







awk :“Aho Weiberger and Kernighan”三个作者的姓的第一个字母 :是一种处理文本文件的语言,是一个强大的文本分析工具。
awk是逐行处理,当awk处理一个文本时,会一行一行进行处理,处理完当前行,再处理下一行,awk默认以"换行符"为标记,识别每一行,,awk会按照用户指定的分割符去分割当前行,如果没有指定分割符,默认使用空格作为分隔符。
语法 :
awk 选项 '模式 {动作}' file参数 :
-F <分隔符> 或 --field-separator=<分隔符> : 指定输入字段的分隔符,默认是空格
-v <变量名>=<值> : 设置 awk 内部的变量值。可以使用该选项将外部值传递给 awk 脚本中的变量。
-f <脚本文件> : 指定一个包含 awk 脚本的文件。这样可以在文件中编写较大的 awk 脚本,然后通过 -f 选项将其加载。
内置变量 :
FS(Field Separator) :输入字段分隔符, 默认为空白字符
OFS(Out of Field Separator) :输出字段分隔符, 默认为空白字符
RS(Record Separator) :输入记录分隔符(输入换行符), 指定输入时的换行符
ORS(Output Record Separate) :输出记录分隔符(输出换行符),输出时用指定符号代替换行符
NF(Number for Field) :当前行的字段的个数(即当前行被分割成了几列):列数
NR(Number of Record) :行号,当前处理的文本行的行号。
FNR :各文件分别计数的行号
ARGC :命令行参数的个数
ARGV :数组,保存的是命令行所给定的各参数
示例 :
1.打印文件全部内容:
awk '{print}' /tmp/passwd
awk '{print $0}' /tmp/passwd
#或
cat /tmp/passwd |awk '{print}'
