







- Hive中函数有4类:单行函数、聚合函数、炸裂函数、窗口函数。
1. 概述
在使用前面学过的 单行函数、聚合函数、炸裂函数时,都是对 全局数据 进行处理,并不能对 部分数据 处理。比如:
-- 情况1:若没有分组,则对所有行进行处理,并不能只对部分行,比如前3行进行处理
select count(*) from tab1;
-- 情况2:若分组了,则每组都会该组内的所有数据进行处理,并不能只对组内部分数据进行处理
selecct count(*) from tab2 group by sex;
而窗口函数能够做到只对 部分数据 进行处理,这也是“窗口”二字的含义。
窗口函数可以实现:
- 分组聚合【思考:与
group by+select后面使用聚合函数实现的分组聚合有何区别别?】 - 分组排序【思考:与
group by+order by实现的分组排序有何区别别?】
1.1 窗口函数的partition by与group by 的分组有什么区别?
表现为3点:
-
窗口函数保留原本数据,会将分组聚合后的结果拼接在原数据上,最终返回的行数与原始据行数相同。而 group by 只能得到分组处理后的数据,最终有几组就返回几行数据。
① 比如有数据:
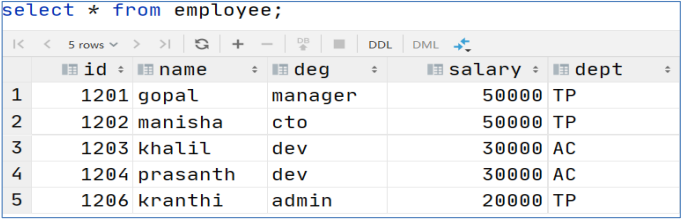
② 使用 group by 进行分组求和
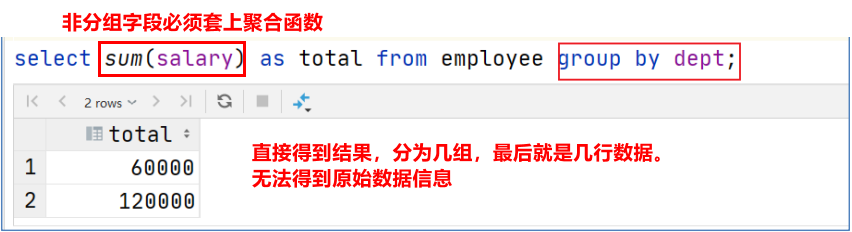
③ 使用sum() 窗口函数进行分组求和
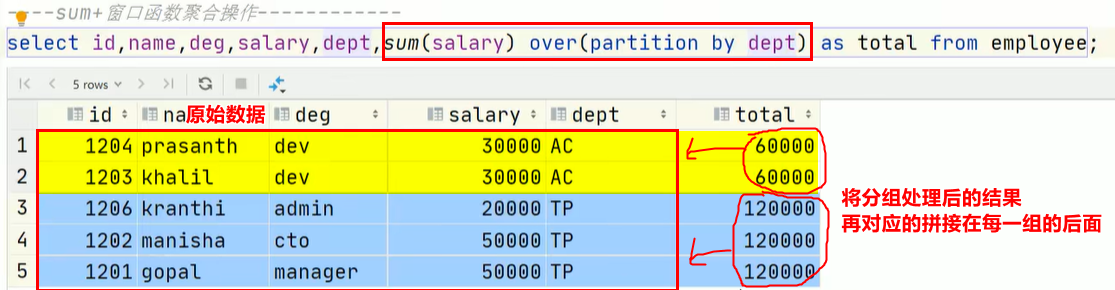
-
使用
group by分组后,select后待查询字段如果是非分组字段,则必须套上聚合函数;而窗口函数没有这个限制 -
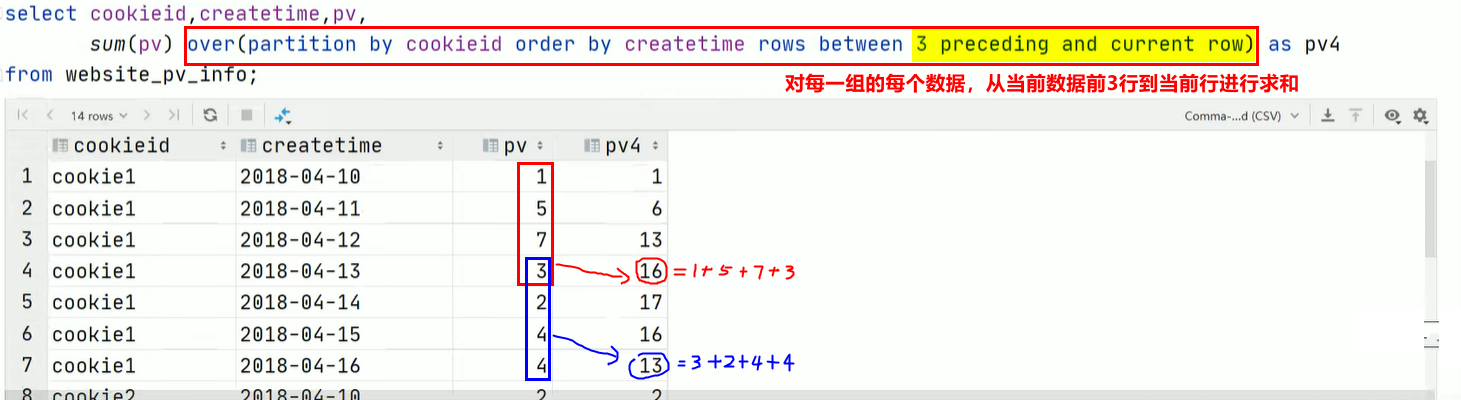
窗口函数能够限制对每一组的部分数据进行处理,而 group by 只能对每一组的所有数据进行处理。
比如窗口函数:
这三个区别往往能够帮助我们判断在写代码时使用group by还是窗口函数。
1.2 窗口函数采用排序会改变原数据的顺序吗?
窗口函数会改变原数据的顺序,比如:

1.3 窗口函数的order by + order by 的排序有区别吗?
- order by:是全局排序
- 窗口函数的order by:是组内排序
2. 语法
2.1 哪些函数可以开窗变为窗口函数?
- 聚合函数:sum、count、max、min、avg
- 排名函数:rank、dense_rank、row_number、ntile
- 分析函数:lead、lag、first_value、last_value
