






编码器层:任务是将所有输入序列映射到一个抽象的连续表示,其中包含了整个序列的学习信息。
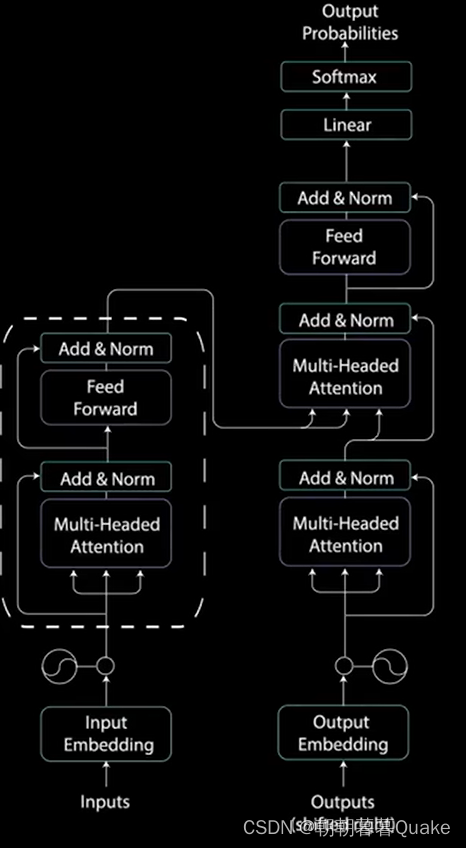
编码器中的多头注意力应用了一种特定的注意力机制,成为自注意力。自注意力允许模型将输入中的每个单词与输入中的其他单词关联起来。
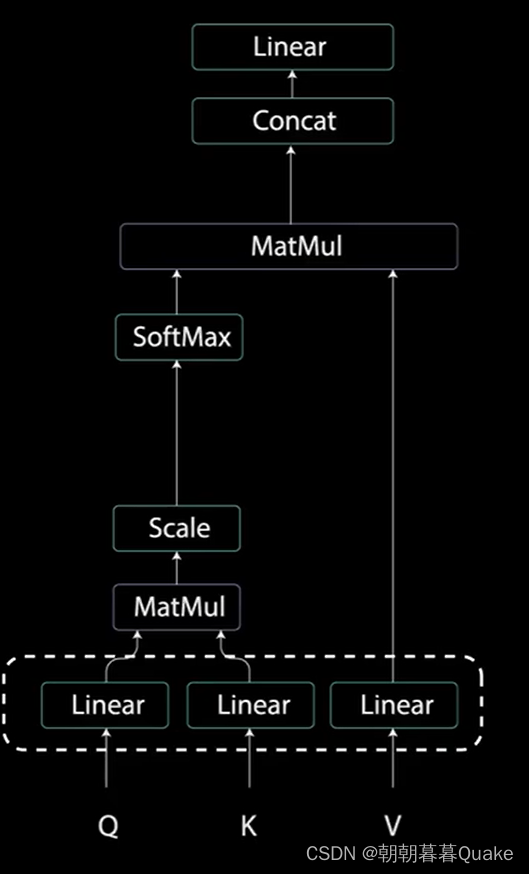
为了实现自注意力,将输入分别送入三个不同的全连接层,以创建查询向量、键向量和值向量。
例如,当在搜索引擎上搜索时,搜索引起会将查询词映射到一组键(例如,视频标题、描述等)。与数据库中的候选视频相关联,然后展示最佳视频。查询和键通过点积矩阵乘法产生一个分数矩阵。分数矩阵确定了一个单词应该如何关注其他单词。

因此每个单词都会有一个时间步长中的其他单词相对应的分数。分数越高,关注度越高。这就是查询如何映射到键的。
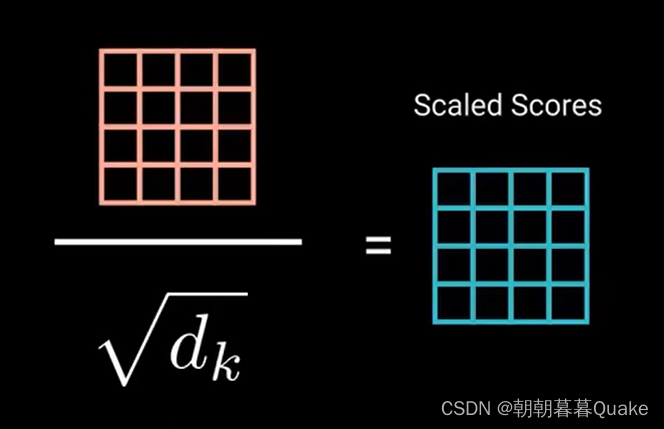
