







多版本并发控制(MVCC)
前置知识:事务
并发问题
脏读
事务A中读取到事务B中未提交的数据。具体来说,在t1时刻,事务A中读取到事务B中未提交的数据,并将该数据用于计算得到一个结果值;而在t2时刻,事务B执行回滚,那么事务A中得到的结果值就没有任何意义,这种现象就称为脏读。
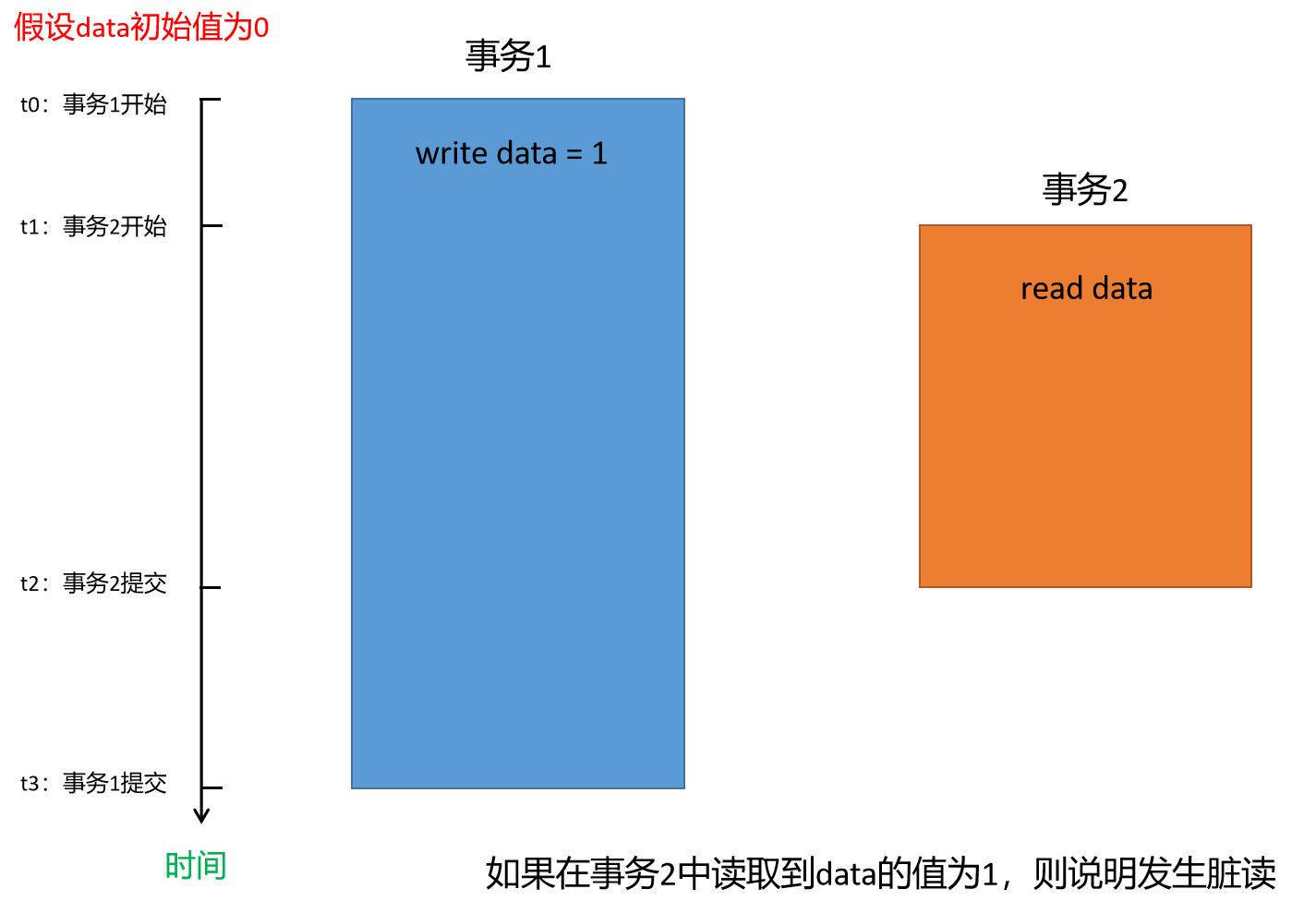
# 脏读问题演示
# 事务1: 设置全局的隔离级别为读未提交, 设置完成后重新登录MySQL
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
# 检查隔离级别
SELECT @@TRANSACTION_ISOLATION;
# 事务1: 修改一条数据
BEGIN;
UPDATE `user` SET name = 'root' WHERE id = 1;
# 事务2: 查看数据
BEGIN;
SELECT * FROM `user` WHERE id = 1;
# 此时能够观测到事务2中读取到事务1中的修改, 但是事务1并未提交
# 将隔离级别改回默认级别, 重启控制台
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
# 检查隔离级别
SELECT @@TRANSACTION_ISOLATION;
不可重复读
事务A在一次事务的执行过程中,两次读取结果不相同。具体来说,在t1时刻,事务A读取数据x1;在t2时刻,事务B将数据修改为x2并提交事务;在t3时刻,事务A再次读取数据得到x2;站在事务A的角度,可能在t1时刻到t3时刻并没有对数据进行修改,却得到两个不同的值(都是正确值),这种现象称为不可重复读。
