时候,一般情况下要调用拷贝函数,把函数f()里边的局部对象b拷贝到函数外部的对象a。但
NRV:具名返回值优化(Named Return Value)简单的说就是,如果用了NRV优化,那就不必要调用拷贝构造函数,编译器可以这样做,把a的地址传递进函数f(),然后不让f()申请要返回的对象b的空间,用a的地址来代替b的地址,这样当要返回对象b的时候,就不必要拷贝了,因为b就是a,省去了局部变量b,省去了拷贝的过程。
指针传参
指针作为参数传递,也是传值,即拷贝一份指针。这同样意味着你在函数中对指针的操作,并不会真正改变原指针。这里要注意理解:不改变的,是指针指向哪里,但是你却可以通过这个指针,真实的改变原来指针指向的内容。
如果你想修改一个值,你可以传递指向它的指针(或引用)。因此如果你想修改指针的值(即指针的指向),那么你就要传递指向指针的指针(或指针的引用)。
但是要注意,如果你修改了指针的指向,那么原来指针的指向也会变,这就意味着,原来指针指向的那一块内存区域可能无法引用了,那就会造成内存泄漏。
类
(1) 语法
- 一些“关键字”:
inline(外部函数变为内联)、const(不修改)、default()、explict(不隐式类型转换)、virtual(虚函数、虚继承)、static(类成员/静态成员)、using(可以在基类中隐藏父类的public继承来的东西) - 初始化列表:构造函数后以
:开始,进行初始化。- 静态成员只能在类内定义,类外初始化,不能出现在初始化列表中(因为一个类只含有一份?)
- 基类的构造函数,也在初始化列表中调用
D(int a, int b, int c) : B(a, b), _c(c)(如果基类没有默认构造函数,那子类必须显示调用) - 初始化顺序只看声明顺序(以及构造函数调用顺序),与初始化列表出现顺序无关。(注意区别,跟出现次序有关的是多继承时,构造函数的调用顺序)
- 子类只关心父类的初始化,不管再往上几辈的事,爷爷类自有父类负责(虚基类除外:子类还要调用虚基类的构造函数来初始化虚基类子对象,每个低层次的类都要写,但是实际上只有最派生类执行)【最派生类】:建立对象时所指定的类
- 构造与析构函数
- 构造函数调用顺序:虚基类 ⇒ \Rarr ⇒ 父类(按声明左到右) ⇒ \Rarr ⇒客人(类类型数据,按定义前到后) ⇒ \Rarr ⇒ 自己。析构顺序与之相反
- 不管显示还是隐式,基类总是要调用父类的构造函数,以及析构函数的。因此可以用子类的指针来析构父类,但父类的指针不会析构子类
- 类型适应:当且仅当
- 继承不会继承基类的构造和析构函数;
- 虚继承:虚继承即让某个类做出声明,承诺愿意共享它的基类。其中,这个被共享的基类就称为虚基类。目的是解决菱形继承问题 ⇒ \Rarr ⇒同名虚基类,在对象中只会产生一份虚基类子对象(全部父类加上子类,共享一个虚基类子对象)
(2) 内存布局
- 成员函数在代码区,不占有对象的内存。成员函数中定义的局部变量是“共享的”
- 有虚函数的,对象首块内存会存放一个指向虚表的指针。可以
(void **)(*(void**)&obj) - 有继承的,子类中先出现的是父类中的数据成员(基类子对象),然后紧跟着是自己的数据成员
- 如果父类中有虚函数,子类也会有一个虚表,如果没有重写父类的虚函数,那虚表中项目就指向父类的虚函数,如果重写了,那就指向子类的虚函数
(3) 常见问题
- 拷贝构造函数参数:
- 深浅拷贝:
- 虚构造函数与虚析构函数:
关键字和上下文关键字
// delete
void func(int)=delete;
// override, final
void f() override final;
类模板与友元函数
// 模板类中声明友元函数共有四种:
template <typename T>
class A{
public:
friend void f1(); // 1.不需要模板参数的,非模板函数
friend void f2(A<T>& a); // 2.需要模板参数的,非模板函数
friend void f3<T>(A<T>& a); // 3.需要模板参数的,模板函数
template <typename U> // 4.需要模板参数且自带参数的模板函数
friend void f4(A<U>& a);
private:
T v;
};
不要在类内声明的是第二种,在类外定义的却是第三种了。
智能指针
Lambda 表达式
auto foo = [capture](parameters)->return_type {func_body}
-
[capture] 用来捕获表达式外部的变量:
-
:无捕获,函数体内不能访问任何外部变量
-
[ = ] :以值(拷贝)的方式捕获所有外部变量,函数体内可以访问,但是不能修改。
-
[ & ] :以引用的方式捕获所有外部变量,函数体内可以访问并修改(需要当心无效的引用);
-
[ var ] :以值(拷贝)的方式捕获某个外部变量,函数体可以访问但不能修改。
-
[ &var ] :以引用的方式获取某个外部变量,函数体可以访问并修改
-
[ this ] :捕获this指针,可以访问类的成员变量和函数
-
[ =,&var ] :引用捕获变量var,其他外部变量使用值捕获。
-
[ &,var ] :只捕获变量var,其他外部变量使用引用捕获。
-
-