接下来,通过将查询和键的维度开平方来将得分缩放。这样可以让梯度更稳定,因为乘法可能会产生爆炸效果。

对缩放后的得分进行softmax计算,得到注意力权重,从而获得0到1 之间的概率值。进行softmax计算后,较高的得分会得到增强,较低的得分会得到抑制。这让模型在关注哪个词时会更有信心。接着,将注意力权重与值向量相乘,得到输出向量。较高的softmax得分会保留模型认为更重要的词的值。
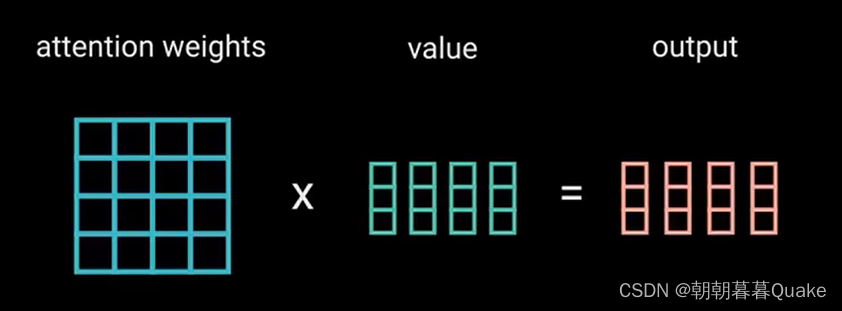
接着,将注意力权重与值向量相乘,得到输出向量。较高的softmax得分会标留模型认为更重要的词的值。较低的得分会淹没不相关的值。将输出向量输入线性层进行处理。
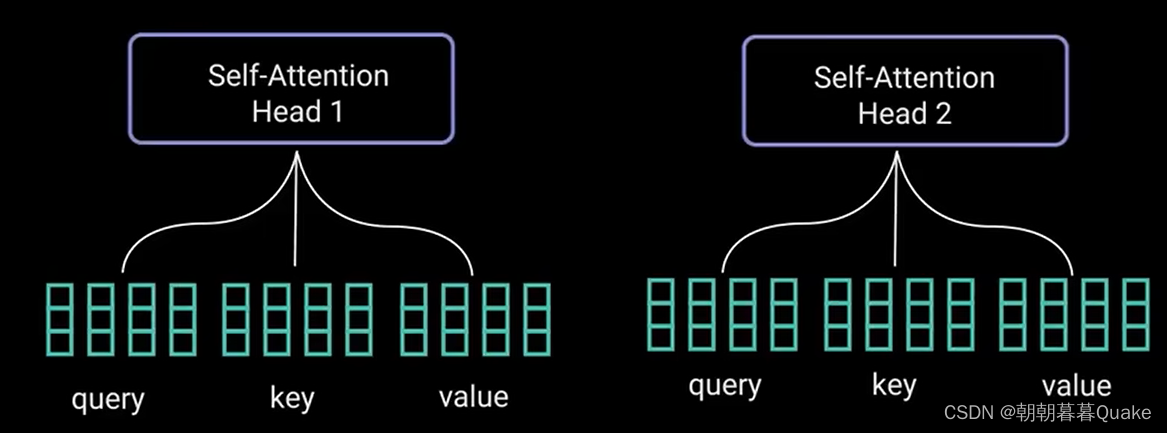
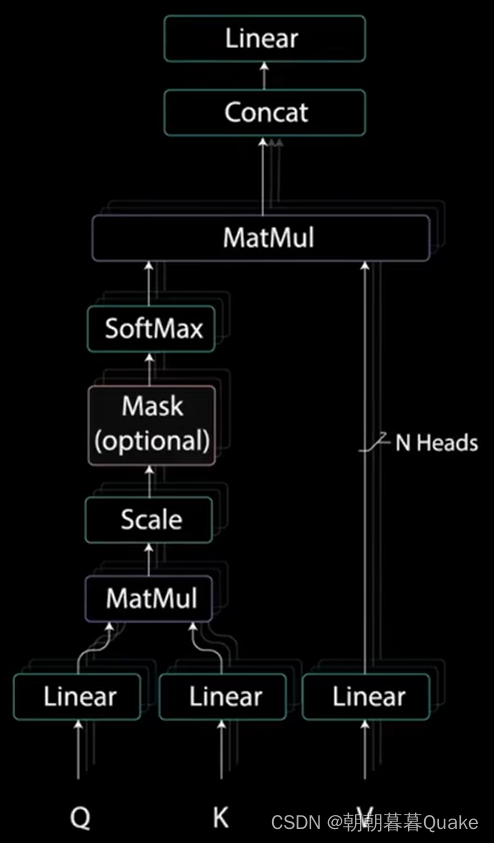
