







手动实现代码
import random
import numpy as np
import torch
import matplotlib.pyplot as plt
def synthetic_data(w,b,num_examples):
""" y = Xw+b+噪声 本次实际是y = x1*w1 + x2*w2 + b"""
x = torch.normal(0,1,(num_examples,len(w)))##均值 标准差 num个样本
##len第一维大小即w行数
y = torch.matmul(x,w) + b ## 矩阵乘
y +=torch.normal(0,0.01,y.shape) ## +b
return x,y.reshape((-1,1)) ##-1表示自动推导
def data_iter(batch_size,features,labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)##打乱
for i in range(0,num_examples,batch_size):
batch_indics = torch.tensor(indices[i:min(i+batch_size,num_examples)])
yield features[batch_indics],labels[batch_indics] ##返回迭代器类似于指针,
##可以用for in 迭代访问
def linreg(X,w,b):
return torch.matmul(X,w) + b##X,w矩阵乘 + b
def squared_loss(y_hat,y):
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape))**2 / 2## (y_hat - y)的平方/2
##reshape为了防止广播
##个人理解广播就是两个矩阵不是相同形状时,自动扩展成相同形状再做加减
def sgd(params,lr,batch_size):
"""小批量随机梯度下降"""
"""我们想让它不断的往收敛方向走以找到较优解,而梯度的反方向就是最快的方向
所以更新参数[w,b]"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
## 生成数据
true_w = torch.tensor([2,-3.4])
true_b = 4.2
features,labels = synthetic_data(true_w,true_b,1000)
lr = 0.03
num_epochs = 3
batch_size = 10
net = linreg
loss = squared_loss
w = torch.normal(0,0.01,size=(2,1),requires_grad=True)
b = torch.zeros(1,requires_grad=True)
for epoch in range(num_epochs):
for X,y in data_iter(batch_size,features,labels):
