







以WordCount为例,进行演示
第一步:创建项目
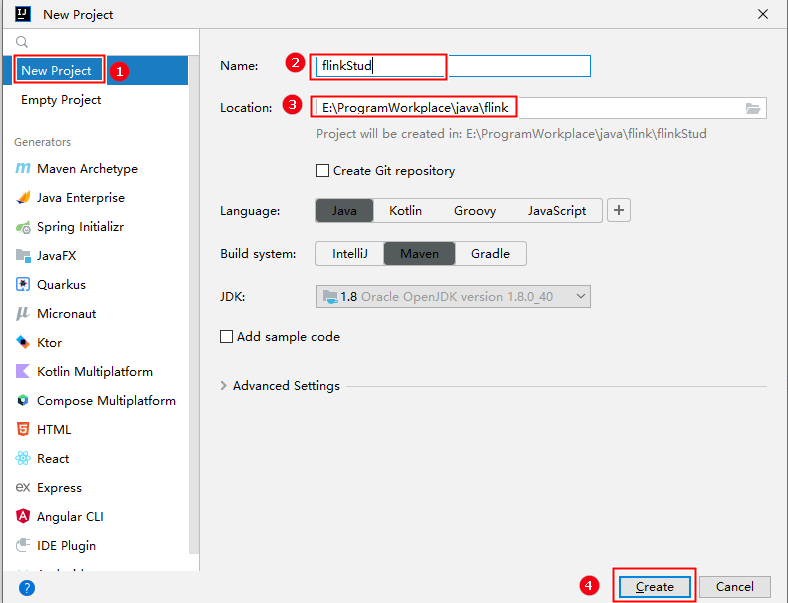
第二步:编辑pom.xml文件
-
pom.xml里面有
<properties></properties>标签对,在里面添加内容:
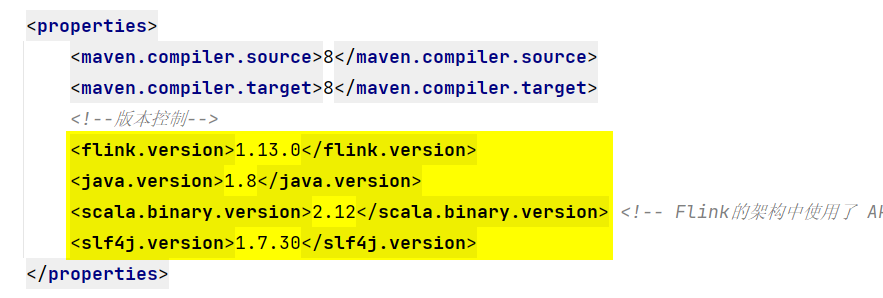
-
pom.xml一般没有
<dependencies></dependencies>标签对,需要手动添加。 -
最终pom.xml文件为:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>flinkStudy</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <!--版本控制--> <flink.version>1.13.0</flink.version> <java.version>1.8</java.version> <scala.binary.version>2.12</scala.binary.version> <!-- Flink的架构中使用了 Akka 来实现底层的分布式通信,而 Akka 是用 Scala 开发的--> <slf4j.version>1.7.30</slf4j.version> </properties> <dependencies> <!-- Flink核心组件 --> <dependency> <!--表示使用java代码编写的Flink程序--> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <!--流处理和批处理的API,即Flink四大API之一的DataStream/DataSet API--> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <!-- provided表示在打包时不将该依赖打包进去,可选的值还有compile、runtime、system、test --> <scope>provided</scope> </dependency> <!--可以直接在IDEA中执行Flink程序--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <!--webUI界面,类似于Hadoop的hdfs、yarn网页显示--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime-web_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <!--日志相关的依赖--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.14.0</version> <scope>provided</scope> </dependency> </dependencies> </project> -
如果pom.xml文件中有
<scope></scope>标签对,则需要进行以下操作:

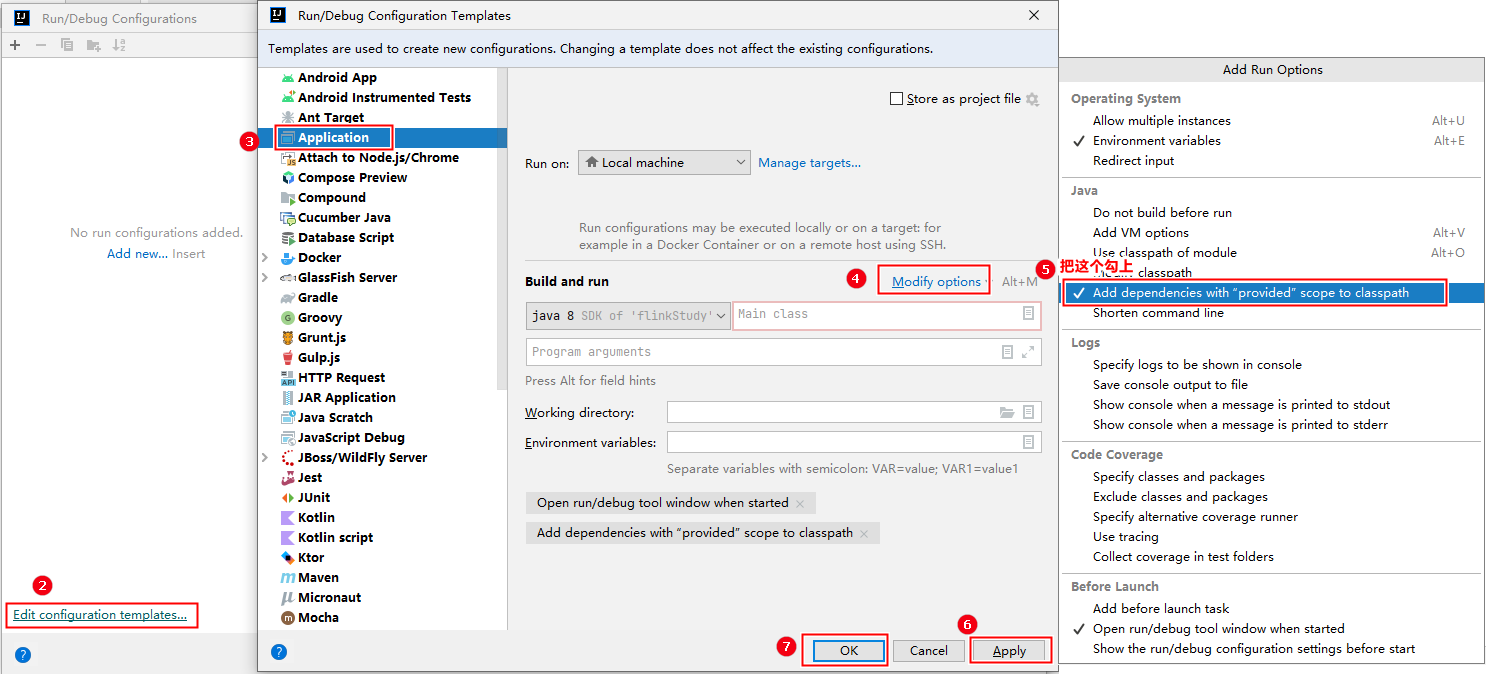
如果编译程序没有问题,运行程序时报错
classpath not found一般就是这个地方没有设置的原因。
第三步:配置日志
在目录 src/main/resources 下添加文件:log4j.properties
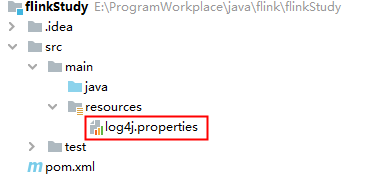
内容配置如下:
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
第四步:编写代码
(1) 数据准备
在项目下创建input文件夹,再在该文件夹下创建words.txt文件
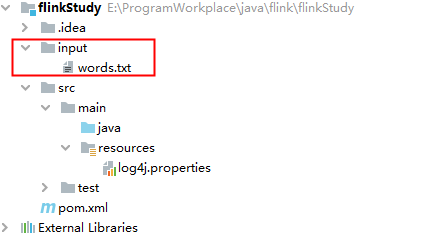
文件内容为:
hello world
wang hello
hello wang
hello hello hello
wang wang
(2) 方式一:批处理
-
创建如下包和文件:
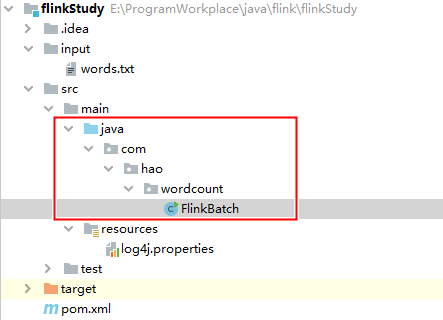
-
FlinkBatch.java文件内容如下:package com.hao.wordcount; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.operators.DataSource; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.util.Collector; public class FlinkBatch { public static void main(String[] args) throws Exception { // 1. 通过 单例模式 获取批处理的 执行环境 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); /* 如果需要设置固定的WebUI端口,则在获取执行环境时需要传入参数 Configuration conf = new Configuration(); conf.setInteger("rest.port", 10000); ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(conf); */ // 2. 获取源数据 (从文件一行一行读取) DataSource<String> dataSource = env.readTextFile("input/words.txt"); // 3. 数据处理 dataSource // (1) 一对多:将一行数据映射为多个单词 .flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String line, Collector<String> out) throws Exception { // 1) 对该行数据切割为一个一个的单词 String[] words = line.split(" "); // 2) 将单词加入到收集器中 for (String word : words) { out.collect(word); } } }) // (2) 一对一:将单词 word 映射为 (word, 1) 形式。 // 这一个算子其实可以省略,在flatMap中返回out.collect(Tuple2.of(word, lL));即可 .map(new MapFunction<String, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(String word) throws Exception { return Tuple2.of(word, 1L); } }) // (3) 分组统计 .groupBy(0) // DataSet API 的算子 .sum(1) // (4) 打印统计结果 .print(); } } -
运行结果如下:

注意:这里批处理使用的是
DataSet API,下面的流处理使用的是DataStream API。事实上 Flink 本身是流批统一的处理架构,批量的数据集本质上也是流(是有界的数据流),没有必要用两套不同的 API 来实现。所以从 Flink 1.12 开始,官方推荐的做法批处理也使用DataStream API,只需要在提交任务是将执行模式设为 BATCH即可:$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar这样,
DataSet API就处于弃用状态,在实际应用中我们只要维护一套 DataStream API 就可以了,即流批一体。
(3) 方式二:流处理
* 以有界流的方式
-
创建如下文件:
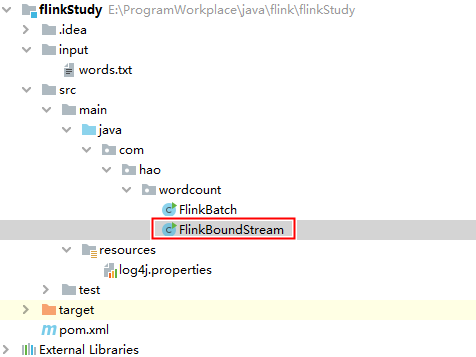
-
FlinkBoundStream.java文件内容如下:package com.hao.wordcount; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class FlinkBoundStream { public static void main(String[] args) throws Exception { // 1. 获取 有界流 的 执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); /* 如果需要设置固定的WebUI端口,则在获取执行环境时需要传入参数 Configuration conf = new Configuration(); conf.setInteger("rest.port", 10000); ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(conf); */ // 2. 设置并行度 env.setParallelism(1); // 3. 获取源数据 DataStreamSource<String> dataStreamSource = env.readTextFile("input/words.txt"); // 4. 数据处理 dataStreamSource // (1) 一对多:将一行数据映射为多个单词, // 同时做一对一映射转换:将单词 word 映射为 (word, 1) 形式。 .flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() { @Override public void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception { // 1) 对该行数据切割为一个一个的单词 String[] words = line.split(" "); // 2) 将单词以元组(word, 1)的形式加入到收集器中 for (String word : words) { out.collect(Tuple2.of(word, 1L)); } } }) // (3) 分组统计 // 后面的String是打上的标签类型,后面会根据标签分组。 // 因为这里是根据tuple2.f0字段分组,所以标签类型和tuple2.f0类型相同 .keyBy(new KeySelector<Tuple2<String, Long>, String>() { // DataStream API 的算子 @Override public String getKey(Tuple2<String, Long> tuple2) throws Exception { return tuple2.f0; // f0是指元组的0下标字段 } }) .sum(1) .print(); // 5. 执行(流数据处理必须有这一步) env.execute("BoundStream"); // 传入的字符串是设置该job的名字,在WebUI界面会显示 } }与批处理有3点不同:
- 流处理需要设置并行度:

- 分组的算子不同:批处理为groupBy(),流处理为keyBy()

- 流处理在最后必须执行:

- 流处理需要设置并行度:
-
运行结果为:
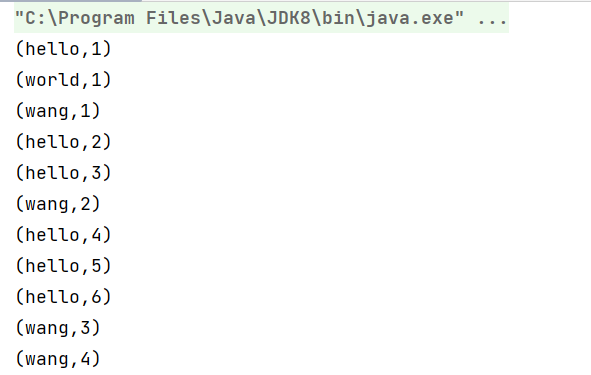
* 以无界流的方式
无界流的数据是没有定义数据的结束,所以不能使用上面有界的words.txt文件,需要用一台机器来不断的输入数据:
-
创建如下文件:
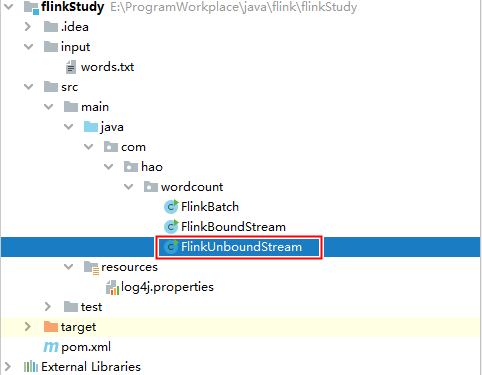
-
FlinkUnboundStream.java文件内容如下:package com.hao.wordcount; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class FlinkUnboundStream { public static void main(String[] args) throws Exception { // 1. 获取 有界流 的 执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); /* 如果需要设置固定的WebUI端口,则在获取执行环境时需要传入参数 Configuration conf = new Configuration(); conf.setInteger("rest.port", 10000); ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(conf); */ // 2. 设置并行度 env.setParallelism(1); // 3. 获取源数据(从远程机器上获取) DataStreamSource<String> dataStreamSource = env.socketTextStream("192.168.10.111", 9999); // 4. 数据处理 dataStreamSource // (1) 一对多:将一行数据映射为多个单词,同时做一对一映射转换:将单词 word 映射为 (word, 1) 形式。 .flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() { @Override public void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception { // 1) 对该行数据切割为一个一个的单词 String[] words = line.split(" "); // 2) 将单词以元组(word, 1)的形式加入到收集器中 for (String word : words) { out.collect(Tuple2.of(word, 1L)); } } }) // (3) 分组统计 // 后面的String是打上的标签类型,后面会根据标签分组。 // 因为这里是根据tuple2.f0字段分组,所以标签类型和tuple2.f0类型相同 .keyBy(new KeySelector<Tuple2<String, Long>, String>() { // DataStream API 的算子 @Override public String getKey(Tuple2<String, Long> tuple2) throws Exception { return tuple2.f0; // f0是指元组的0下标字段 } }) .sum(1) .print(); // 5. 执行(流数据处理必须有这一步) env.execute("UnboundStream"); // 传入的字符串是设置该job的名字,在WebUI界面会显示 } }与有界流数据区别:读取数据的方式不同

-
源数据的准备:
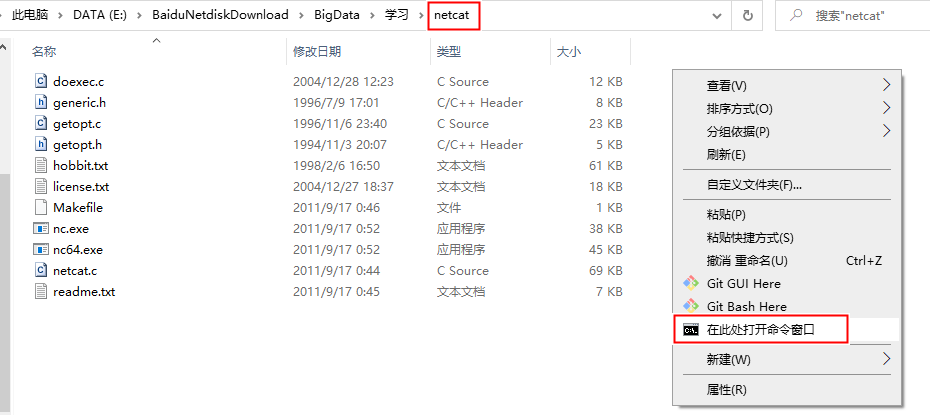
① 在待输入源数据的主机中下载nc链接: https://pan.baidu.com/s/128wPq848M93ra-w6gXL02w 提取码: rktv ② 然后在natcat包下打开cmd,并输入
nc -lp 9999
-
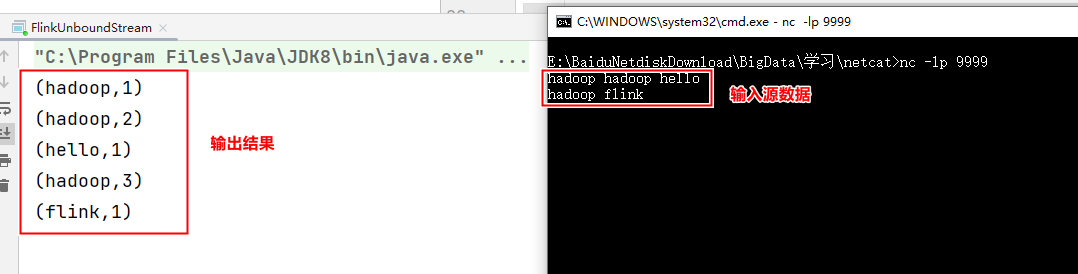
在cmd中输入数据,程序就会同步的输出结果:



















 6063
6063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