多头注意力计算就是在应用自注意力之前将查询、键和值分为n个向量。分割后的向量分别经过相同的自注意力过程,每个自注意力过程就被称为一个头,每个头 会产生一个输出向量,这些向量在经过最后的线性层之前被拼接成一个向量。理论上,每个头都会学到不同的东西,从而位编码器模型提供更多的表达能力。
多头注意力是一个模块,用于计算输入的注意力权重,并生成一个带有编码信息的输出向量,指示序列中的每个词如何关注其他所有词。
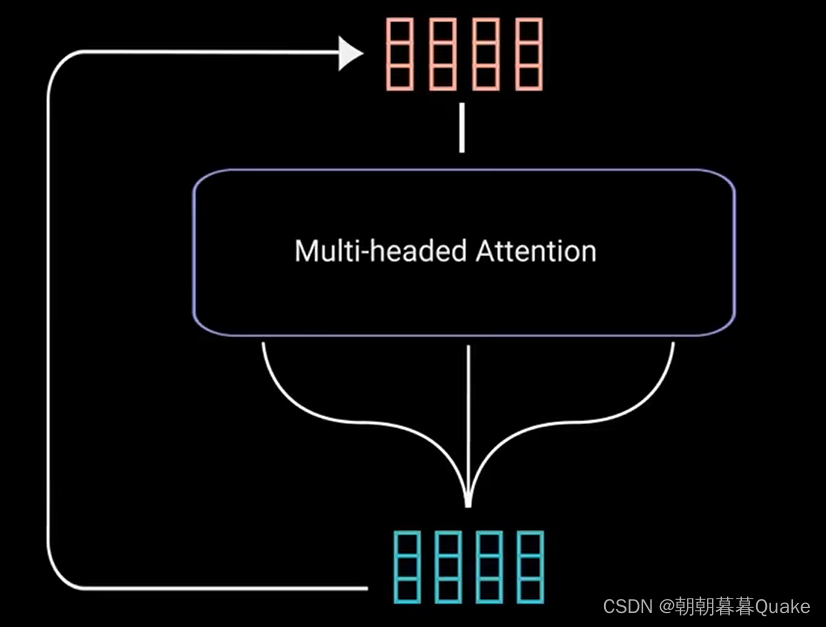
接下来,将多头注意力输出向量加到原始输入上。这叫做残差连接,残差连接的输出经过层归一化。

归一化后的残差输出被送入点对点前馈网络进行进一步处理。点对点前馈网络是几个线性层,中间有ReLu激活函数。再次将该输出与点对点前馈网络的输入相加并进一步归一化。残差连接有助于网络训练,因为它允许梯度直接流过网络。使用层归一化来稳定网络,从而显著减少所需的训练时间。点对点前馈层用于进一步处理注意力输出,可能使其具有更丰富的表达。
