







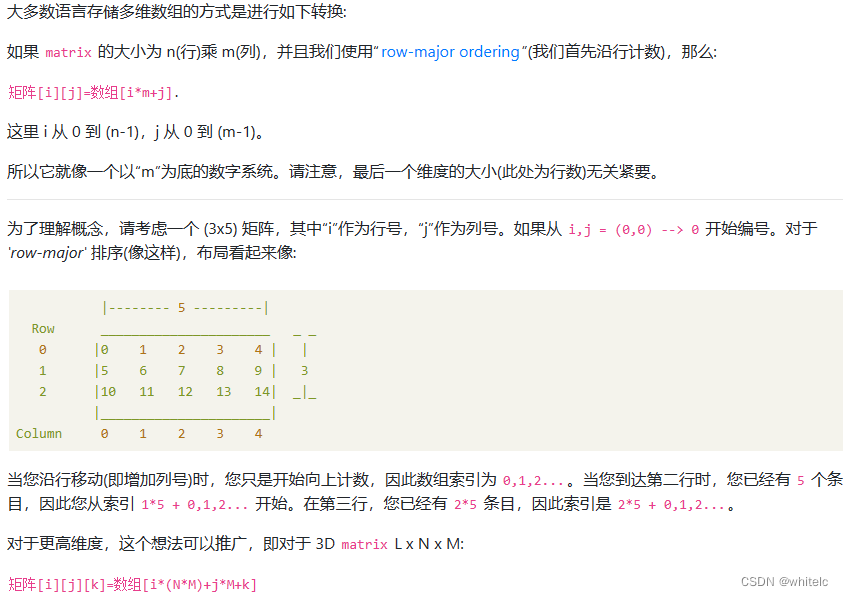
https://www.coder.work/article/30133
shared memory只能在block内共享,之间无法互相通信
对于2D TM波动方程计算,我们可以使用以下策略来处理共享内存的边界:
将全局内存中的数据复制到共享内存中时,除了将每个线程需要的数据复制到共享内存中之外,还需要将共享内存中的边界区域额外复制一些数据,使得每个线程都可以访问到它所需要的边界数据。
在每个线程访问共享内存中的数据时,需要注意边界情况。对于位于共享内存边界的线程,需要从全局内存中读取数据,而不是从共享内存中读取。
为了保证线程之间的通信正确,需要使用 __syncthreads() 函数进行同步。在每个线程读取共享内存中的数据之前,需要先等待其他线程将它们所需要的数据复制到共享内存中。
总体来说,处理共享内存边界需要在程序中额外考虑一些边界情况,并且需要使用同步函数来保证线程之间的通信正确。
#define BLOCK_SIZE_X 32
#define BLOCK_SIZE_Y 32
#define HALO_SIZE 1 // 外壳大小
__global__ void calcEz(float* ezf, float* ezfm1, float* hxfm1, float* hyfm1, int width, int height, int t, float dl, float dt, float a, float b)
{
int tx = threadIdx.x;
int ty = threadIdx.y;
int thx = blockIdx.x * blockDim.x + tx;
int thy = blockIdx.y * blockDim.y + ty;
// 计算当前线程处理的单元格的索引
int idx = thy * width + thx;
// 使用共享内存
__shared__ float hx[BLOCK_SIZE_X + HALO_SIZE * 2][BLOCK_SIZE_Y + HALO_SIZE * 2];
__shared__ float hy[BLOCK_SIZE_X + HALO_SIZE * 2][BLOCK_SIZE_Y + HALO_SIZE * 2];
// 将数据从全局内存拷贝到共享内存中
hx[tx + HALO_SIZE][ty + HALO_SIZE] = hxfm1[idx];
// 处理共享内存的边界
if (tx < HALO_SIZE) {
hx[tx][ty + HALO_SIZE] = hxfm1[idx - HALO_SIZE];
}
///这里没放全
__syncthreads();
// 计算Ez
if (thx >= HALO_SIZE && thy >= HALO_SIZE && thx < width - HALO_SIZE && thy < height - HALO_SIZE) {
if (thx == s_x && thy == s_y) {
// Source
float frq = 1.5e13;
ezf[idx] = sin(t * dt * 2 * PI * frq);
} else {
// Recursion
ezf[idx] = a * ezfm1[idx] + b * ((hy[tx + HALO_SIZE][ty + HALO_SIZE] - hy[tx + HALO_SIZE - 1][ty + HALO_SIZE]) / dl
在这个例子中,我们假设要对一个大小为1024x1024的二维数组进行FDTD TM模拟,使用一个大小为32x32的二维共享内存来存储每个块所需要处理的Ez场量数据。我们需要在kernel函数内部计算出当前线程所处理的元素在全局内存中的索引,并将其复制到共享内存中。
在计算Ez场量的更新值时,我们需要访问周围的Hx场量和Hy场量数据,这些数据在共享内存中并不一定存在,因此需要从全局内存中重新读取。由于这里每个线程只需要读取一次,因此对全局内存的访问不会带来太大的性能开销。
最后,我们将计算得到的Ez场量更新值写回到全局内存中
在这个CUDA kernel中,每个线程块都在处理矩形区域内的一部分计算任务。线程块内使用共享内存来共享数据,以避免在计算任务之间频繁地访问全局内存。在共享内存中,线程块需要存储其负责计算区域周围一圈的值,以便能够处理边界处的计算。为了实现这一点,代码复制了最外围一圈的值(也称为“halo”值),并将其存储在共享内存中的适当位置。
在 if (tx == 0 && thx != 0) 语句中,如果线程是该线程块内第一列的线程,但它不是该计算区域的最左边的一列,那么它需要访问其相邻线程块中的值。为此,代码复制了该线程块周围一圈中相邻线程块的值,并将其存储在共享内存中的适当位置(即 hy[0][ty+1])。
同样的,如果线程是该线程块内第一行的线程,但它不是该计算区域的最上面一行,那么它需要访问其相邻线程块中的值。为此,代码复制了该线程块周围一圈中相邻线程块的值,并将其存储在共享内存中的适当位置(即 hx[tx+1][0])。
通过这种方式,线程块内的所有线程都可以访问其计算区域周围一圈的值,无论它们在该线程块内的位置如何。这有助于确保算法正确处理边界情况。
下面是检查内存合并的代码
#include <stdio.h>
#include <malloc.h>
#include <iostream>
#include <stdlib.h>
#include <time.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
//typedef struct dim3_t {
// int x;
// int y;
//} dim3;
