







文章目录
1. InputFormat阶段流程
InputFormat阶段是MapReduce的一个阶段。
其详细流程见:MapReduce详细流程
2. InputFormat与其子类关系图
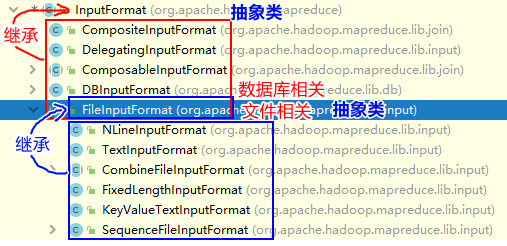
接下来主要介绍以下两个类的切片机制和读取机制:TextInputFormat类 和 CombineFileInputFormat
3. TextInputFormat(默认)
假如集群中有n台主机,有一个 job 在 map 阶段需要 k 个 MapTask进行处理,那么会调用 k 台主机进行处理。
所以,MapTask 的并行度决定 Map 阶段的任务处理并发度,进而影响到整个 Job 的处理速度。
那么问题来了?怎么判断一个job应该分成几个MapTask???
先理解两个概念:
- 数据块:Block 是 HDFS 物理上把数据分成一块一块,它是 HDFS 存储数据的单元。
- 数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。一个切片会对应启动一个 MapTask
3.1 切片机制
-
默认逐个对job提交的每个数据文件按照splitSize大小切片。默认splitSize的值就是块大小,其计算公式为:。

比如:

注意:如果文件小于块大小,那么会表现为按文件切片。
-
每次切片时,都要判断切完剩下的部分是否大于块的
1.1倍,不大于1.1倍就划分一块切片。【主要用于判断最后剩余的部分切还是不切】
3.2 读取机制
对于每个MapTask一行一行的读取。
- key:离文件开始处的偏移量。
- value:为该行的内容。
3.3 如何设置?
默认使用TextInputFormat切片机制,故不需要设置。
- job如何输入多个文件:
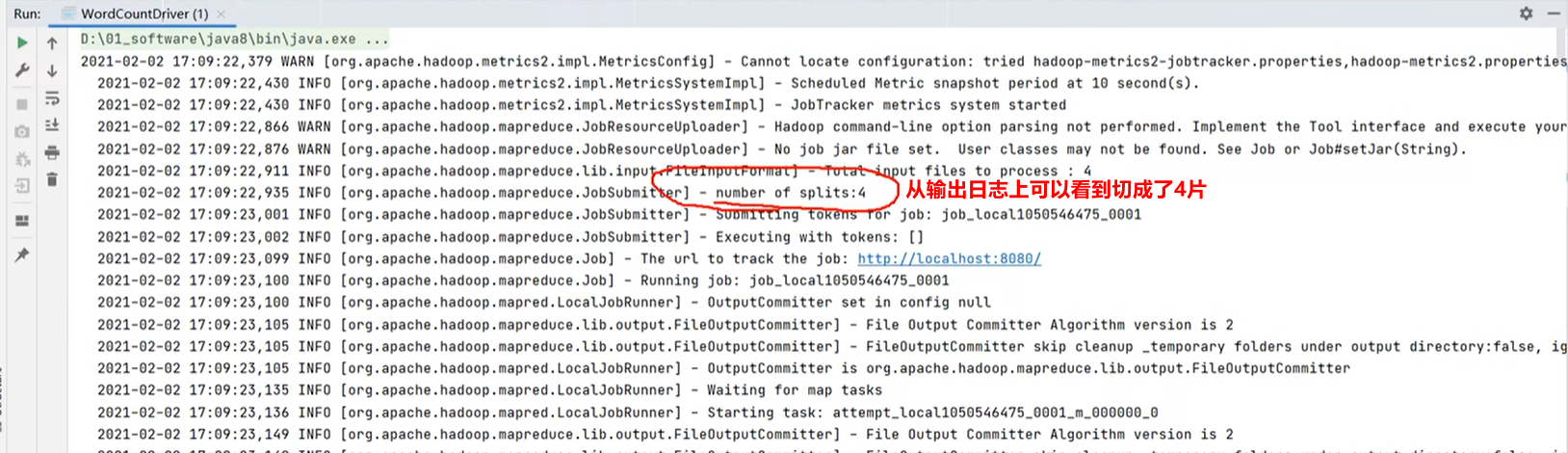
- 如何查看切了几片:

4. CombineFileInputFormat
CombineFileInputFormat用于小文件多的场景。
4.1 切片机制
- 先将文件按字典顺序由小到大排序
- 对每个文件按maxInputSplitSize(默认等于4)进行分割成更多更小的文件
- 然后将小文件结合起来做为一个片

4.2 读取机制
和TextInputFormat一样。
4.3 如何设置?
如何使用CombineTextInputFormat进行切片?如何设置maxInputSplitSize大小?

















 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