幻读
个人认为:幻读和不可重复读本质上没有区别,幻读属于不可重复读的一部分。
面试:幻读侧重查询结果行数是否发生变化,而不可重复读侧重查询内容(数据的值)是否发生变化。
解决了不可重复读的问题,即在一次事务中,可以保证对数据的两次读取的结果是相同的。但是会出现幻读的问题。幻读问题是指事务A在查询时明明没有查到该数据,但是却无法插入成功。具体来说,在t1时刻,事务A查询是否有id=1的数据,发现没有;在t2时刻,事务B插入一条id=1的数据并提交;在t3时刻,事务A再次查询是否有id=1的数据,还是发现没有(因为可重复读),因此事务A打算插入一条id=1的数据,但是此时插入失败并报错,这时事务A就会纳闷,明明查询id=1的结果是没有,但是插入又报错说id=1的数据已经存在,这种现象称为幻读。
# 事务1: 查看数据
BEGIN;
SELECT * FROM `user`;
# 事务2: 查看数据, 新增数据, 并提交事务
BEGIN;
SELECT * FROM `user`;
# 注: insert操作会加锁, 如果在事务1未提交前, 事务2也执行了insert操作, 那么事务2会被阻塞
INSERT INTO `user`(id, name) VALUES(7, 'why2');
COMMIT;
# 事务1: 再次查看数据
# 在RR级别下, 由于可重复读机制, 因此事务1看不到事务2提交的数据, 但是插入失败
# 在RC级别下, 可以看到新插入的数据, 因此行数更多(幻读)
SELECT * FROM `user`;
