






基于深度学习的数据竞争检测方法
chap0 Introduction
数据竞争是指2个或多个线程同时访问1个 内存位置并且至少有1个线程执行写操作.
DeleRace(deep-learning-based data race detection):首先使用工具 WALA 从多个实际应用程序中中提取指令、方法和文件级别中多个代码特征,对其向量化 并构造训练样本数据;;然后通过ConRacer 工具对真实数据竞争进行判定进而标记样本数据,并采用SMOTE 增强算法使正负数据样本分布均衡化;最后** 构建 CNN-LSTM 的深度神经网络 **,加以训练构建分类器,进而实现对数据竞争的检测。
本文贡献:
1)构建数据集用了26个不同领域的实际应用程序
2)提出一种适合数据竞争检测的深度学习模 型DeleRace
3)验证了DeleRace 的有效性.
原文及笔记下载
chap1 DeleRace
1.1 检测框架
DeleRace方法框架各功能标注如图所示
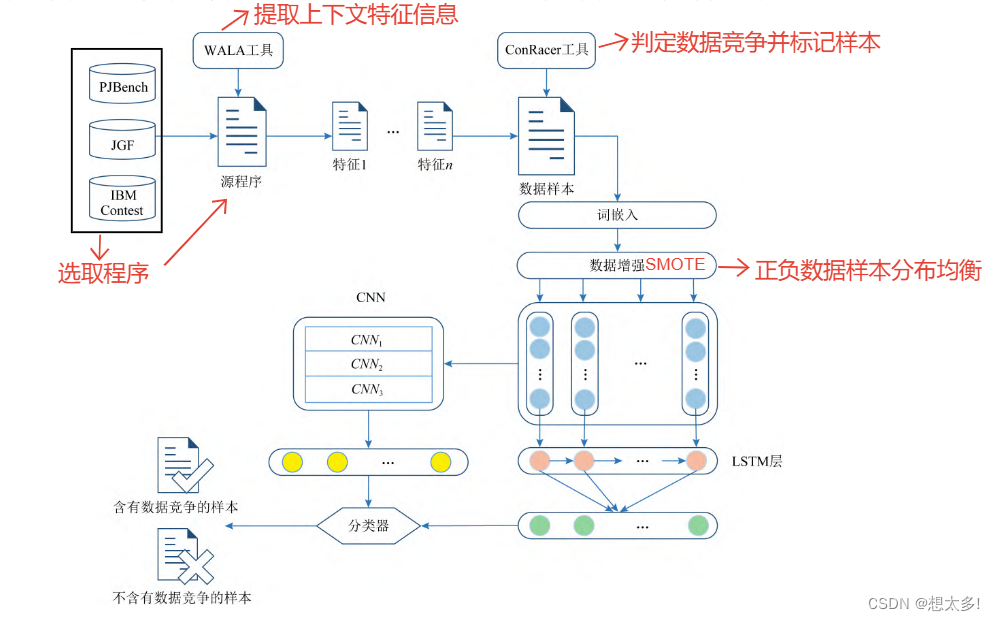
1.2 选取实际应用程序
从 DaCapo[20] ,JGF[21] ,IBM Contest[22] ,PJBench[23] 四 个基准测试程序套件中选取26个含有数据竞争的并发程序
1.3 特征提取
1.3.1 WALA 特征提取操作步骤