2.2 语法
语法非常简单,就是在上述函数的后面加上over()函数:
func(arg1,..., argn) over ([partition by 分组字段] [order by 排序字段] [rows between 窗口表达式1 and 窗口表达式2])
-- 其中partition by关键字用于指定分组字段。如果没有PARTITION BY 那么整张表的所有行就是一组
-- 其中order by关键字用于指定排序字段以及每组的排序规则
-- 其中rows between关键字指定对每组中的进行数据处理的行范围.默认是选中每组中的所有行
-- 窗口表达式有:
- x preceding:往前x行
- x following:往后x行
- current row:当前行
- unbounded preceding: 首行
- unbounded following:尾行
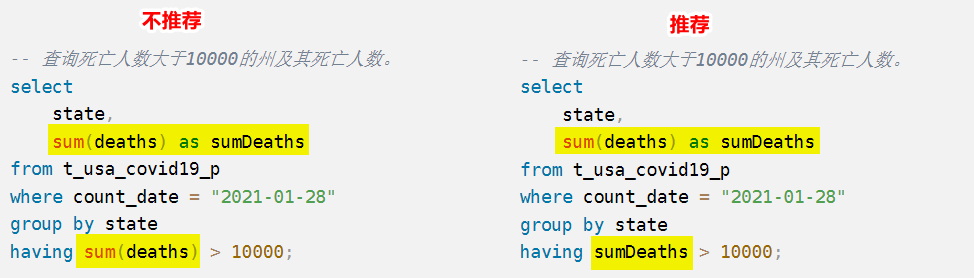
- 关于 order by 后面接聚合函数:
- 对于窗口函数的 order by + 聚合函数:
- 一般情况下,over()函数内的
partition by和order by后面都是字段名- 然而
order by后面可以是聚合函数。但是一旦后面是聚合函数,返回的行就与原来的行不匹配,所以必须用group by代替partition by。
反过来说,也就是 group by 之后的 聚合函数 可以写在窗口函数中
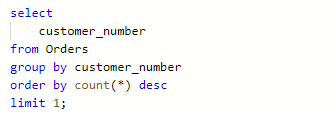
-- 正确 select *, row_number() over(order by count(*) desc) as rn from Orders group by customer_number;- 此处聚合函数的本质:是一个临时字段,避免了取别名。通过这个例子可以理解【586. 订单最多的客户】
- 对于select中的order by + 聚合函数:其本质也是临时字段,避免了取别名。类似于这样
例子:586. 订单最多的客户

注意:
- 窗口函数是一行一行执行的
- 窗口函数在哪sql语句的哪一部执行??? 将其当做聚合函数,因此,在
group by关键字之后执行- 关于窗口范围:
- 并不是所有函数都需要写窗口范围,只有 窗口聚合函数 可以,窗口排名函数 和 窗口分析函数 不支持写窗口范围:
rank、dense_rank、row_number、ntile、lead、lag、first_value、last_value- 对于 窗口聚合函数:
- 当有
order by但是缺少窗口范围时(即rows between 窗口表达式1 and 窗口表达式2),范围是上无边界到当前行- 当
order by和窗口范围都缺少时,范围是上无边界到下无边界。
关于窗口边界的例子:
--第一行到当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from website_pv_info;
--向前3行至当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
from website_pv_info;
--向前3行 向后1行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
from website_pv_info;
--当前行至最后一行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from website_pv_info;
--第一行到最后一行 也就是分组内的所有行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and unbounded following) as pv6
from website_pv_info;
---- 关于order by 的一个坑
如果order by排序的数据有重复的,hive会将这两行数据认为是同一行数据。
例如:有以下数据
1
2
3 // 同时存在两条数据为3
3 // 同时存在两条数据为3
4
5
此时使用 SQL 查询:
select
id,
sum(id) over(order by id)
from test
结果为:
1 1
2 3
3 9 // 两条id=3的数据的sum值都是9
3 9 // 两条id=3的数据的sum值都是9
4 13
5 18
---- 关于窗口函数是否可以嵌套
-
可以嵌套,但只能有一个函数被开窗
-- 1. 对最外层的函数开窗 select sum(count(*)) over(...) as ... -- 这是对sum()开窗 select if(count(*)) over(...) as ... -- 错误,if()不能被开窗 -- 2. 在内层开窗 date_add(col, row_number() over(...)) as ... -- 这是对内层的 row_number() 开窗 -
如果有多个函数被开窗,则不可以嵌套
-- 不可以嵌套开窗 select sum(count(*) over(...)) over(...) ...