# 事务1: 尝试插入相同的数据, 此时报错(这里演示RR级别下的错误, RC级别下能看到有id=7的数据)
INSERT INTO `user`(id, name) VALUES(7, 'why1');
# 错误: ERROR 1062 (23000): Duplicate entry '7' for key 'user.PRIMARY'
隔离级别
三个问题,对应四种方案,分别是解决0个问题(读未提交)、解决1个问题(读已提交)、解决2个问题(可重复读)、解决3个问题(串行化)。
串行是一切并行问题的终点,没有并行就不会有并行导致的伴生问题。
Oracle 数据库的默认隔离级别是 RC,MySQL 数据库的默认隔离级别是 RR。
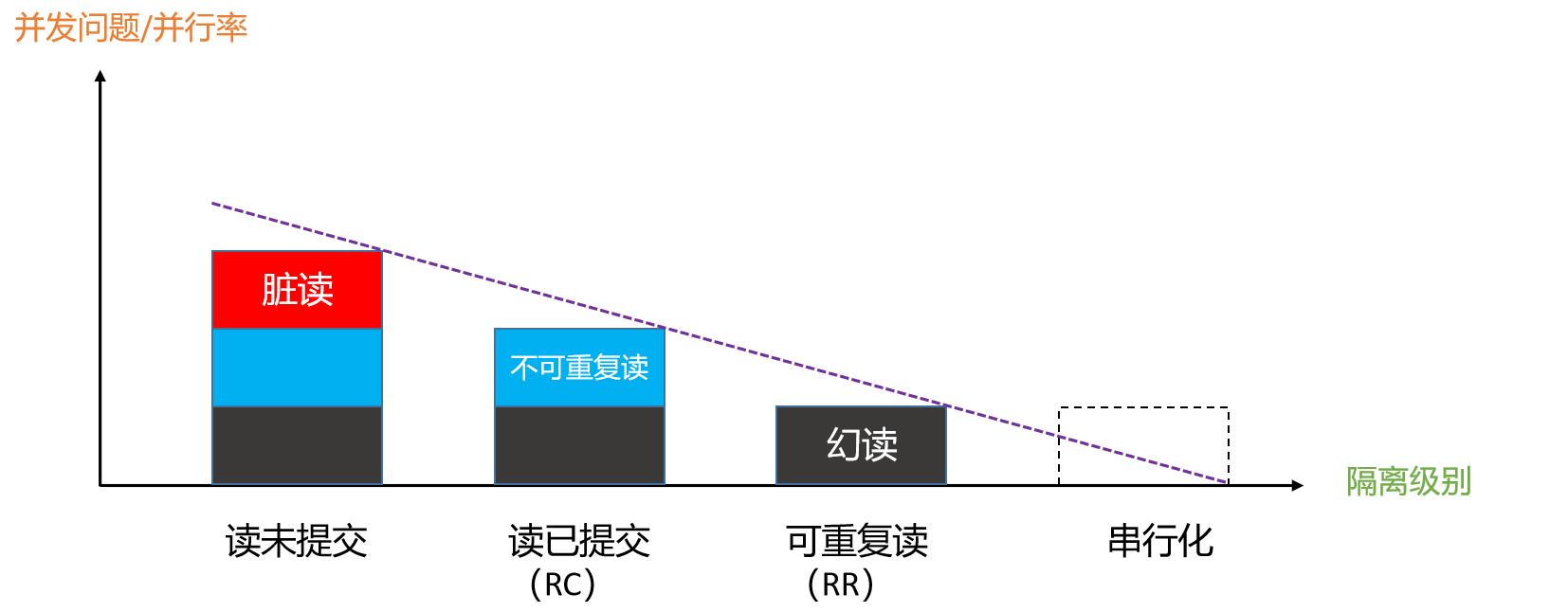
隔离级别之间的关系
可重复读并不是建立在读已提交的基础上,相反,这些隔离级别是互斥的。想要实现可重复读,那么必然会丢弃读已提交的性质。想要实现读已提交的数据,那么就没办法实现可重复读的性质。
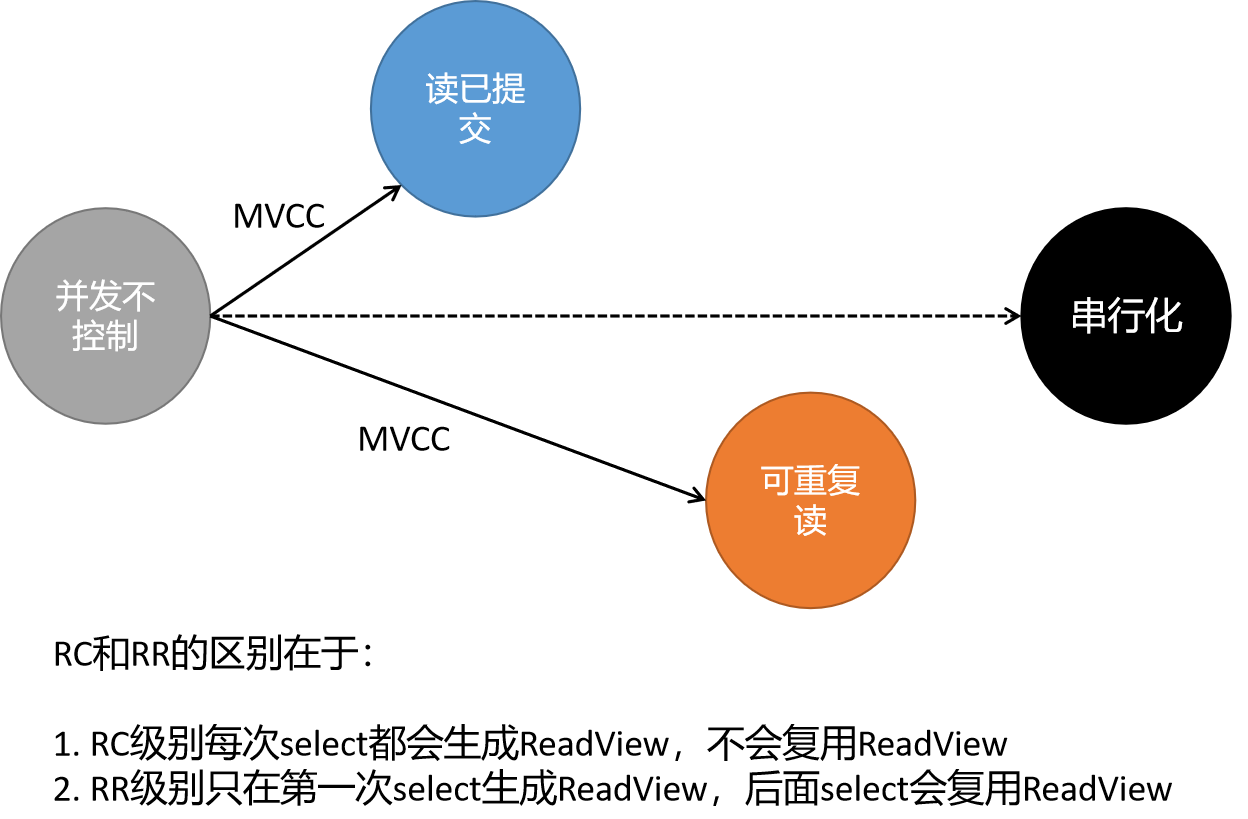
思考:设置不同的事务隔离级别这种功能的底层原理是什么?如何实现的?是对修改后的数据写入磁盘文件的时间点决定的吗?例如,读未提交级别,则事务中执行的修改操作都会立即写入磁盘,此时其它事务就可能在该事务提交前感知到这个修改操作,因此出现脏读问题?
操作指令
# 查看内置的变量值
SELECT @@autocommit;
# 开启事务: 方式一
SET @@autocommit=0;
# 开启事务: 方式二
BEGIN;
# 提交事务
COMMIT;
# 回滚事务
ROLLBACK;
# 查看事务的隔离级别
SELECT @@TRANSACTION_ISOLATION;