(parameters):即自定义函数里面的参数,只能在表达式的封闭范围内用
-
返回值可以自动推断
2.2 库与函数速查
输入输出
⭐️getline()
-
有两个getline()函数,一个在<istream>里面,通过(输入流)成员调用的方式指出输入流,一个在<string>里面,为顶层函数,在参数列表中指出输入流
-
getline()实际读取的为==(n - 1)个字符,且会把终止符从流中删除==
-
读到文件尾返回eofbit
// # include<istream> // 注意是char*,同时要指出读入的size
istream& getline (char* s, streamsize n, char delim );
// # include<string>
istream& getline (istream& is, string& str, char delim);
⭐️get()
-
与getline()区别在于,读到delim字符后,会中止并将其保留在流中,这就会被下一个用户读到
-
只有<istream>版本
// 依次为:single character (1),c-string (2),stream buffer (3)
int get(); istream& get (char& c);
istream& get (char* s, streamsize n, char delim);
istream& get (streambuf& sb, char delim);
正则表达式
<regex>库是C11中新增的特性,下面给出一些使用的例子
regex:定义一个正则表达式类,如regex rx("^[0-9]");
match_result:
2.3 标准库STL
⭐️黑马 ⭐️STL底层数据结构总结
数组
(1) vector
- vector的大小。里面似乎存放的只是几个指针而已,start、fin等。在使用
umap时候发现的
string类
栈与队列
(1) priority_queue
template<
typename T, // 类型
typename Container = std::vector<T>,
typename Compare = std::less<typename Container::value_type>
> class priority_queue;
优先队列的底层实现是二叉堆,插入时,让使 Compare 返回 true 的元素下沉(sink)。
使用时容易模糊的就在于,Compare 怎么定义(讨论的是自定义类型,而非POD)。一般的策略有:在类型中重载 < 运算符,则即可缺省 compare,或定义仿函数
//(1) Comp缺省,自定义类型中,重载或友元重载小于 < 运算符
struct ListNode {
bool operator< (const ListNode&){}
friend operator< (const ListNode&, const ListNode&){}
}
//(2) Comp为仿函数(即定义一个类Comp,然后重载它的括号运算符)
Class Comp{
bool operator()(const T&, const T&){}}
常用的操作有push(), pop(), top(), empty()
集合 与 映射
(1) set
⭐️cpp-reference ⭐️[set博客总结](c++ stl库中的set - 然终酒肆 - 博客园 (cnblogs.com))
template<
typename Key,
typename Compare = std::less<Key>,
typename Allocator = std::allocator<Key>
> class multiset;
注意四个版本:set, multiset, unordered_set, unordered_multiset
默认有序是升序,(只需使用 rbegin()和rend()就能的到逆序的)
常用操作:insert、find、count、clear、empty
(2) map
⭐️map用法详解
默认按关键字升序,STL中的有序均是升序,因此需要重载的只是小于号 < < <
链表
(1) list
template<
typename T,
typename Allocator = std::allocator<T>
> class list;
双向链表
front、back、push_back、pop_front、insert、erase、remove_if、sort、unique、reverse
(2) forward_list
单项链表
3 python
3.1 语法
数据结构
函数
@funcA def funcB(): ...:其中 @funcA是函数装饰器,它有两步工作:- 将 funcB 作为参数传给 funcA() 函数,也就是说函数 A 的参数是一个函数,在A里面可以执行的
- 将 funcA() 函数执行完成的返回值反馈回 B,也就是说 B 的返回值是在A中返回的,是A以B为参数的执行结果
strip():去除两端多余字符串
类
class D(A, B, C) :表示 D 继承 A B Csuper().__init__():super指向父类,用此句可以初始化父类成员__add__() __gt__():等,是操作符重载