编码层的所有操作都是为了将输入编码为连续表示,带有注意力信息。这将帮助解码器在解码过程中关注输入中的适当词汇。
可以将编码器堆叠n次以进一步编码信息,其中每一次都有机会学习不同的注意力表示,从而有可能提高Transformer网络的预测能力。
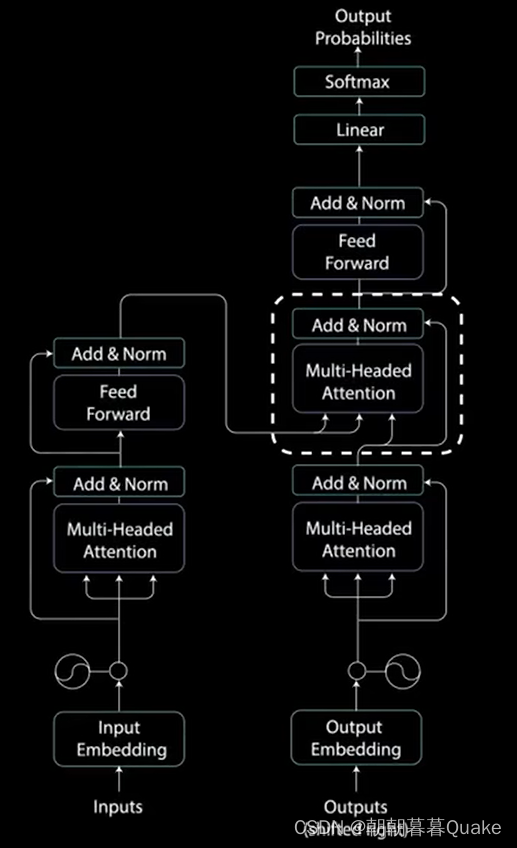
解码器的任务是生成文本序列。解码器具有与编码器相似的子层。
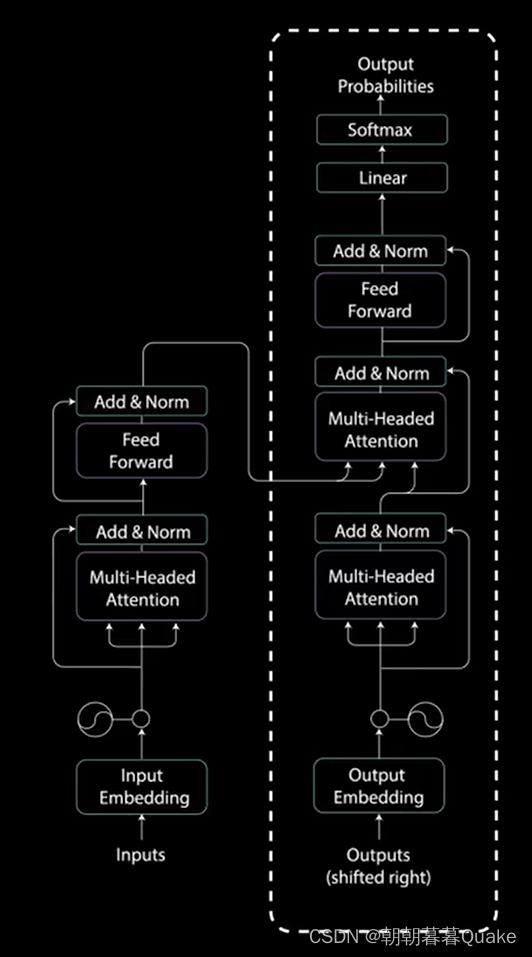
这些子层的行为类似于编码器中的层,但每个多头注意力层的任务不同。最后,它由一个类似于分类器的线性层和一个softmax来得到单词概率。解码器是自回归的,它将先前输出的列表作为输入,以及包含来自输入的注意力信息的编码器输出。当解码器生成一个结束标记作为输出时,解码停止。

输入通过嵌入层和位置编码层,得到位置嵌入。位置嵌入被送入第一个多头注意力层,计算编码器输入的注意力得分。这个多头注意力层的方式稍有不同。因为解码器是自回归的,并且逐词生成序列,你需要防止它对未来的标记进行条件处理。