---- 关于case end 中是否可以用窗口函数
- 答:可以。窗口函数是新构造的一列,把它当做表的一个列就行。case…end语法是基于表的列又重新构造新的列。
- 例子:
-
现在有如下表:
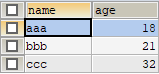
-
用窗口函数打上标签:
WITH DATA AS ( SELECT 'aaa' AS NAME, 90 AS money UNION ALL SELECT 'aaa' AS NAME, 30 AS money UNION ALL SELECT 'bbb' AS NAME, 21 AS money UNION ALL SELECT 'bbb' AS NAME, 10 AS money ) SELECT SUM(money) over(PARTITION BY NAME) AS col FROM DATA结果:

-
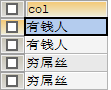
用case…end语法处理标签列
WITH DATA AS ( SELECT 'aaa' AS NAME, 90 AS money UNION ALL SELECT 'aaa' AS NAME, 30 AS money UNION ALL SELECT 'bbb' AS NAME, 21 AS money UNION ALL SELECT 'bbb' AS NAME, 10 AS money ) SELECT CASE WHEN SUM(money) over(PARTITION BY NAME) > 100 THEN '有钱人' WHEN SUM(money) over(PARTITION BY NAME) <= 100 THEN '穷屌丝' ELSE NULL END AS col FROM DATA结果:
-
---- 关于窗口函数后面是否可以用distinct
目前是不支持的。比如count(distinct cuid) over(partition by appid)
2.3 窗口函数执行顺序
3. 窗口聚合函数
sum、count、max、min、avg 后面加上over()函数变为窗口函数。
其中对于sum()窗口函数有个注意点,所以以sum()函数来举例子。
3.1 sum()窗口函数的一个注意点
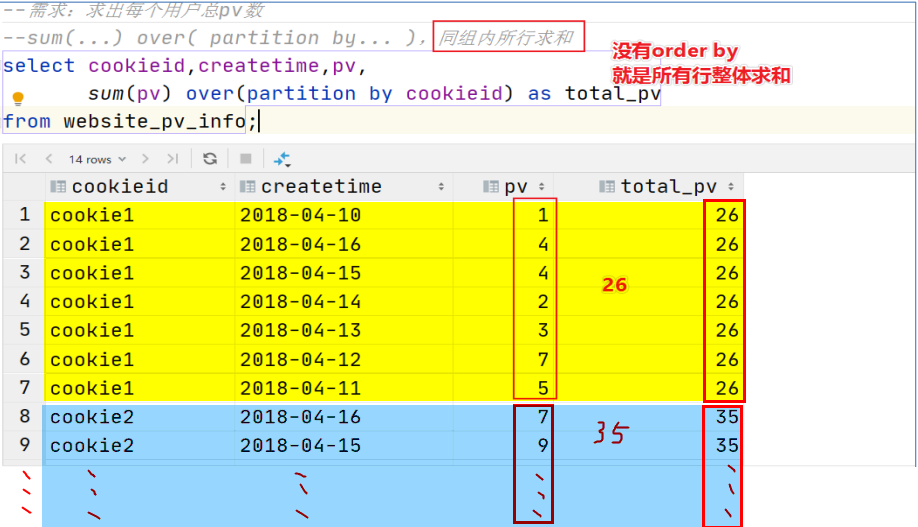
sum(...) over( ) --对表所有行求和
sum(...) over(partition by... ) --同组内所行求和
sum(...) over(order by ... ) -- 连续累积求和
sum(...) over(partition by... order by ... ) -- 在每个分组内,连续累积求和