cat /tmp/passwd |awk '{print $0}'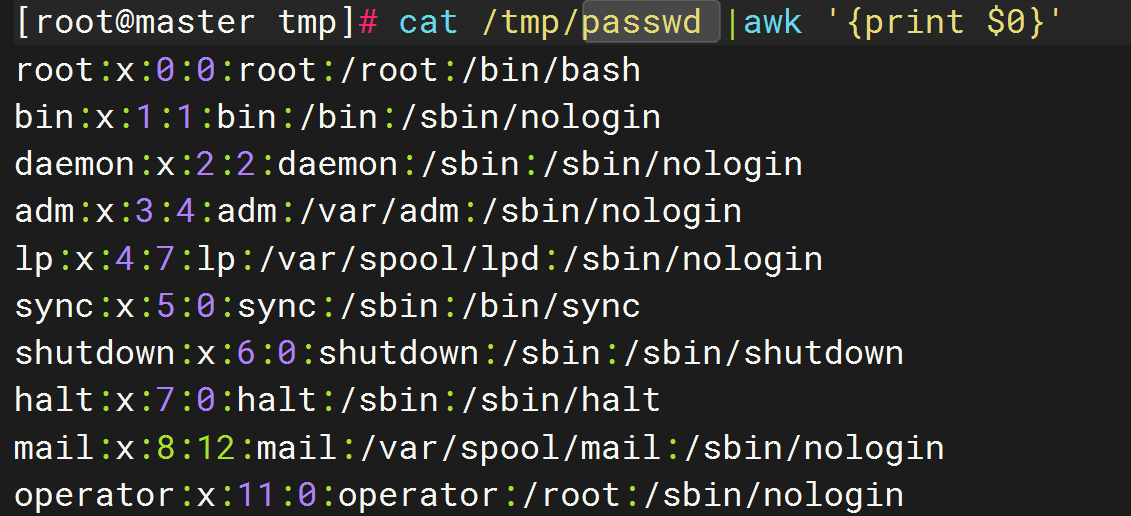
2.打印特定列
#默认空格分隔
awk '{print $1, $2}' /tmp/passwd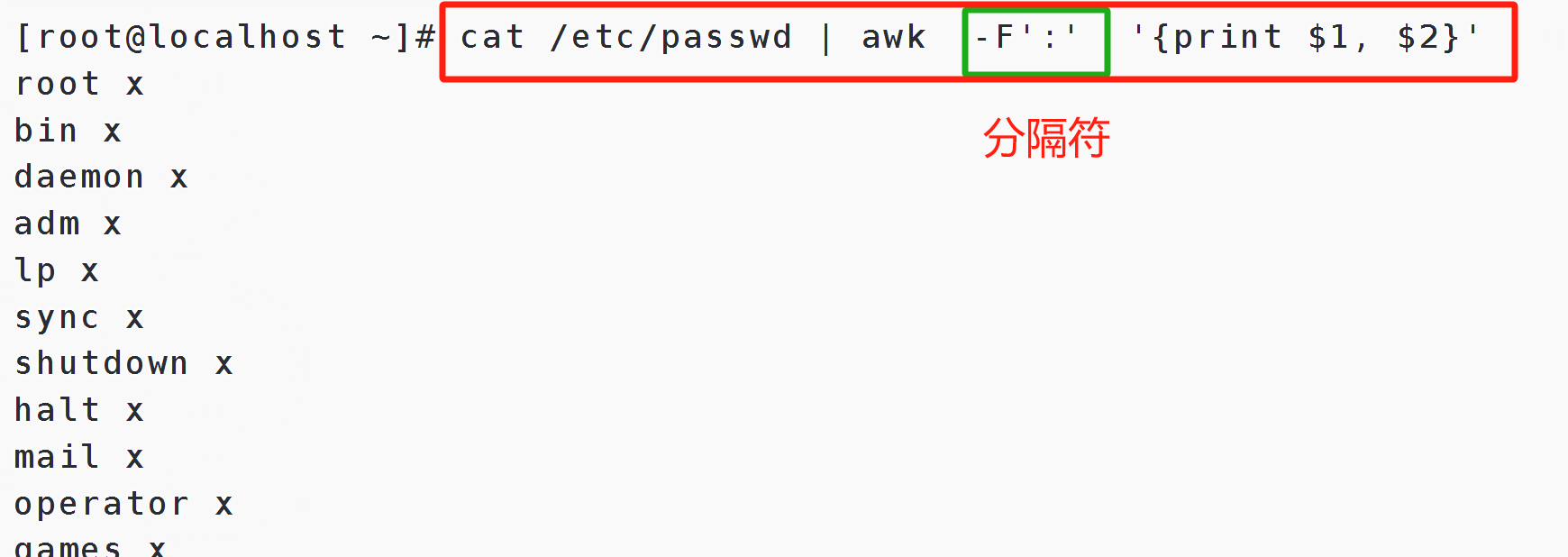
3.指定分隔符:-F
#以 :为分隔符,打印第一列,第二列
awk -F':' '{print $1, $2}' /tmp/passwd
cat /etc/passwd | awk -F':' '{print $1, $2}'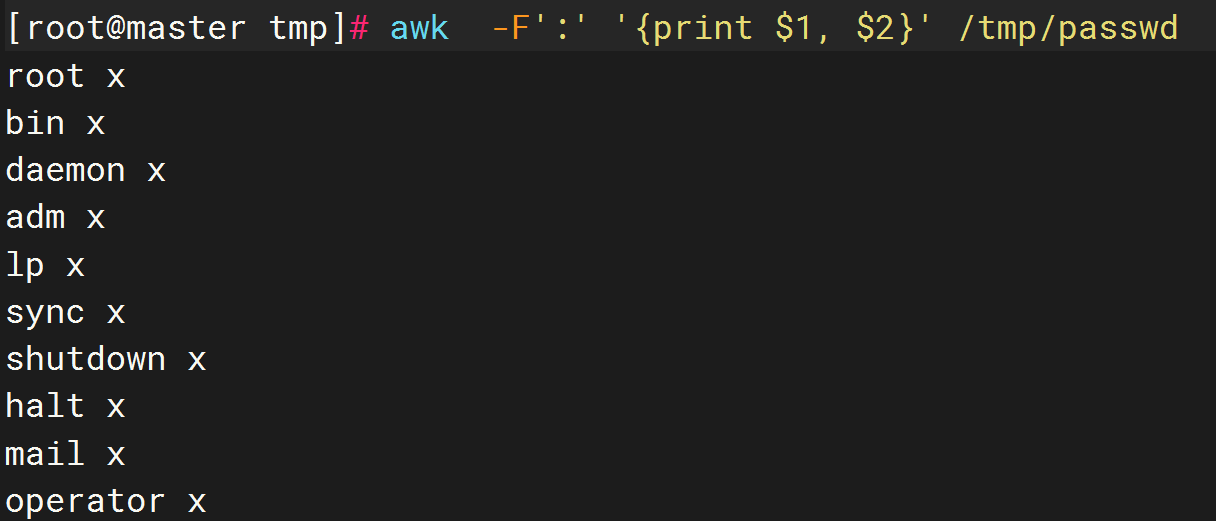
4.打印文档第几行第几列
awk 'NR==行数{print $列数}'
# 查看文件第1行:
cat /tmp/passwd |awk 'NR==1'
# 查看文件第2行第6列:以 :分割
cat /tmp/passwd |awk -F':' 'NR==2{print $6}'
