







1. 什么是Hive?
- hive是建立在Hadoop上的一个一个数据仓库。
- 它可以将存储在Hadoop的结构化、半结构化数据映射为一张张数据库表。
- 它提供了一种类似SQL的查询语言HQL,通过HQL可以查询Hadoop中的数据。
- hive包含了SQL解析引擎,它会将HQL转换为MapReduce Job,然后在Hadoop中执行。
2. Hive优缺点
-
优点:
- 采用类SQL语法,避免了去写复杂的MR,提高开发效率
- Hive支持用户自定义函数
- 背靠hadoop适合处理大数据。
-
缺点:
- Hive的执行延迟比较高,所以不适合处理小文件,不适合对实时性要求高的场景
- Hive调优比较困难,更多的还是需要通过调整Hadoop参数进行调优。
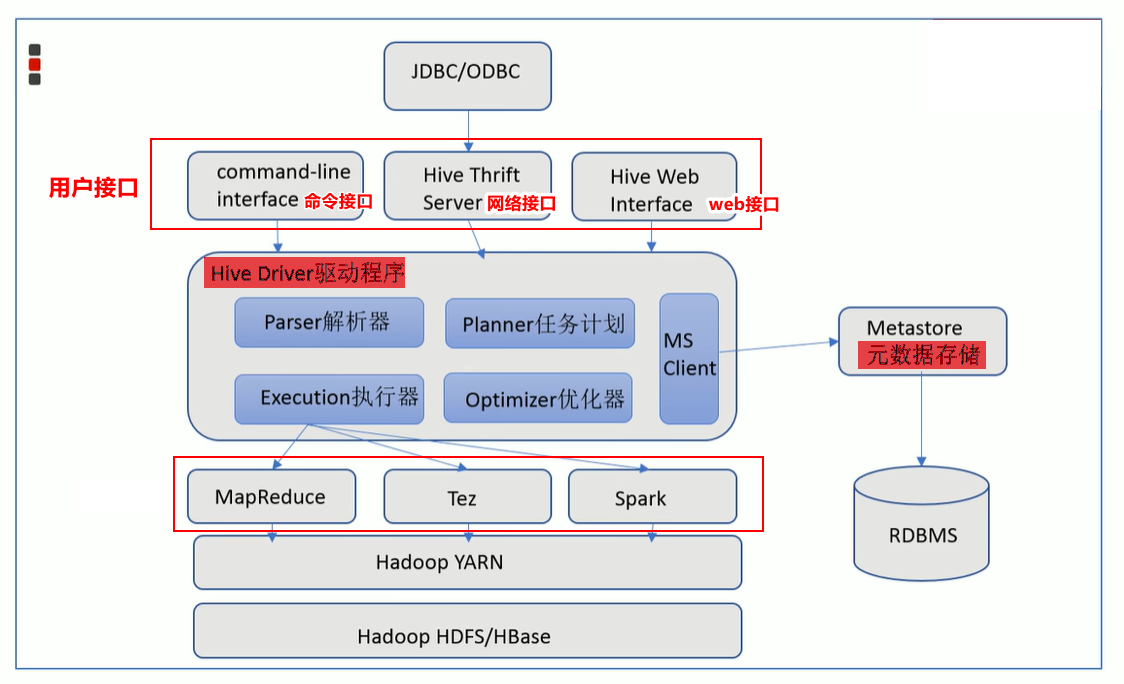
3. Hive架构
hive有3大组件:
- 用户接口:用户输入HQL的地方。提供的接口有三种:命令接口、网络接口(比如jdbc等)、web图形化接口
- 元数据存储(metastore):真正的数据是存储在hadoop的hdfs中的,元数据存储在关系型数据库中。(可以使用hive内置的轻量级Derby关系型数据库,也可以使用第三方的MySQL数据库)。
- 元数据:是描述数据的数据。比如表的名字,表的字段等等。
- Derby数据库只支持单会话,当启动两个及以上的hive客户端时,就会报错。所以开发中通常使用Mysql存储元数据
- 驱动程序:对HQL的解析、优化优化以及查询计划的生成。生成的查询计划存储在 hdfs中,随后由计算引擎执行。
hive不直接处理数据,而是通过计算引擎处理。hive支持的计算引擎有4种:Hadoop的MapReduce、Tez、Spark、Fink 。
- 【MR是hive的默认执行引擎】
- 【Tez源于MR,核心是将Map和Reduce两个阶段做进一步的拆分,然后对元数据灵活组合,提高效率】
- 【spark:采用内存计算。MR和Tez的Shffle阶段会将中间计算结果写入磁盘,而spark将数据从hdfs中读取后一直在内存,中间计算结果是不会被写进磁盘的,一直到最终结果才会写入磁盘。这样大幅度的提高了效率】
- 【Fink:也是次啊用内存计算,但是用于实时计算的场景】
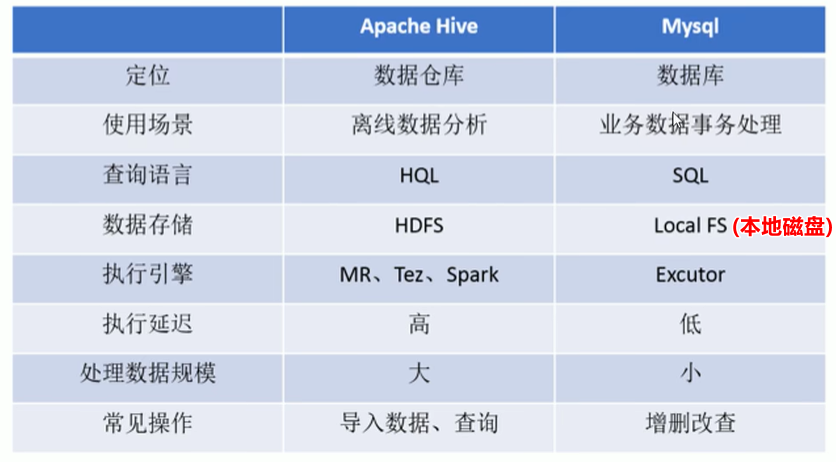
4. Hive vs MySQL
hive不是大型数据库,也不是要取代数据库。虽然两者很像,但其本质不同:
- hive是数据仓库,面向分析的(OLAP)。侧重于查询历史数据进行分析。
- mysql 是数据库,面向业务的(OLTP)。侧重于CRUD、关心数据的响应时间、安全性、完整性等,保证高效的完成业务问题

















 5445
5445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