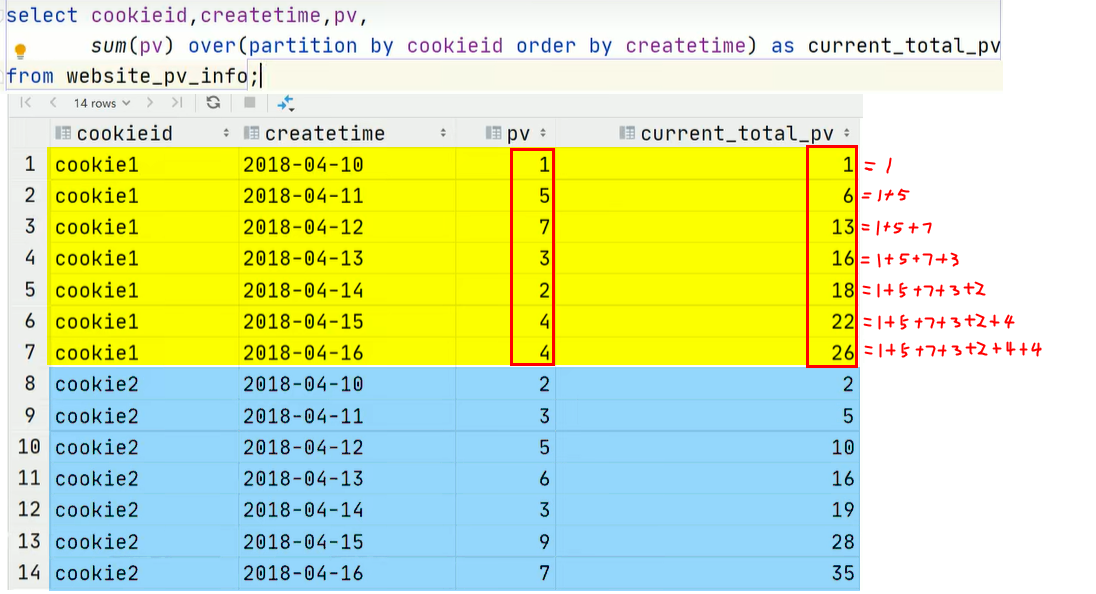
如果sum()窗口函数使用了order by 关键字:
-
不仅会对每组内的数据排序
-
而且,此时对于每个组并不是对组内所有行直接求和,而是对组内行进行累加求和(具体为:对于每一组的每一行都是从该组第一行到当前行的累加)。
【利用这个特性可以解决带有累加 / 累计字样的题目】比如:
3.2 一个案例
-
假设有
website_pv_info.txt和website_url_info.txt两份文件:-- website_pv_info.txt cookie1,2018-04-10,1 cookie1,2018-04-11,5 cookie1,2018-04-12,7 cookie1,2018-04-13,3 cookie1,2018-04-14,2 cookie1,2018-04-15,4 cookie1,2018-04-16,4 cookie2,2018-04-10,2 cookie2,2018-04-11,3 cookie2,2018-04-12,5 cookie2,2018-04-13,6 cookie2,2018-04-14,3 cookie2,2018-04-15,9 cookie2,2018-04-16,7 -- website_url_info.txt cookie1,2018-04-10 10:00:02,url2 cookie1,2018-04-10 10:00:00,url1 cookie1,2018-04-10 10:03:04,1url3 cookie1,2018-04-10 10:50:05,url6 cookie1,2018-04-10 11:00:00,url7 cookie1,2018-04-10 10:10:00,url4 cookie1,2018-04-10 10:50:01,url5 cookie2,2018-04-10 10:00:02,url22 cookie2,2018-04-10 10:00:00,url11 cookie2,2018-04-10 10:03:04,1url33 cookie2,2018-04-10 10:50:05,url66 cookie2,2018-04-10 11:00:00,url77 cookie2,2018-04-10 10:10:00,url44 cookie2,2018-04-10 10:50:01,url55 -
建表加载数据