# 设置事务的隔离级别
# 需要退出当前会话窗口
SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE}
MVCC 是什么
并发可能遇到三种场景:读-读、读-写、写-写
对于读-读场景,不存在并发问题;而对于后面两种场景,则存在并发问题,这些并发问题都可以通过加锁来解决。但是对于读-写冲突的场景,存在着比加锁性能更高的解决方案,即 MVCC(多版本并发控制)。因此,MVCC 是针对并发场景下的读写冲突问题,对于读操作不采用加锁的一种优化方案。对于写操作还是需要采用加锁。
MVCC 的实现原理
MySQL 中的 MVCC 是通过 4个隐藏字段、undo 日志和 read view 的共同作用实现。在读操作时,生成一个read view
隐藏字段
- db_row_id:自增的隐藏主键,如果没有表结构没有指定主键,则会生成该字段
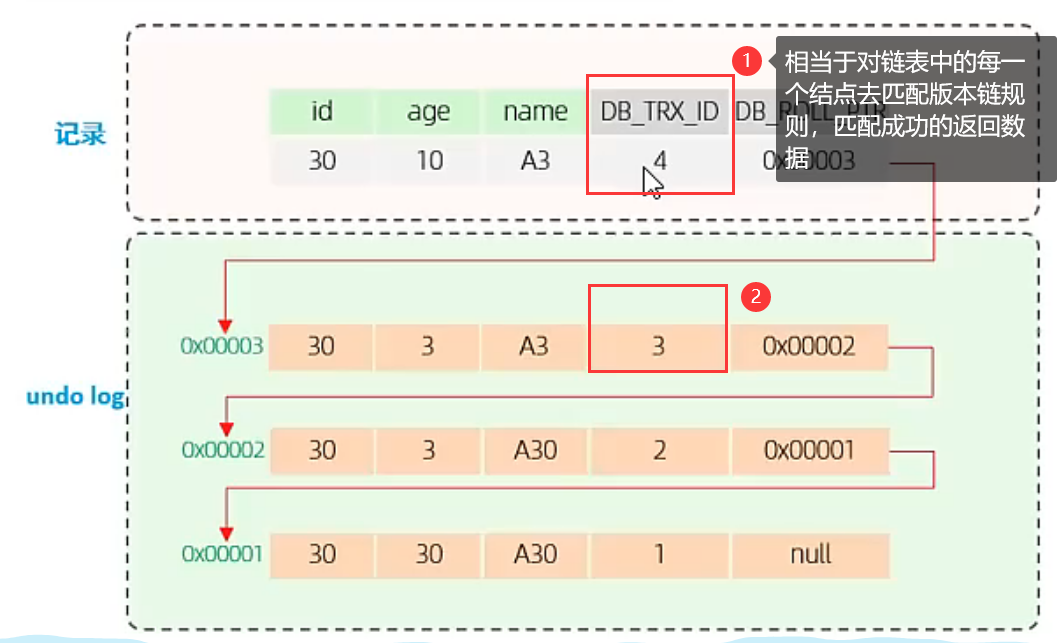
- db_trx_id:最近修改的事务id,记录该条记录最近一次被哪个事务修改
- db_roll_ptr:上一条记录的地址,本质上是next指针
- deleted_bit:逻辑删除标志位

undo log
undo log 用于记录数据被修改前的信息,用于事务回滚或MVCC(多版本并发控制)。
与 redo log 记录实际执行的物理操作不同,undo log 并不是记录实际执行的数据操作,甚至是记录与当前操作相反的操作(逆操作),例如当前实际执行的是delete 操作,那 undo log 中需要对该操作进行还原,因此记录 insert 操作。
-