free -m |awk 'NR==2{print $4}'
# 查看磁盘的使用率
df -Th | awk 'NR==6{print $6}' | awk -F"%" '{print $1}'
# 查看当前操作系统版本
cat /etc/redhat-release |awk '{print $4}' |awk -F"." '{print $1}'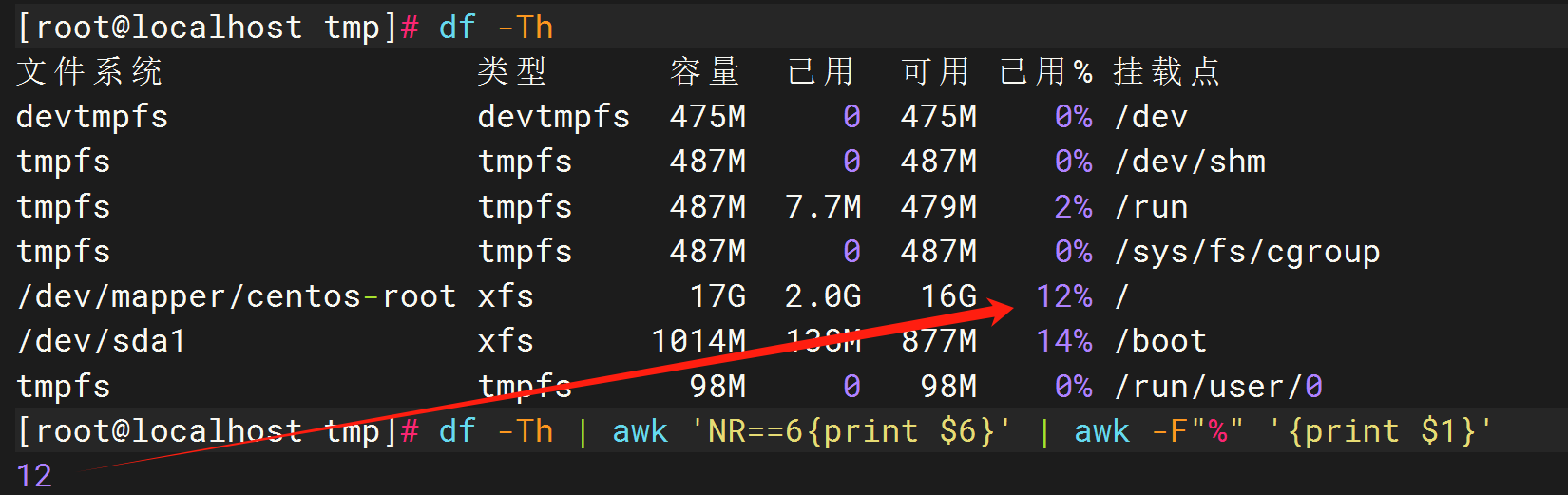
5.过滤 第一列大于2 的行:
#以 :为分隔符,打印第三列大于2的行
awk -F":" '$3>2' /tmp/passwd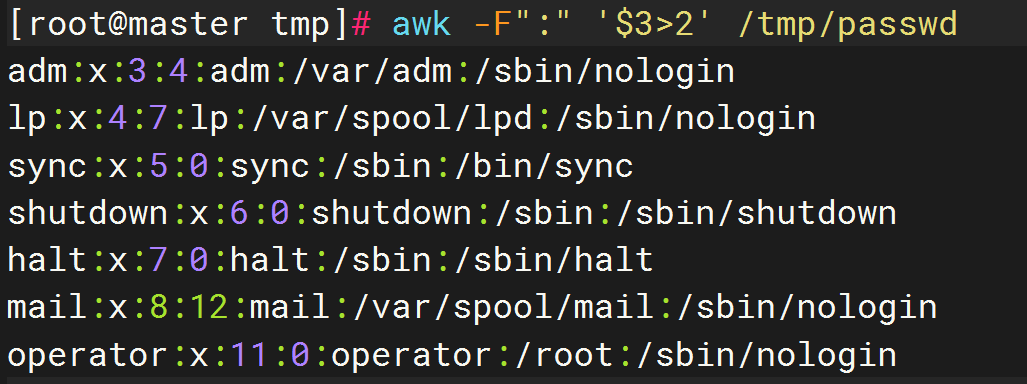
awk -F':' '$1<"d"' /etc/passwd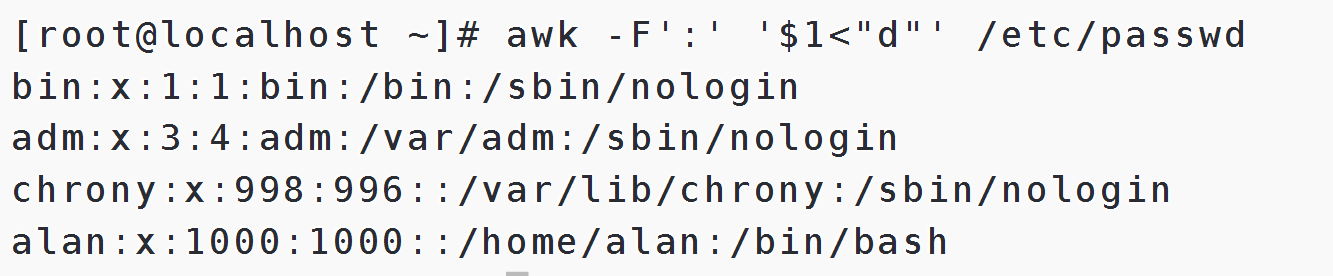
