







- 相关课程:王中风《数字信号处理的VLSI实现》
- 相关教材:《VLSI数字信号处理系统设计与实现》
第1章:数字信号处理系统导论
- 数字设计的目标是在尽可能提高性能的同时保持低廉的价格,有以下性能指标
- 所需的硬件电路和资源(即占用的空间或面积)
- 执行的速度:取决于吞吐率和时钟速率
- 功耗:完成某个给定任务需要的总能量
- 有限字长的性能(即量化噪声和舍入噪声)(对于定点DSP系统,尤其是数字滤波器)
- 卷积
- 即在时刻n的输出y(n)可以看作是x(k)和h(-k+n)的内积(在无穷范围内求和);【h(n):单位样值(或冲激)响应】
- 卷积是用来描述线性时不变(LTI: Linear Time-Invariant)系统的。若h(n)有限长,则该系统称为有限冲激响应(FIR:Finite Impulse Response】;如果h(n)具有无限长度,则为无限冲激相应(IIR:Infinite Impulse Response】
- 如果y(n)的计算只与过去的采样值相关,则该系统为因果(Causal)的。对于因果的LTI系统,单位样值相应应满足当n<0时,h(n)=0。(非因果的系统无法用硬件或软件实现)
- 相关
- 两个序列a(n)和x(n)的相关定义为:
- 可以看作如下的卷积运算:
- 两个序列a(n)和x(n)的相关定义为:
- 数字滤波器
- 一个因果的数字滤波器可以用它的单位样值响应
、频率响应
(或者传输函数
)或者差分方程来完整地表达。其中单位样值响应和频率响应描述了系统的时域和频域性质,差分方程则清楚地反映实现该滤波器所需的计算。
- 一个线性时不变因果滤波器可以用如下差分方程描述:
- 一个因果的数字滤波器可以用它的单位样值响应
- 部分名词解释:
- 迭代(iteration):将算法中的所有计算运行一次称为一次迭代
- 一个DFG的一次迭代表示DFG中每个节点都正好执行一次
- 迭代周期(iteration period):算法中进行一次迭代所需的执行时间
- 迭代率(iteration rate):迭代周期的倒数
- 采样率(也作吞吐率):每秒处理的样点数目
- 关键路径(critical path):组合逻辑中,为输入与输出之间的最长路径;时序逻辑中:任何两个存储单元(或者延时单元)之间的最长路径。(也即:关键路径中不含存储单元、延迟单元等,所以这也是插入流水线可以降低关键路径的原因)
- 关键路径的运算时间确定了DSP系统最小可行的时钟周期(clock period)
- 迟滞(latency):产生输出的时间与系统接收对应输入的时间之差
- 迭代(iteration):将算法中的所有计算运行一次称为一次迭代
- DSP算法的图形表示方法:
- 框图:由功能模块(如加法器、乘法器等)以及将其连接起来的带有方向的边组成的,这些边代表数据从输入模块到输出模块的流动,可以包含或不包含延迟单元(可以表示成
或
)。
- 数据广播结构(data-broadcast):输入的数据在同一时刻广播到了所有的乘法器进行运算
- 譬如对于3阶FIR滤波器:
,可以通过不同的框图实现

- 信号流图(Signal-Flow Graph, SFG):是节点和有向边的集合。节点表示运算或任务,边线(j, k)表示节点j处的信号到节点k处信号的线性变换。
- 流图反转(flow graph reversal)或转置(transposition)

- 通常SFG只能用于线性网络,无法用来描述多采样率DSP系统
- 数据流图(Data-Flow Graph, DFG):节点表示运算(或功能、或子任务),每个节点都有与之相关的执行时间;有向边表示数据通路(节点之间的通信),每条边有一个非负的延时数与之相关
- 归一化的时间单位(u.t., units of time)
-
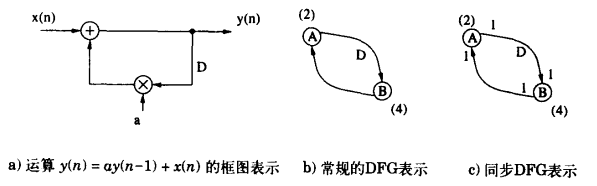
- 一个带有多条输入边的节点只有所有的前节点都启动之后才能启动,因此给DFG施加了优先级约束(precedence constraint)的含义:
- 如果边的延迟为0,那么为迭代内优先级约束(intra-interation)(单箭头):
- 如对于b图,规定B的第k次迭代必须在A的第k次迭代之前执行,
- 如果边线有一个延时或多个延时,则是一种迭代间优先级约束(inter-iteration)(双箭头):
- 如对于a图,规定A的第k次迭代的执行必须在B的第(k+1)次迭代前完成,
- 如果边的延迟为0,那么为迭代内优先级约束(intra-interation)(单箭头):
- DFG和框图能描述线性单速率DSP系统,也能用来描述非线性多速率DSP系统
- 如果粒度是在信号处理子任务层次上,比如滤波,那么这种DFG称为粗粒度(coarse-grain)的数据流图
- 一个带有多条输入边的节点只有所有的前节点都启动之后才能启动,因此给DFG施加了优先级约束(precedence constraint)的含义:
- 依赖图(Dependence Graph, DG)
- 框图:由功能模块(如加法器、乘法器等)以及将其连接起来的带有方向的边组成的,这些边代表数据从输入模块到输出模块的流动,可以包含或不包含延迟单元(可以表示成
第2章:迭代边界
- 关键路径:在DFG中,具有零延时的所有路径中,具有最长运算时间的路径。关键路径的运算时间就是DFG的一次迭代所需的最小运算时间。
- 递归DFG存在着一个基本极限,表示了用硬件实现基本的DSP程序能够有多快,这个极限称为迭代边界(iteration bound)
环路边界和迭代边界
- 环路是指起点和终点都是同一个节点的有向路径。
- 环路边界:第l个环路的环路边界是指
,其中
是环路运行时间,
是指环路中延时数目
- 关键环路:具有最大环路边界的环路
- 迭代边界(iteration bound):关键环路的环路边界就是DSP程序的迭代边界,是DSP程序中迭代或采样周期的最低限制,与可用的运算资源的多少无关。
- 求解迭代边界的直接办法就是找出所有的环路;然而随着节点数的增加,环路指数会以指数形式增加,需要很多的运行时间。因此可通过以下方法计算:
- 最长路径矩阵(longest path matrix, LPM)和最小环均值(minimum cycle mean, MCM)以及负周期检测算法(negative cycle detection)
最长路径矩阵(LPM)
- 若d表示DFG中的延时数目,构建矩阵
,满足从延时单元
到延时单元
经过正好
个延时(不包括和)的所有路径中,用
表示最长的运算时间;如果这样的路径不存在,那么
- 通过DFG确定
后,更高阶的矩阵
,通过以下规则进行递归计算:
-
,其中
是区间
中使得
或
都不满足的整数k的集合
-
- 一旦矩阵
计算出之后,迭代边界可以通过对角线的值确定:
-
-
- 可以考虑编程实现!
- 单速率DFG(single-rate DFG, SRDFG),即每次迭代中每个节点正好执行一次的DFG
- 多速率DFG(multirate DFG, MRDFG),即在一次迭代中允许每个节点执行多次,而且在一次迭代中不要求2个节点执行相同的次数。计算MRDFG的迭代边界方法如下:
- 构建一个等价于MRDFG的SRDFG
- 采用LPM或者MCM算法计算等价SRDFG的迭代边界















 3518
3518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