3.2 库
prettytable
绘制 mysql 那样的表格
from prettytable import PrettyTable
table = PrettyTable(["ID", "指令", "热键"])
table.align["指令"] = "l" # 左对齐
table.add_row([123, xxx, c-t])
print(table)
pyperclip
复制到系统剪切板/粘贴
import pyperclip
a = "hello"
pyperclip.copy(a) # Ctrl-V => hello
# Ctrl-C sth ↓
a = pyperclip.paste()
print(a)
4 shell
引号
- 单引号
':保留字符串中所有字符的字面值,不对特殊字符进行任何解释(包括转义字符) - 单引号
":保留字符串中大部分字符的字面值,但会解释:$和反引号` - 反引号``:命令替换,执行反引号中的命令,返回执行的结果
- 引号嵌套:可以对不同引号执行嵌套,但相同引号只会顺序解释,编译器不会明白你的嵌套意图的
- 分号
;:用于在一行中分隔多个命令,写在不同行中就不需要分号了。if((...));then
括号
-
$(...):命令替换,执行括号里面的命令,返回执行结果 -
((...)):计算表达式,值为表达式的值。(原来使用中括号,不过已经是过时的语法) -
[ ... ]:等同于test命令,是个“运算符”,因此两边都要用空格隔开 -
{...,...,}:大括号拓展,可以生成多个字符串,如mkdir mydir_{1,2,3},会创建三个文件夹 -
${...}:变量替换,可以执行变量界定、赋默认值和模式匹配以及模式删除- 变量界定:告诉编辑器变量的边界,如
${myvar}ismyvalue - 赋默认值:如
${myvar:-dafault}$ - 模式匹配:使用正则表达式(里面可以正常使用正则的方括号大括号)(也可用通配符
*❓ )- 替换首个:
${varname/pattern/value},即一个/ - 替换全部:
${varname//pattern/value},用//,替换变量中所有满足pattern的
- 替换首个:
- 变量首删除:
- 删除最短匹配:
${varname#pattern},一个#,删除变量首部满足模式的最短匹配 - 删除最长匹配:
${varname##pattern},##,表示删除行首最长匹配
- 删除最短匹配:
- 变量尾删除:
- 删除最短匹配:
${varname%pattern},一个%,删除变量尾部满足模式的最短匹配 - 删除最长匹配:
${varname%%pattern},%%,表示删除行尾最长匹配
- 删除最短匹配:
- 例子:
- 删除变量行首的
/:${1#/} - 删除文件后缀:
${2%.*}
- 删除变量行首的
- 变量界定:告诉编辑器变量的边界,如
变量赋值
-
直接赋值:
myvar=myvalue,注意等号两边不能有空格 -
读取输入:
read myvar,有很多选项,参考 🔗read -
命令替换:命令替换可以用
$( ),也可以用反引号,二者都会执行里面的命令mydate=$(date) mydate2=`date` -
算数表达式:
myvar=$((2+3)):双括号用于计算表达式,if用的逻辑表达式也可以计算myvar2=$(expr 2+3):运算符+-*/%等有无空格都可以,赋值运算符不可以有空格let"myvar3 = 2+3":使用 let 时=两边也可以有空格
字符串
${#str}获取字符串长度,${#arry[@]}获取数组长度${str:m:n}:从第m个字符开始,截取n个字符的子串- 字符串拼接:
str="hello, "$name"!",直接用引号就可以拼接,但是不要使用空格隔开
还有一些用 expr 来执行的函数:
length:获取长度。len=$(expr length $str)。等价于len=${#str}substr:获取字串。sub=$(expr substr $str 2 4),从第二个字符开始的四个字符index:查找索引。pos=$(expr index $str ','),查找逗号首次出现的位置match:正则匹配。res=$(expr $str : '.*,\s\(\w*\)'),用圆括号进行捕获,括号要进行转义
数组
定义:arry=(var1 var2 "var3" ...):空格隔开,下标从 0 开始
使用:${arry[i]}
长度:len=${#arry[@]}
删除:unset arry[2],unset 之后,索引不会改变,但是数组长度会改变
添加:arry+=("x")
遍历:for i in ${arry[@]}。使用 @ 来split输出所有数组元素
**关联数组:**使用declare -A来声明
# 声明时即初始化
declare -A sites=(["google"]="www.google.com" ["baidu"]="www.baidu.com")
# 声明后赋值
sites["blog"]="shuaikai.cnblogs.com"
# 用键值访问
echo ${sites["google"]}
# 获取所有的 值
echo ${site[@]}
# 获取所有的 键
echo ${!site[@]}