例如,在计算单词“am”的注意力得分时,不应该方为单词“find”,因为那个词实在之后生成的未来词。

单词“am”应该只访问它自己和它之前的单词,对于所有其他单词,它们只能关注之前的单词。我们需要一种方式来组织计算未来单词的注意力得分。这种方法称为mask。

一旦对mask得分进行softmax计算,负无穷大值就会变为0,从而为未来的标记留下零注意力得分。
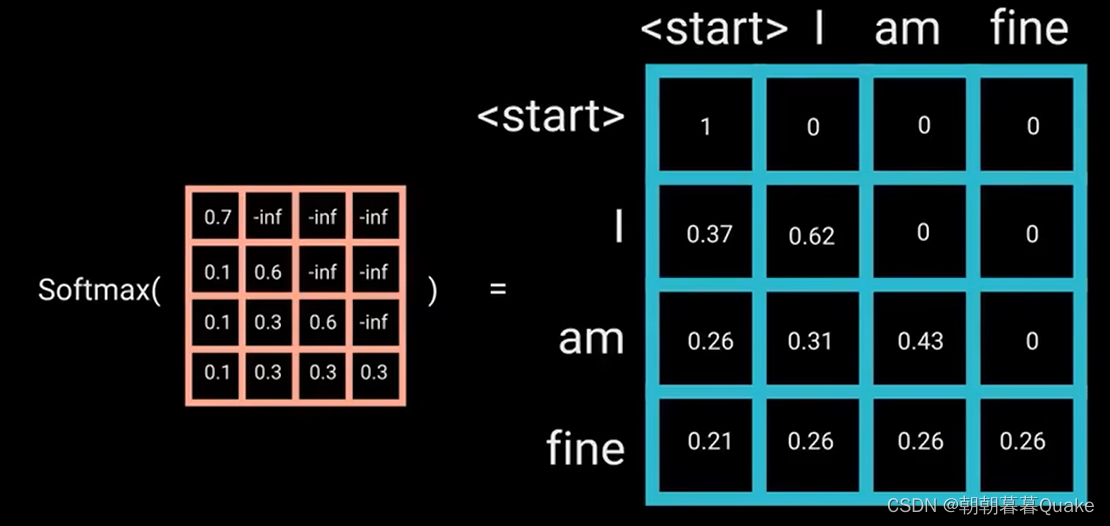
“am”对它之后的单词得分为0,这实际上是告诉模型不要关注这些单词。
这种mask是第一个多头注意力层计算注意力得分的唯一不同之处。这一层仍然有多个头,mask在被拼接并通过线性层进一步处理之前被应用到每个头上。
第一个多头注意力的输出是一个带有掩码的输出向量,其中包含有关模型如何关注解码器输入的信息。
对于这一层,编码器的输出是查询和键,而第一个多头注意力层的输出是值。这个过程将编码器输入与解码器输入进行匹配,允许解码器决定哪个编码器输入是相关的焦点。
