







Logistic回归(逻辑回归):用量化特征预测某事发生的概率,取值范围是0到1,多用于二分类问题。
f
=
1
1
+
e
−
t
f = \frac{1}{1 + e^{-t}}
f=1+e−t1
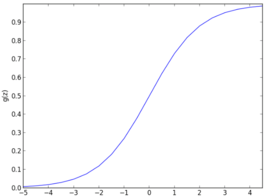
- 输入t:样本特征中的线性函数
- 几率(Odds):设某事件发生的概率为 P,则该事件的几率为该事件发生的概率与不发生的概率之比
O d d s = P 1 − P O d d s ∈ [ 0 , + ∞ ) Odds = \frac{P}{1 - P}\qquad \small Odds\in [ 0,+\infty) Odds=1−PPOdds∈[0,+∞) - 可基于样本的特征构建线性函数,函数值对应时间的对数几率 l o g e ( P 1 − P ) = β 0 + β 1 x \quad log_e(\frac{P}{1-P}) = \beta_0 +\beta_1x\quad loge(1−PP)=β0+β1x其值域为 ( − ∞ , + ∞ ) \;\small(- \infty,+\infty) (−∞,+∞)
bikeshare数据集:http://archive.ics.uci.edu/ml/datasets/Bike+Sharing+Dataset
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
table = pd.DataFrame({'prob':[0.01,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.99]})
table['odds']=table['prob']/(1-table['prob'])
table['log-odds']=np.log(table['odds'])
plt.plot(table['prob'],'g')
plt.plot(table['odds'],'y')
plt.plot(table['log-odds'],'m')
plt.legend({'probability', 'Odds', 'log_odds'})
plt.ylim(-6, 6)
P = e β 0 + β 1 x 1 + e β 0 + β 1 x P = \frac{e^{\beta_0+\beta_1x}}{1 + e^{\beta_0+\beta_1x}} P=1+eβ0+β1xeβ0+β1x
- Logistic回归就是对几率作线性回归
- 优化准则:极大化所有样本的对数似然函数
- 对于非数值型数据:使用 one-hot 编码
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from scipy import stats
from sklearn.model_selection import train_test_split
bikes= pd.read_csv('E:\my_data\\bikeshare\hour.csv')feature_cols=['temp']
x=bikes[feature_cols]
bikes['above_average']=bikes['cnt']>=bikes['cnt'].mean()
y=bikes['cnt']>=bikes['cnt'].mean()
x_train, x_test, y_train, y_test=train_test_split(x, y)
logreg=LogisticRegression()
logreg.fit(x_train, y_train)
print(pd.DataFrame(np.transpose([y_test.values, logreg.predict(x_test)]), columns ={'真实值','预测值'}))
print('\n')
print('分类准确率是:', logreg.score(x_test, y_test))
when_dummies=pd.get_dummies(bikes['season'],prefix='season_')
when_dummies=when_dummies.iloc[:,1:]
new_bikes=pd.concat([bikes['temp'], when_dummies],axis=1)
x = new_bikes
x_train, x_test, y_train, y_test=train_test_split(x, y)
logreg=LogisticRegression()
logreg.fit(x_train, y_train)
print('用气温、季节作为预测自变量,预测的准确率是:', logreg.score(x_test, y_test))















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