// KERNEL LAUNCH PARAMETERS
#define GRIDDIMX 4
#define GRIDDIMY 4
#define BLOCKDIMX 16
#define BLOCKDIMY 16
// ARCHITECTURE DEPENDENT
// number of threads aggregated for coalescing
#define COALESCINGWIDTH 32
// number of bytes in one coalesced transaction
#define CACHEBLOCKSIZE 128
#define CACHE_BLOCK_ADDR(addr,size) (addr*size)&(~(CACHEBLOCKSIZE-1))
int main() {
// fixed dim3 variables
// grid and block size
dim3 blockDim, gridDim;
blockDim.x = BLOCKDIMX;
blockDim.y = BLOCKDIMY;
gridDim.x = GRIDDIMX;
gridDim.y = GRIDDIMY;
// counters
int unq_accesses = 0;
int* unq_addr = (int*)malloc(sizeof(int) * COALESCINGWIDTH);
int total_unq_accesses = 0;
// iter over total number of threads
// iter超过线程总数,并计算内存请求数(合并请求)
int I, II, III;
for (I = 0; I < GRIDDIMX * GRIDDIMY; I++) {
dim3 blockIdx;
blockIdx.x = I % GRIDDIMX;
blockIdx.y = I / GRIDDIMX;
for (II = 0; II < BLOCKDIMX * BLOCKDIMY; II++) {
if (II % COALESCINGWIDTH == 0) {
// 新的合并束
total_unq_accesses += unq_accesses;
unq_accesses = 0;
}
dim3 threadIdx;
threadIdx.x = II % BLOCKDIMX;
threadIdx.y = II / BLOCKDIMX;
// 更改此部分以评估不同的访问 //
// do your indexing here
#define BLOCK_SIZE_X BLOCKDIMX
#define BLOCK_SIZE_Y BLOCKDIMY
#define xdim 32
int i = threadIdx.x;
int j = threadIdx.y;
int idx = blockIdx.x * BLOCK_SIZE_X + threadIdx.x;
int idy = blockIdx.y * BLOCK_SIZE_Y + threadIdx.y;
int index1 = j * BLOCK_SIZE_Y + i;
int i1 = (index1) % (BLOCK_SIZE_X + 1);
int j1 = (index1) / (BLOCK_SIZE_Y + 1);
int i2 = (BLOCK_SIZE_X * BLOCK_SIZE_Y + index1) % (BLOCK_SIZE_X + 1);
int j2 = (BLOCK_SIZE_X * BLOCK_SIZE_Y + index1) / (BLOCK_SIZE_Y + 1);
// 在此处计算访问位置和偏移量,将行"Ezx_h[(blockIdx.y*BLOCK_SIZE_Y+j1)*xdim+(blockIdx.x*BLOCK_SIZE_X+i1)];"更改为
int addr = (blockIdx.y * BLOCK_SIZE_Y + j1) * xdim + (blockIdx.x * BLOCK_SIZE_X + i1);
int size = sizeof(double);
//
//修改结束 //
//
printf("tid (%d,%d) from blockid (%d,%d) accessing to block %d\n", threadIdx.x, threadIdx.y, blockIdx.x, blockIdx.y, CACHE_BLOCK_ADDR(addr, size));
// 检查它是否可以与现有请求合并
short merged = 0;
for (III = 0; III < unq_accesses; III++) {
if (CACHE_BLOCK_ADDR(addr, size) == CACHE_BLOCK_ADDR(unq_addr[III], size)) {
merged = 1;
break;
}
}
if (!merged) {
// new cache block accessed over this coalescing width
unq_addr[unq_accesses] = CACHE_BLOCK_ADDR(addr, size);
unq_accesses++;
}
}
}
printf("%d threads make %d memory transactions\n", GRIDDIMX * GRIDDIMY * BLOCKDIMX * BLOCKDIMY, total_unq_accesses);
}
















 49
49











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