insert undo log:保存插入记录的主键值,回滚时只需要删除该主键对应的记录即可
-
update undo log:保存记录的旧值,回滚时将记录更新回旧值
-
delete undo log:理论上将记录的旧值保存下来,回滚的时候重新插入记录即可(主键变化怎么办呢?)。但实际为了效率并没有这么处理。
设置删除标志位(隐藏字段),InnoDB 引擎通过专门的 purge 线程来清理这些删除标志位被设置true的记录。这种情况下如何实现回滚呢?
undo log 在事务提交之后,并不会立即删除,因为这些日志还可能用于 MVCC。undo log 采用 segment(段)的方式进行管理和记录,存放在 rollback segment (回滚段)中,内部包含 1024 个 rollback segment。这里是什么的内部?
undo log 日志中,insert undo log 日志只在事务回滚的情况下需要,因此在事务commit之后,insert undo log 可以被立即删除。但是 delete undo log 和 update undo log 不仅在回滚的时候需要,在快照读的时候也需要,因此不能被立即删除。
简洁点来说,undo log 日志应该体现 insert、update、delete 操作,但是 insert 插入的是新数据,那么该行数据对应的 undo log 版本链就只有一个结点,因此改行数据没有 undo log。
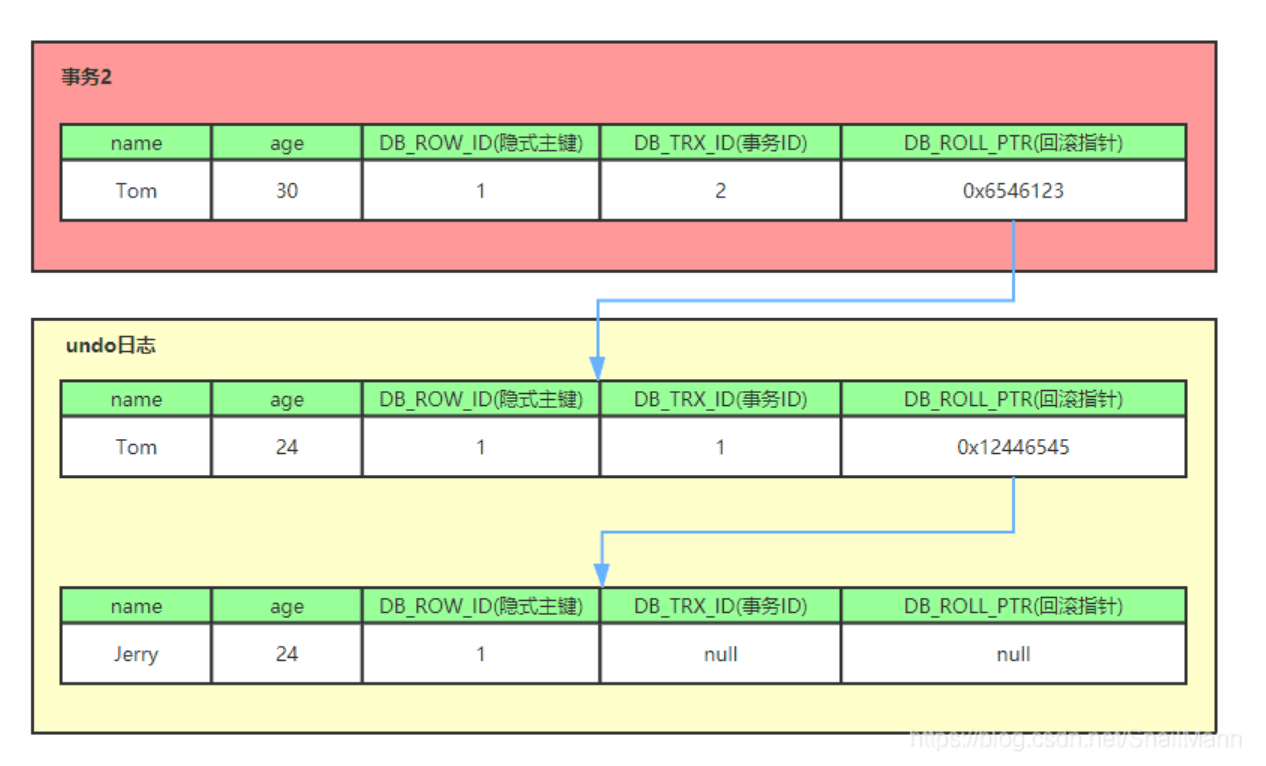
read view(读视图)
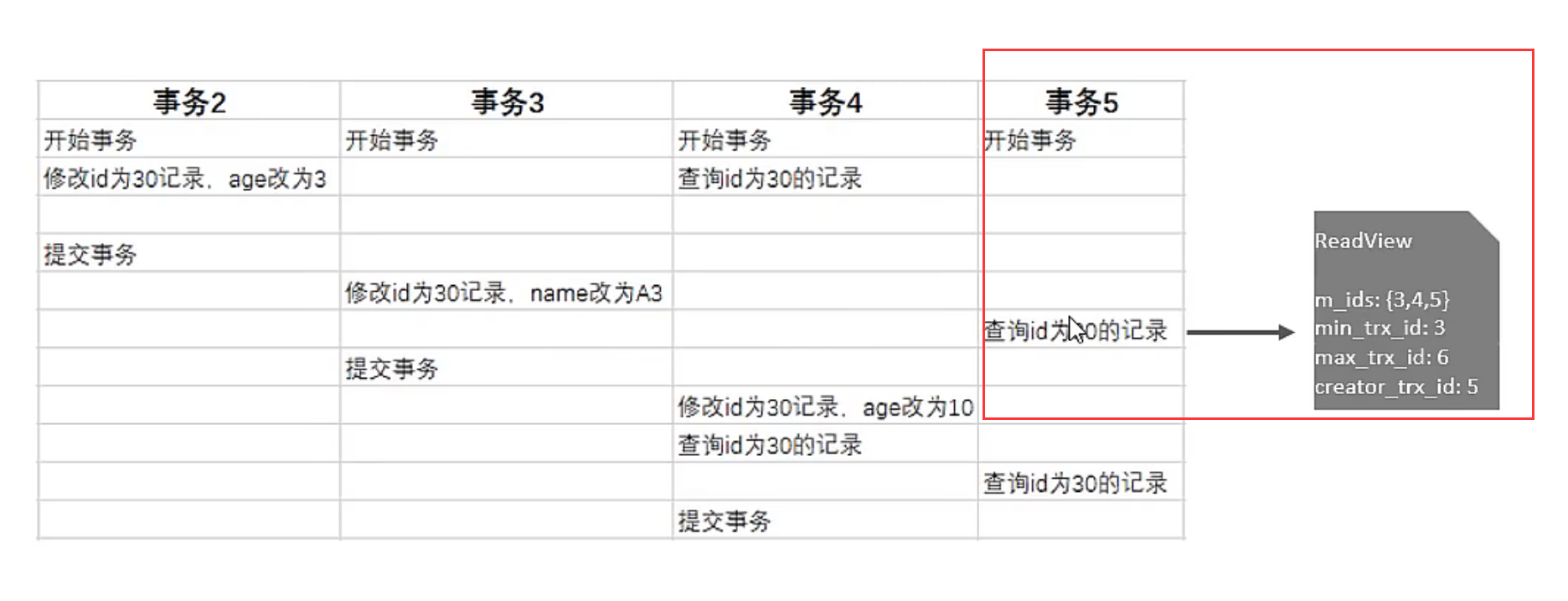