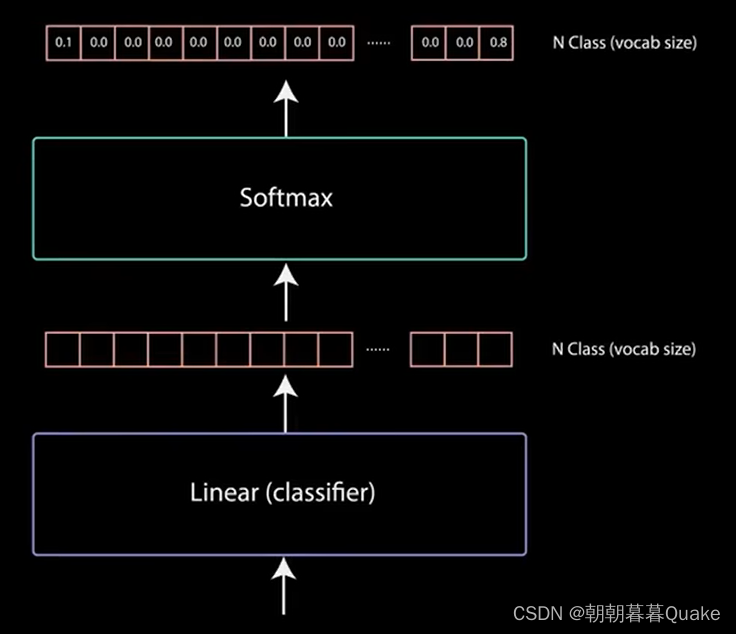
第二个多头注意力层的输出通过一个点对点前馈层进行进一步处理。最后一个点对点前馈层的输出经过一个最后的线性层,该层充当分类器,分类器的大小与所拥有的类别数相同。softmax为每个类别生成0到1之间的概率得分。我们取概率得分最高的索引,等于我们预测的单词。然后,解码器将输出添加到解码器输入列表中,并继续解码,知道预测出解码标记。
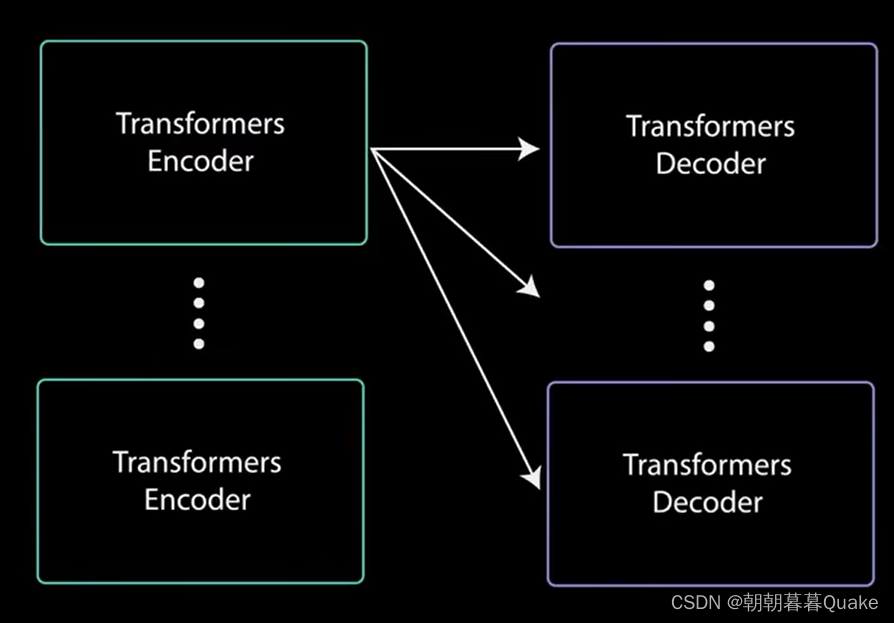
解码器可以堆叠n层高,每层从编码器和其前面的层中获取输入。通过堆叠层,模型可以学会从注意力头中提取并关注不同的注意力组合,从而有可能提高预测能力。















 1168
1168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