6. 过滤 第一列大于2 并且 第二列等于'Are' 的行 ,打印第1,2,3列
awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt7.NF:列数
# 打印列数
cat /tmp/passwd |awk -F":" '{print NF}'
# 打印最后一列内容
cat /tmp/passwd |awk -F":" '{print $NF}'
# 打印倒数第二列内容
cat /tmp/passwd |awk -F":" '{print $(NF-1)}'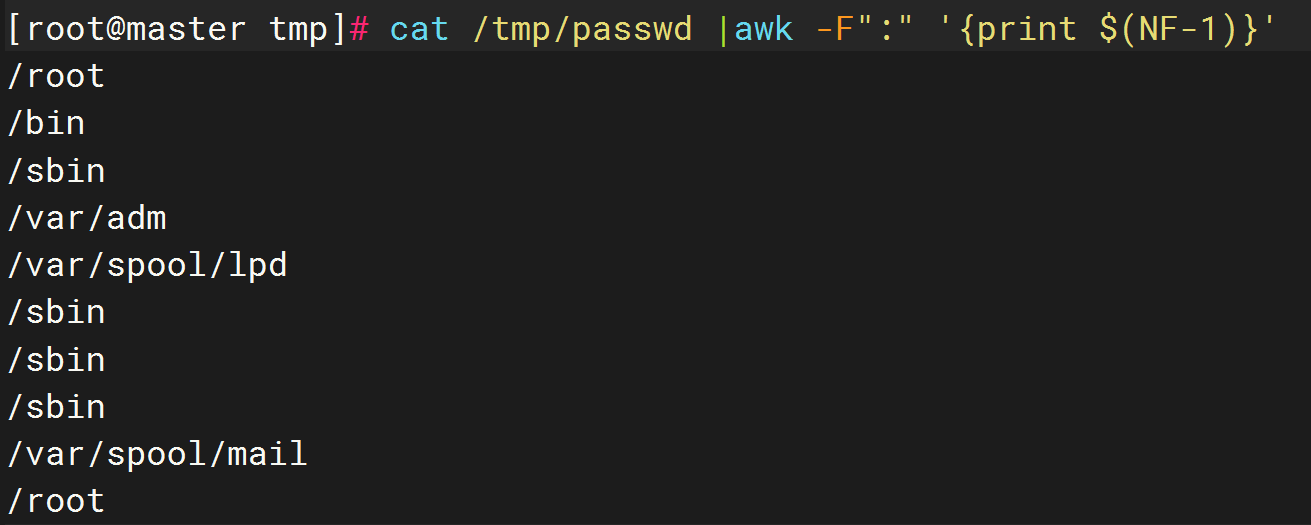
8.OFS:输出字段分隔符(了解):
由于awk默认是空格作为默认分割分隔符,在处理完成一个,字段和字段之间还是使用空格作为分割符。可通过awk的OFS变量在处理完成以后输出字段的分割符