存疑:max_trx_id是当前最大事务ID+1吗?需要加1吗?因为后面的判断逻辑是trx_id > max_trx_id,那似乎只需要是当前最大事务的id即可。
ReadView的生成原理(快照读的原理)
对于数据表中,每一条记录都有一个版本链,而快照读可以认为是在生成ReadView的那一个时刻(即进行快照读的那一个时刻),应该将查询结果中的每条记录的那个版本保存到快照中。核心就是:保存在快照读那个时刻,读自己事务修改的版本和已提交事务的版本。即相对于ReadView而言,读已提交的事务。
- 对于第1条规则,保证自己事务的修改在ReadView中可见
- 对于第2条规则,保证在ReadView生成之前已提交的事务可见
- 对于第3条规则,ReadView并不是生成数据的快照,只是后面都会按照版本链数据访问规则和ReadView中保存的四个字段进行比较。因此,如果当前事务生成ReadView为t1时刻,而后又在t2时刻再次读取时,在t1时刻到t2时刻这段时间间隔内,有其它新事务对数据进行了修改,那么数据的版本号trx_id会比t1时刻生成的ReadView中的max_trx_id更大。而在t2时刻进行读取时,同样会先用最新版本的数据来进行访问规则的匹配,此时出现 trx_id > max_trx_id 的情况。这在RR的隔离级别下容易理解,**但是在RC的隔离级别下,每次读都会读取最新版本,因此第3条规则失效?**应该是这样,否则也不能称为读已提交了。
- 对于第4条规则,保证不会读取未提交事务(当前活跃的事务)中对数据的修改,防止脏读

版本链数据访问规则:

对于第4条规则,为什么 trx_id 不在 ReadView 的 m_ids(活跃事务集合)中时,说明事务是可以看到 trx_id 所对应的那条记录的?
以下图为例,
首先明确 trx_id 是指的什么东西。对于一个事务,在访问某条记录时,看到的是这条记录的一个版本链数据,所以这里的 trx_id 是指这条版本链上所有的 trx_id,从前往后依次查找(尽可能找到当前事务能够看到的最新版本)。
其次解释为什么在第4条规则下,trx_id 不在活跃事务集合里反而说明 trx_id 对应的那个版本的数据可以被事务访问。活跃事务代表未提交事务,而trx_id对应的版本数据如果属于活跃事务,那么说明该版本的数据可能会被回滚,那么其它事务如果能够读取,则说明读取未提交事务修改的数据,即产生脏读问题。
对于第3条规则,所谓的max_trx_id表示在ReadView生成时刻,系统分配的最大事务id。如果 trx_id > max_trx_id,说明 trx_id 对应的这个版本的数据是某个事务在生成 ReadView 的时刻(假设为t时刻)之后

快照读(snapshot read):
- 在 RC(read committed)级别下,每次 snapshot read 都会生成 read view
- 在 RR(repeatable read)级别下,事务内的第一次snapshot read会生成read view,后面的snapshot read都会读取第一次read view中的数据,从而实现repeatable read。
当前读(current read):加锁读取当前数据库中保存的数据。
















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