l = loss(net(X,w,b),y)
l.sum().backward()
sgd([w,b],lr,batch_size)
with torch.no_grad():
train_l = loss(net(features,w,b),labels)
print(f'epoch{epoch+1},loss{float(train_l.mean()):f}')
print(f'w的估计误差:{true_w-w.reshape(true_w.shape)}')
print(f'b的估计误差:{true_b-b}')
##tensor转numpy .detach().numpy()
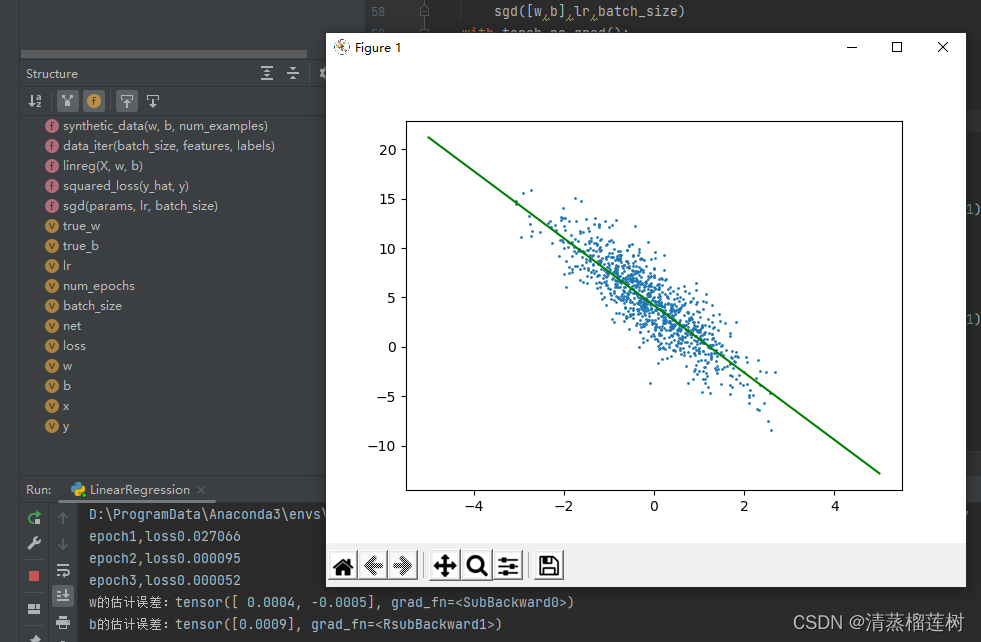
plt.scatter(features[:,1].detach().numpy(),labels.detach().numpy(),1) ##画散点
x = np.linspace(-5,5,50)
y = x * w[1].detach().numpy() + b.detach().numpy()
plt.plot(x,y,color='green') ##画线
plt.show()
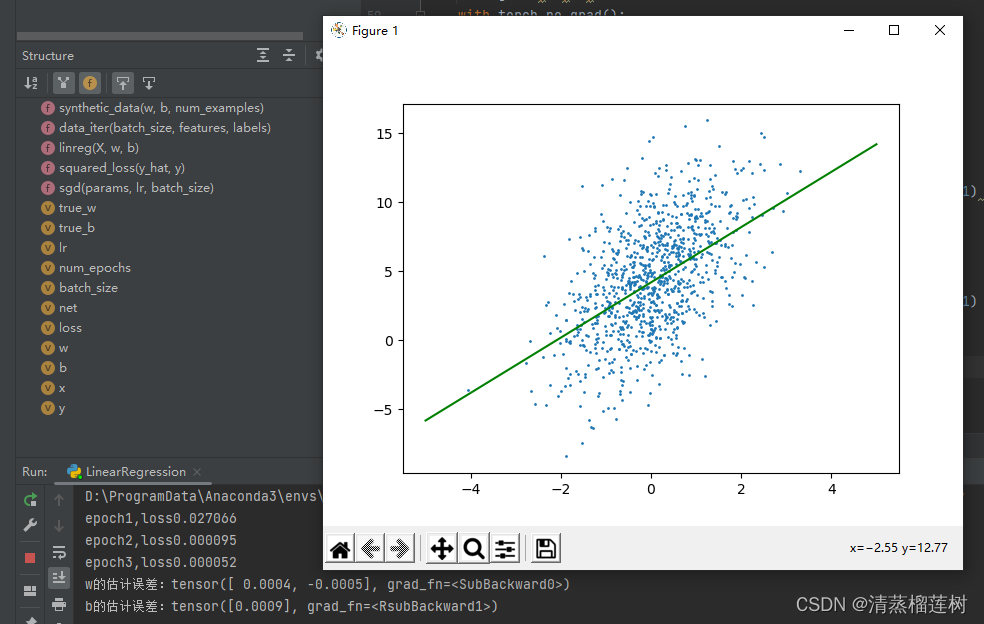
plt.scatter(features[:,0].detach().numpy(),labels.detach().numpy(),1)
y = x * w[0].detach().numpy() + b.detach().numpy()
plt.plot(x,y,color='green')
plt.show()
运行结果
pytorch实现代码
import numpy as np
import torch
from torch.utils import data
from torch import nn
import matplotlib.pyplot as plt
def synthetic_data(w,b,num_examples):
""" y = Xw+b+噪声 本次实际是y = x1*w1 + x2*w2 + b"""
x = torch.normal(0,1,(num_examples,len(w)))##均值 标准差 num个样本
##len第一维大小即w行数
y = torch.matmul(x,w) + b ## 矩阵乘
y +=torch.normal(0,0.01,y.shape) ## +b
return x,y.reshape((-1,1)) ##-1表示自动推导
def load_array(data_arrays,batch_size,is_train=True):
"""构造torch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset,batch_size,shuffle=is_train)
true_w = torch.tensor([2,-3.4])
true_b = 4.2