create table website_pv_info( cookieid string, createtime string, -- 访问时间 pv int -- 访问次数 ) row format delimited fields terminated by ','; create table website_url_info ( cookieid string, createtime string, --访问时间 url string --访问页面 ) row format delimited fields terminated by ','; load data local inpath '/root/hivedata/website_pv_info.txt' into table website_pv_info; load data local inpath '/root/hivedata/website_url_info.txt' into table website_url_info; select * from website_pv_info; select * from website_url_info; -
实现需求:
--需求:求出网站总的pv数 所有用户所有访问加起来 --sum(...) over( )对表所有行求和 select cookieid, createtime, pv, sum(pv) over() as total_pv from website_pv_info; --需求:求出每个用户总pv数 --sum(...) over( partition by... ),同组内所行求和 select cookieid, createtime, pv, sum(pv) over(partition by cookieid) as total_pv from website_pv_info; --需求:求出每个用户截止到当天,累积的总pv数 --sum(...) over( partition by... order by ... ),在每个分组内,连续累积求和 select cookieid, createtime, pv, sum(pv) over(partition by cookieid order by createtime) as current_total_pv from website_pv_info;
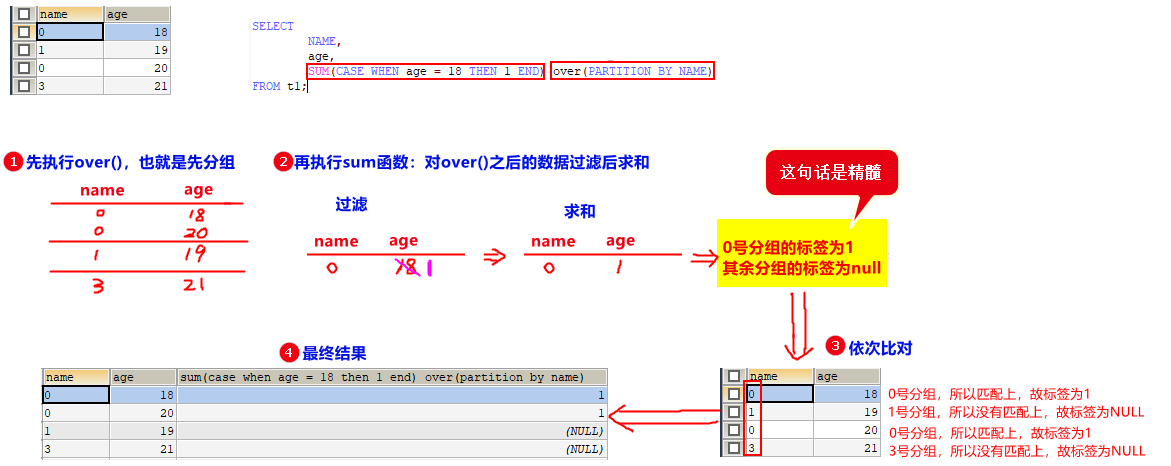
3.3 聚合函数会导致行数变少,是如何处理的?
就是聚合后的行,依次去与原数据匹配,匹配的上就拼接聚合都的数据,匹配不上就拼接NULL。
例子:
4. 窗口排名函数
4.1 rank、dense_rank、row_number
求TopN的窗口函数指的是 rank()、dense_rank()、row_number()这三个函数后面加上over()函数变为窗口函数。
-
作用:用于解决求TopN的需求。【比如:统计查询每个部门薪资最高的前两名员工的薪水】
-
这三个函数的区别:
rank() 在每个分组中,为每行分配一个从1开始的递增序号 考虑重复 挤占后续位置,导致后不连续 dense_rank() 在每个分组中,为每行分配一个从1开始的递增序号 考虑重复 不挤占后续位置 row_number() 在每个分组中,为每行分配一个从1开始的递增序号 不考虑重复 --------------------- -
例子:
SELECT cookieid, createtime, pv, rank() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1, dense_rank() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2, row_number() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3 FROM website_pv_info WHERE cookieid = 'cookie1'; -- 只显示cookie1这个分组的数据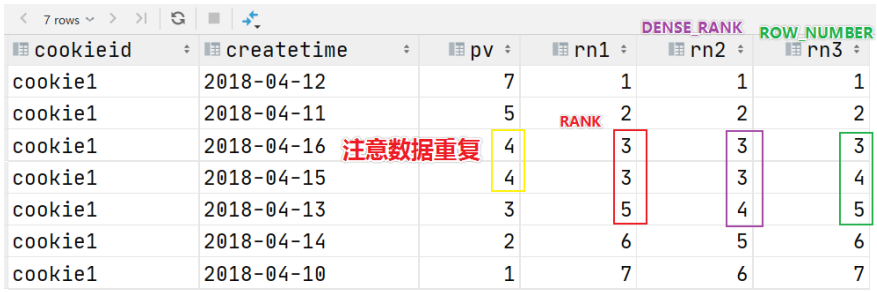
4.2 ntile
求几分之几的窗口函数指的是 ntile()这个函数后面加上over()函数变为窗口函数。
-
作用:解决类似得到报表前1/3数据这种需求
-
ntile()函数:将每个分组内的数据平分为指定的若干个桶里,并且为每一个桶的编号相同,桶编号从1开始。
比如:--把每个分组内的数据分为3桶 select cookieid, createtime, pv, ntile(3) over(partition by cookieid order by createtime) as rn2 from website_pv_info order by cookieid,createtime;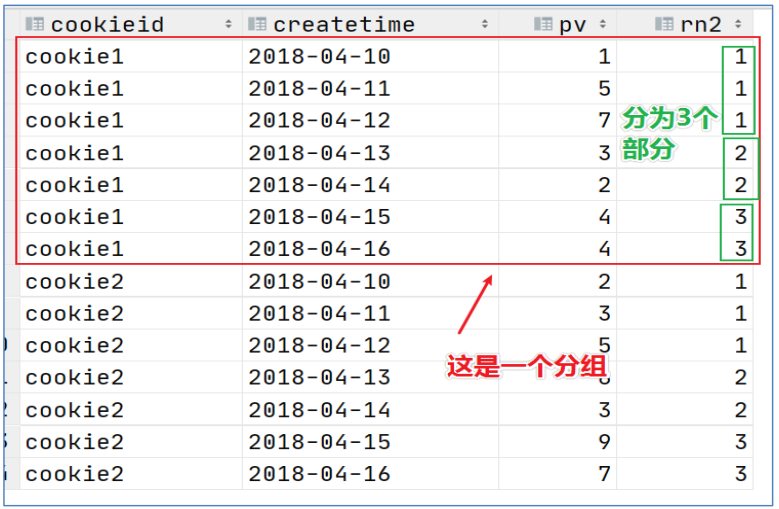
-
例子:
--需求:统计每个用户pv数最多的前3分之1天。 --理解:将数据根据cookieid分 根据pv倒序排序 排序之后分为3个部分 取第一部分 SELECT * from (SELECT cookieid, createtime, pv, NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn FROM website_pv_info ) tmp where rn =1;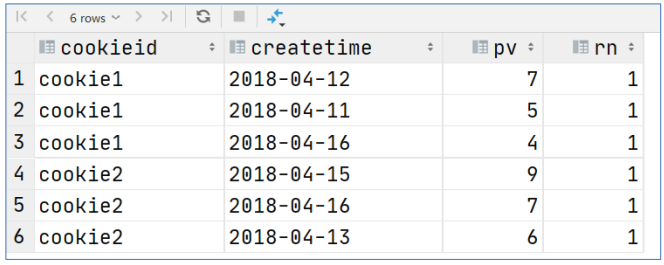
5. 窗口分析函数
同样是在函数后面加上over()函数。具体有以下4个:
-