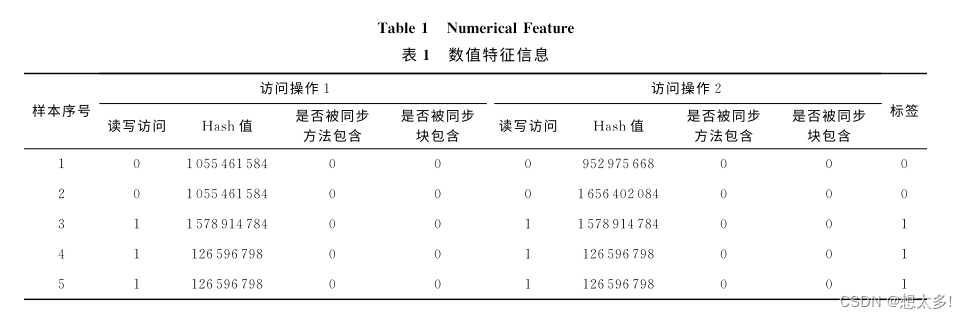
1.3.2 数值特征(指令级别)
每个访问操作包含4条指令级别的特征.
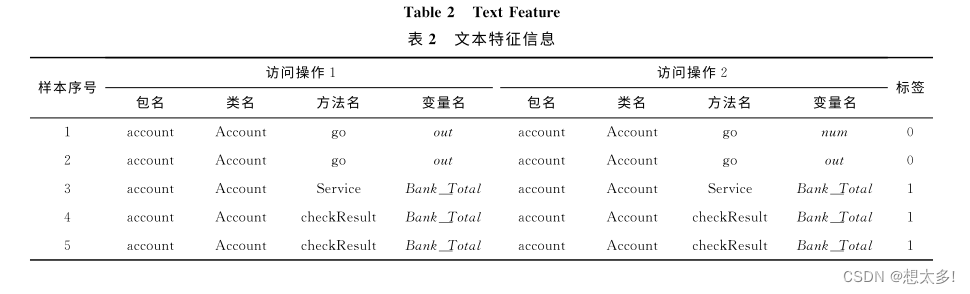
1.3.3 文本特征(方法级别)
每个访问操作均包含包名、类名、方法名、变量名等文本特征,其中包名和类名为文件级别的特征,方法名和变量名 为方法级别的特征.
1.4 文本特征向量化
使用 Keras 的嵌入层进行文本特征向量化
1)首先将单词表中的单词进行词 频统计并进行整数编码;
2)然后将每个单词的编码M经过嵌入层处 理后映射为一个8维向量;
3)对嵌入层进行训练并更新权重;
4)最后得到一个真正可以代表每个单词的数值向量
1.5 数据均衡分布——过采样
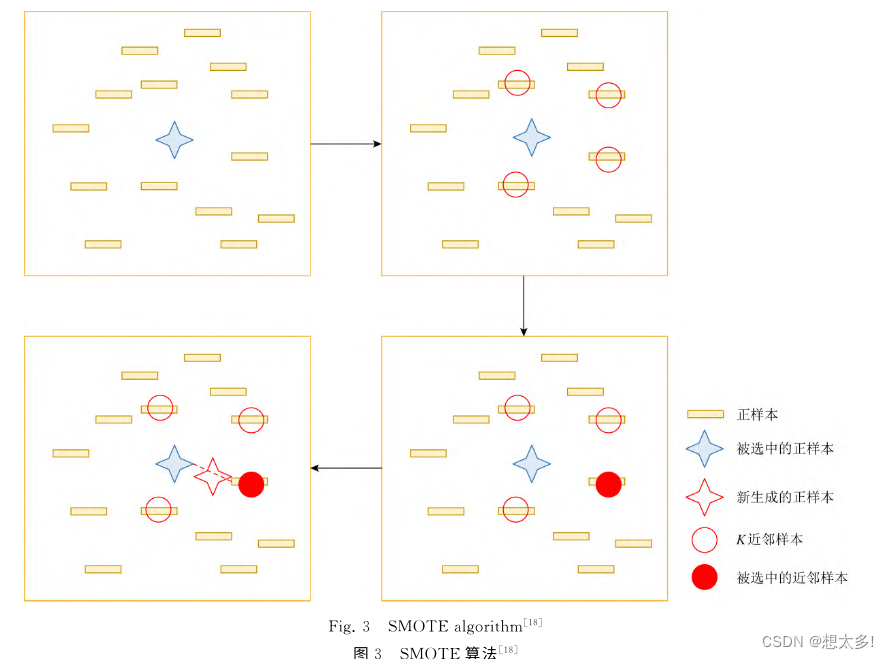
SMOTE:其基本思想是对少数类样本进行分析,并根据 少数类样本合成新样本,然后添加到数据集中。
- 这里先选定一个正样本,找出这个正样本
的K近邻(假设K=4),随机从K个近邻中选择一
个样本,在正样本和被选出的近邻样本的连线上随
机找一个点,这个点就是我们生成的新的正样本,一
直重复这个过程,直到正样本和负样本数量均衡.通
过SMOTE算法,将原有的12 836条训练样本扩充
到25 438条,从而使正样本和负样本的数据样本数
量达到了均衡.
如 图3所示
1.6 CNN—LSTM 神经网络
训练网络时,首先将每对访问操作的特征信息 输入到CNN-LSTM 神经网络中;,每个卷积层后都有一个最大池化 层来降低特征维数,避免过拟合.函数Concatenate 把CNN输出的卷积特征和LSTM 提取的时序 特征融合到另一个全连接层进行二分类,并通过 Dropout方法来防止过拟合,最终输出测试程序中 含有数据竞争的个数.
chap2 实验结果与分析
2.3 RQ(research question)
通过回答6个研究问题对 DeleRace 方 法进行评估

2.6 DeleRace检测结果
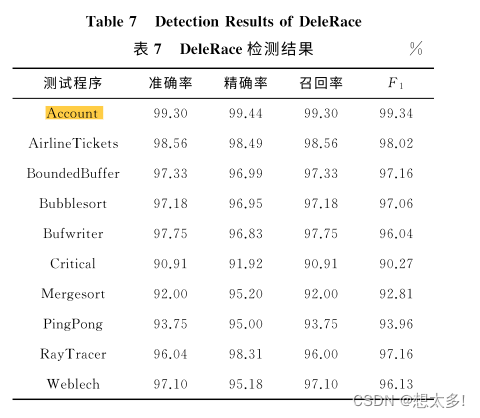
RQ2:DeleRace 是否能准确有效地检测出数据竞争?(表7)
2.7 与其他深度神经网络方法对比
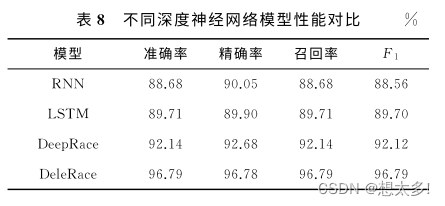
RQ3:DeleRace是否优于现有的基于深度学习 的数据竞争检测工具,与其他的深度神经网络相比, DeleRace的表现会如何(表8)














 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