函数
[ function ] funname [()] {
action
[return xxx;]
}
$#获取参数格式,$1 ...分别获取每个参数$*以一个字符串的形式输出所有参数。@和*对数组也适用$@获取所有参数,但是每一个都用单引号区分开。即*是一个结果,@是多个($#)结果$?获取函数的返回值(退出状态)
分支&循环
# 条件是不需要括号的,或者说,不指定圆括号。if (( )) 实际上是用的圆括号执行表达式的性质
if condition1
then
command1
elif condition2
then
command2
else
commandN
fi
# 列表可以直接列举,也可以是通配符,也可以是命令执行结果
for var in item1 item2 ... itemN
do
command
done
# 或者
for (( ; ; ))
for file in `ls`
for dir in /codes/*
while condition
do
command
done
case var in
x)
command1
;;
y)
command1
;;
esac
break跳出循环;continue跳出本次循环
测试
| 数值测试 | |||
|---|---|---|---|
| -eq | equal = | -ne | not equal ≠ |
| -gt | greater than > | -lt | less than < |
| -ge | greater equal ≥ | -le | less equal ≤ |
| 字符串测试 | |||
|---|---|---|---|
| = | 字符串相等 | != | 字符串不同 |
| -z | 字符串长度为 0(则为真) | -n | 字符串不为空 |
| 文件测试 | |||
|---|---|---|---|
| -e | 文件存在(下同) | -r | 文件可读 |
| -w | 文件可写 | -x | 文件可执行 |
| -s | 文件不为空 | -d | 文件是目录 |
| -f | 文件是普通文件 | -c | 文件是字符型特殊文件 |
| -b | 文件是块文件 |
特殊变量
date获取当前日期(是个命令):echo $(date +%Y-%m-%d):年月日格式输出当前日期RANDOM生成随机数PS1命令提示符SECONDS当前脚本执行的秒数UID PID PWD HOME HOSTNAME...
4 HTML
markdown
表格的使用
并排插入图片,需要用到表格才能实现。插入图片不需要用到<a herf></a>,不然点一下就跳转也有些烦人。html标签不写在代码块内即生效。
图片大小可以用<td style="width:50%"></td>来调整,各占50%就好了
<table style="border:none;text-align:center;">
<tr>
<td style="width:50%"><img src="" alt="" border="0" /></td>
<td style="width:50%"><img src="" alt="" border="0" /></td>
</tr>
<!--可以排图,也可以图文混排,也可以用来添加注释-->
<tr>
<td style="width:50%"><strong>图1 </strong></td>
<td style="width:50%"><strong>图2 </strong></td>
</tr>
</table>
音视频
<audio controls>
<source src="https://www.runoob.com/try/demo_source/horse.mp3" >
您的浏览器不支持 audio 元素。
</audio>
<video width="320" height="240" controls>
<source src="https://www.runoob.com/try/demo_source/movie.mp4" type="video/mp4">
您的浏览器不支持 HTML5 video 标签。
</video>
例子:创建一个只用来分享视频的页面
<!doctype html>
<html>
<head>
<meta charset='UTF-8'><meta name='viewport' content='width=device-width initial-scale=1'>
<title>演示</title>
</head>
<body>
<center>
<video controls align="center" width="1350">
<source src="https://shuaikai-bucket0001.oss-cn-shanghai.aliyuncs.com/videos/Bookxnotes%E6%BC%94%E7%A4%BA2.mp4" type="video/webm">
</video>
</center>
<p> </p>
</body>
</html>

















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