lag(col, n, default):对于每一组,返回col这一列的值整体向下平移n个单位。空缺的用default值填充,如果没有传入default值,则用null填充。SELECT cookieid, createtime, url, ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn, LAG(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS last_1_time, LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS last_2_time FROM website_url_info;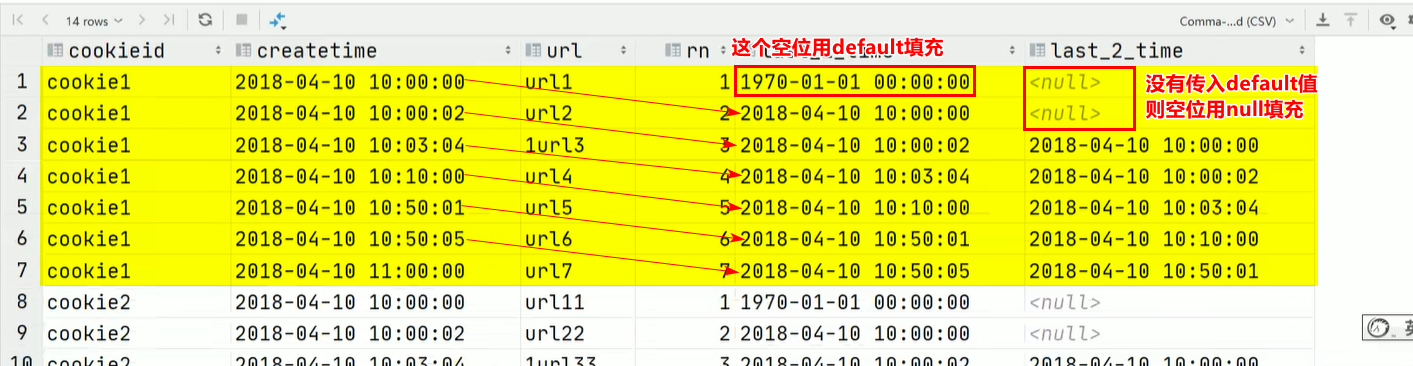
-
lead(col, n, default):对于每一组,返回col这一列的值整体向下平移n个单位。【可以解决连续登入问题】 -
first_value(col):对于每一组,返回col这一列的第一个值SELECT cookieid, createtime, url, ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn, FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1 FROM website_url_info;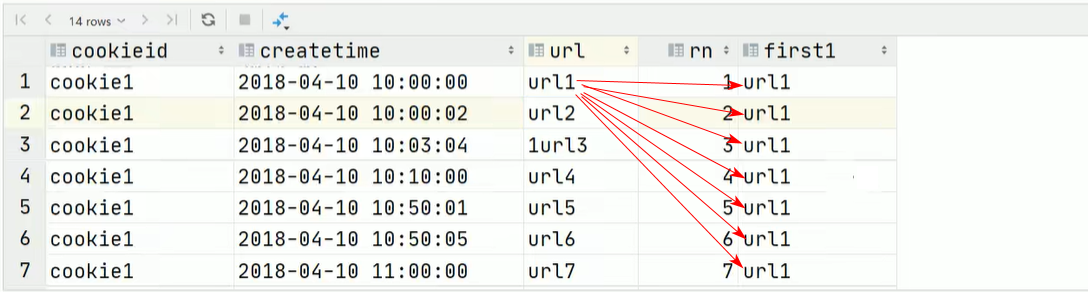
例子:
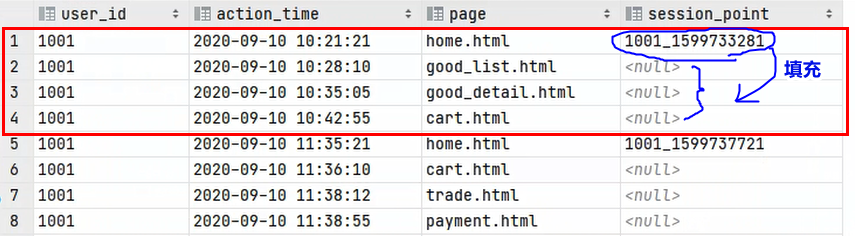
-
last_value(col):对于每一组,返回col这一列的最后一个值
6. 关于窗口函数的一些思考
6.1 窗口函数别名
-
使用窗口函数生成的列可以看做是为原表的行打上标签
-
虽然列别名在优化之后能在
group by及之后使用:

但是,如果是窗口函数所的列别名,则不行,严格遵守语法顺序。这就导致,如果开窗之后,对开窗函数的列别名进行过滤,则有两种方式:
-- 错误: select col1, col2, row_number() over(...) as ranking from ... where ranking <= 3; -- 改正思路一:在外面再嵌套一个查询,然后将 where移到外面的查询中 select ... from ( select col1, col2, row_number() over(...) as ranking from ... ) t where ranking <= 3; -- 改正思路二:将窗口函数写到相对于where的子查询中 select col1, col2 from ( select row_number() over(...) as ranking from ... ) where ranking <= 3;
















 3417
3417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