# 打印第一列和第二列,用 %%% 做分隔符
cat /tmp/passwd | awk -F':' 'BEGIN{OFS="%%%"}{print $1, $2}'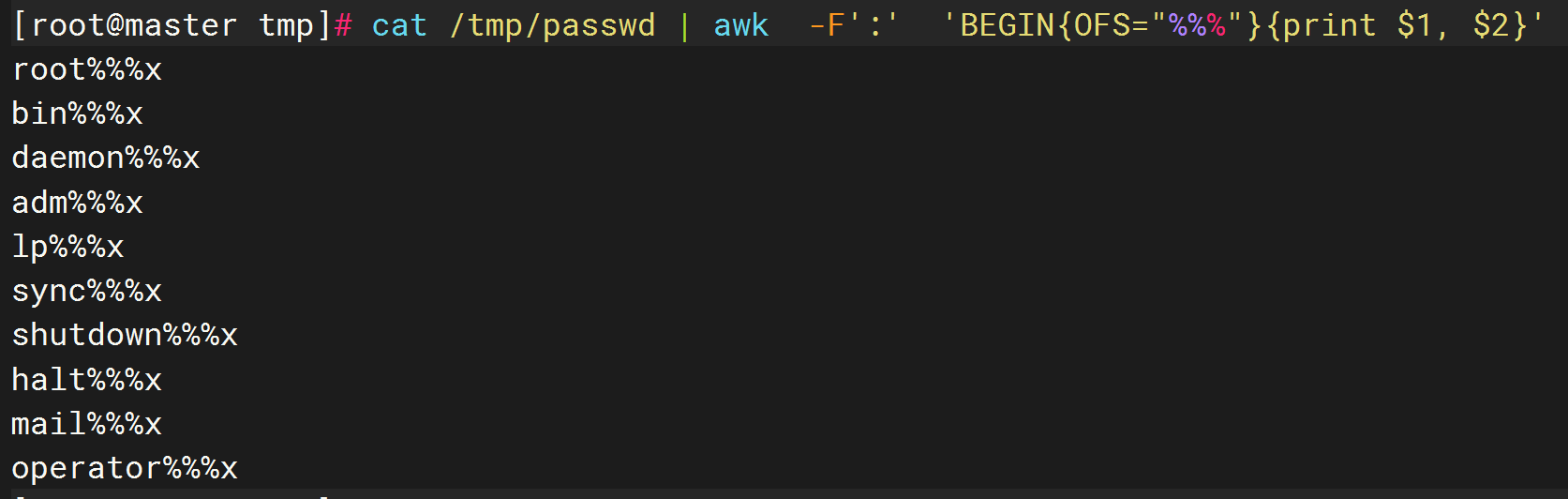
9.RS:输入记录(行)分隔符,默认换行符
- RS 变量在 awk 中用于定义记录分隔符。默认情况下,RS 是换行符,这意味着 awk 将每一行视为一个记录。但你可以通过设置 RS 来更改记录分隔符,从而根据不同的分隔符来处理文本。
# 打印第一列和第二列,用 :x: 做行分隔符
cat /tmp/passwd | awk -F':' 'BEGIN{RS=":x:"}{print $1, $2}'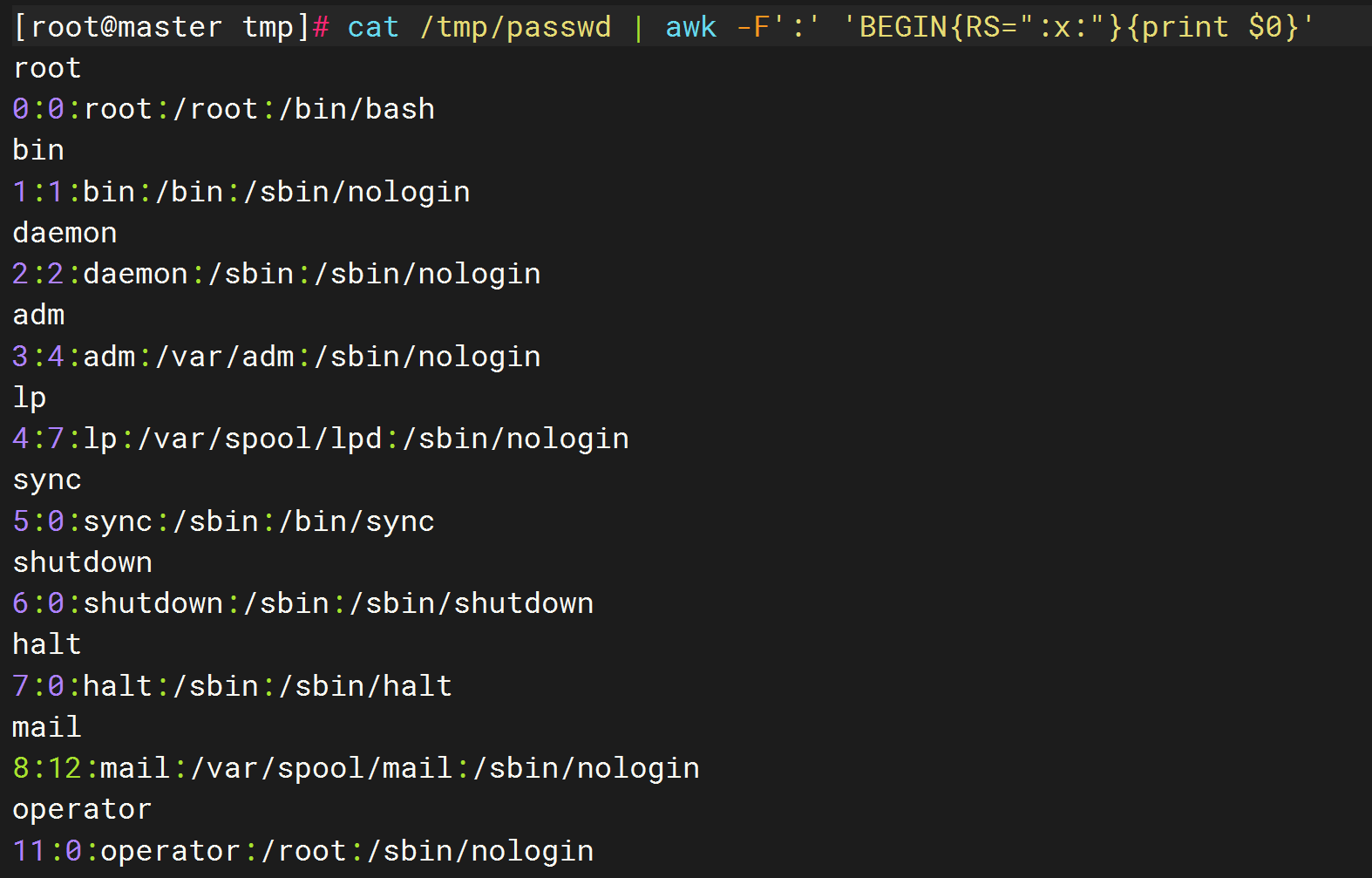
10.自定义字段:
awk -F":" '{print "姓名:"$1,"uid:"$3}' /tmp/passwd
11.BEGIN和END使用区别:
BEGIN{} :行处理前的动作