features,labels = synthetic_data(true_w,true_b,1000)
batch_size = 10
data_iter = load_array((features,labels),batch_size)##类似于手动实现时的yield返回迭代器
# print(next(iter(data_iter)))
net = nn.Sequential(nn.Linear(2,1))
net[0].weight.data.normal_(0,0.01)
net[0].bias.data.fill_(0)
loss = nn.MSELoss() ## 均方
trainer = torch.optim.SGD(net.parameters(),lr=0.03)##随机梯度下降,相同时间多次更新参数
##加速收敛
num_epochs = 3
for epoch in range(num_epochs):
for X,y in data_iter:
trainer.zero_grad() ## 清零梯度,pytorch梯度累计而不是替换
##个人觉得这句话也可以写在backward之后,
##只要上次计算的梯度不影响下次就行
l = loss(net(X),y)
l.backward() ## 自动计算梯度
trainer.step() ##根据梯度,使用优化器,更新参数
l = loss(net(features),labels)## 这里只是看一下现在的loss
## 不需要清梯度,没有backward,没有计算梯度
print(f'epoch{epoch+1},loss{l:f}')##:f表示以浮点数形式输出,有点类似于c语言
##tensor转numpy .detach().numpy()
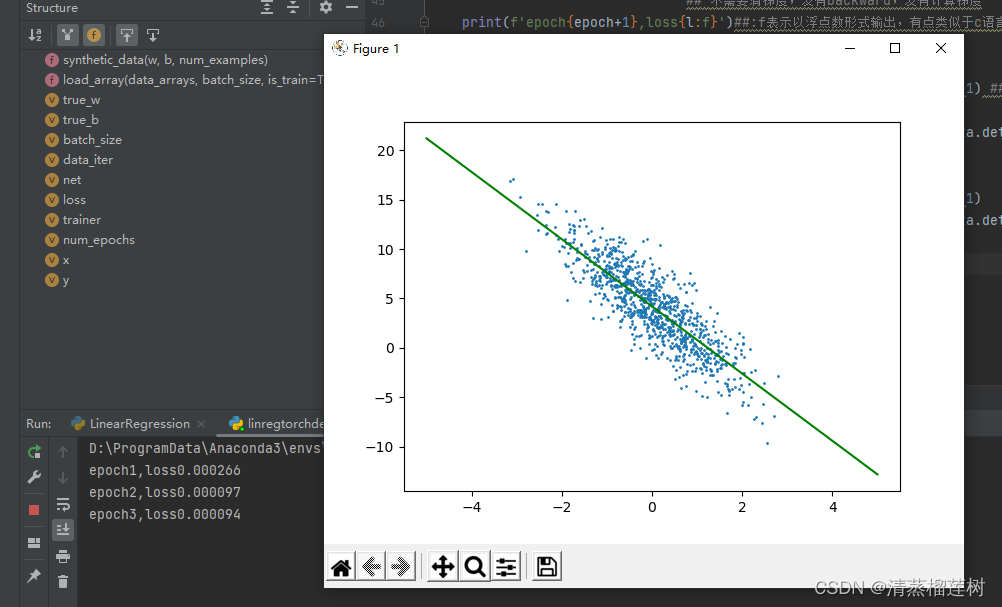
plt.scatter(features[:,1].detach().numpy(),labels.detach().numpy(),1) ##画散点
x = np.linspace(-5,5,50)
y = x * net[0].weight.data[0][1].detach().numpy() + net[0].bias.data.detach().numpy()
plt.plot(x,y,color='green') ##画线
plt.show()
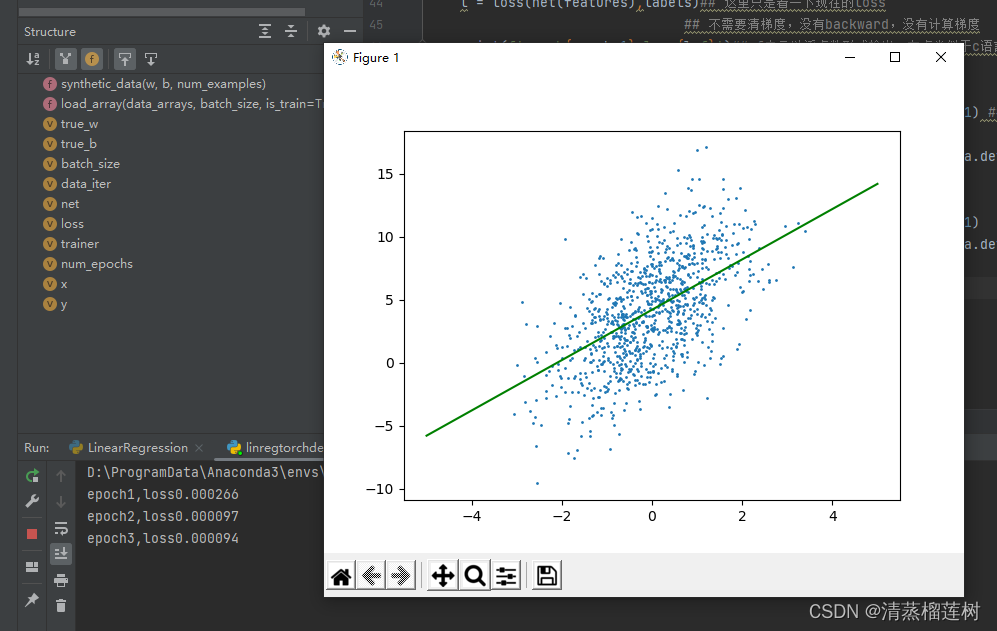
plt.scatter(features[:,0].detach().numpy(),labels.detach().numpy(),1)
y = x * net[0].weight.data[0][0].detach().numpy() + net[0].bias.data.detach().numpy()
plt.plot(x,y,color='green')
plt.show()
运行结果















 652
652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