END{} : 行处理之后的动作\
awk 'BEGIN {print "用户名","uid"} {print $1,$3} END{print "结束语!"}' /tmp/passwd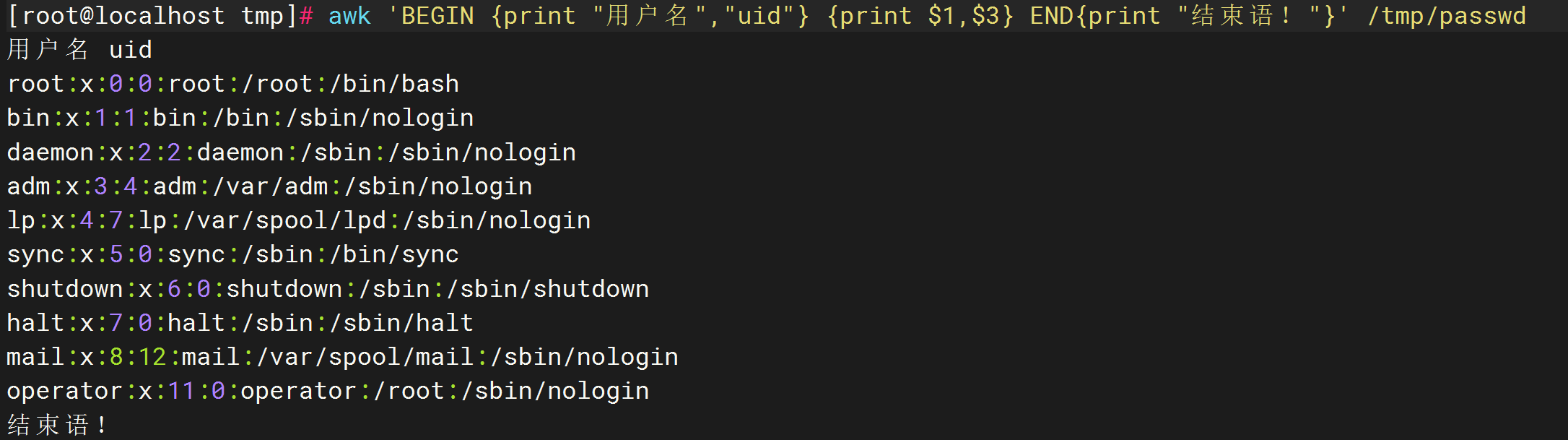
12.条件判断:
awk -F":" '{if($3==0) {i++} else if($3<1000) {j++} else{k++}} END{print"管理员:"i;print "系统用户:"j;print"普通用户:"k}' /etc/passwd
13.for循环:
awk -F":" 'NR==1{for(i=1;i<5;i++){print $1}}' /etc/passwd

















 1224
1224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









