







文章目录
主成成分分析pca
\qquad
非监督学习算法。
\qquad
通过正交变换将数据换到新坐标中,从而将原本可能相关的便便(特征)投影到线性无关的变量(特征)。如果变换后的维度小于变换前的维度,则实现降维。
为什么要对数据进行去中心化?
\qquad 中心化后,计算方差,协方差,协方差矩阵等运算更加方便。
为什么要保证投影方向方差最大?
\qquad
投影方差越大,意味着数据越分散,相对于原始数据来说,能够保留的信息越多。如果方差很小,则表示数据很大部分重叠,保留信息少。
\qquad
对于PCA来说,作为分类回归等任务的前置步骤(数据预处理阶段)。特征方差越大,说明样本之间区分越明显,这样就越容易完成分类或回归任务
为什么选择向量时,要与之前的向量正交?
\qquad
如果没有限制,则第一主成分和第二主成分相同,无意义。
\qquad
选择正交的基,是因为正交的基相关性为0。这样能够保留最大的信息。如果基之间是相关的,当样本数据向基向量投影时,也就一定相关,选在重叠。
为什么pca要选择单位向量?
\qquad
向单位向量上投影时,投影值计算更方便,向量内积即可。
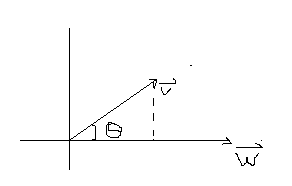
向量v在w上的投影为:pro=|v|
∗
*
∗cosθ
由:v
∗
*
∗w=|v|
∗
*
∗|w|
∗
*
∗cosθ
得到cosθ=
v
∗
w
∣
v
∣
∗
∣
w
∣
v*w\over |v|*|w|
∣v∣∗∣w∣v∗w
上式带入投影:pro=
v
∗
w
∣
w
∣
v*w\over |w|
∣w∣v∗w
如果w为单位向量,则投影为内积,直接点成就行。
步骤
\qquad 假设我们要将数据投影到k个坐标轴上,需要新基k个向量。步骤如下:
- 数据去中心化,使得每个维度为0
- 寻找一个单位向量 w 1 w_1 w1(坐标轴,第一主成分),使得数据在该方向上投影方差最大
- 寻找第二个单位向量 w 2 w_2 w2(第二主成分),使得 w 2 w_2 w2与之前找到的所有向量正交,并使改箱量上的投影次大。(次与 w 1 w_1 w1上的方差)
- 按上述方式在,依次找到 w 1 w_1 w1, w 2 w_2 w2… w k w_k wk。 w k w_k wk为第k主成分,样本数据在 w k w_k wk的投影方差第k大
- 将得到的单位向量 w 1 w_1 w1, w 2 w_2 w2… w k w_k wk。 w k w_k wk构成一个基。该基就是新的坐标系
- 将样本数据投影到该基上么就完成正交变换
推导
数据集(假定已经去中心化):X=(
x
1
x_1
x1,
x
2
x_2
x2…
x
m
x_m
xm)∈
R
n
×
m
{R^{n×m}}
Rn×m。n维m个
x
1
x_1
x1∈
R
n
×
1
{R^{n×1}}
Rn×1
待求:W=(
w
1
w_1
w1,
w
2
w_2
w2…
w
d
w_d
wd)∈
R
n
×
d
{R^{n×d}}
Rn×d。d为降维后维数
w
1
w_1
w1∈
R
n
×
1
{R^{n×1}}
Rn×1,w用原基表示,所以仍然是n维。
约束条件:
W
T
{W^T}
WTW=I(单位矩阵)∈
R
d
×
d
{R^{d×d}}
Rd×d
新基下的数据集:Z=(
z
1
z_1
z1,
z
2
z_2
z2…
z
m
z_m
zm)∈
R
d
×
m
{R^{d×m}}
Rd×m。d维m个
\qquad
z
1
T
z_1^T
z1T={
z
11
z_{11}
z11,
z
12
z_{12}
z12…
z
1
d
z_{1d}
z1d}
\qquad\;\;\;\;
={
w
1
T
w_1^T
w1T
x
1
x_1
x1,
w
2
T
w_2^T
w2T
x
1
x_1
x1…
w
d
T
w_d^T
wdT
x
1
x_1
x1}
z
i
j
z_{ij}
zij=
w
j
T
w_j^T
wjT
x
i
x_i
xi
z
i
z_{i}
zi=
W
T
W^T
WT
x
i
x_i
xi
最小重构误差角度
\qquad
重构
x
i
x_i
xi:新基的各个方向拉长相应投影倍,再全部加和。(向量相加)
\qquad
则重构的
x
i
x_i
xi可表示为:
∑
j
=
1
d
\sum_{j=1}^{d}
∑j=1d
z
i
j
z_{ij}
zij
w
j
w_j
wj=W
z
i
z_{i}
zi
\qquad
重构后误差最小,得到目标函数:
\qquad
\qquad
a
r
g
m
i
n
w
argmin_w
argminw
\;\;\;
∑
i
=
1
m
\sum_{i=1}^{m}
∑i=1m||
x
i
x_i
xi-
∑
j
=
1
d
\sum_{j=1}^{d}
∑j=1d
z
i
j
z_{ij}
zij
w
j
w_j
wj
∣
∣
2
||^2
∣∣2
\qquad
\qquad
\qquad
\qquad
=
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d(
x
i
x_i
xi-W
z
i
z_{i}
zi
)
T
)^T
)T(
x
i
x_i
xi-W
z
i
z_{i}
zi)
\qquad
\qquad
\qquad
\qquad
=
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d[
x
i
T
x_i^T
xiT
x
i
x_i
xi-
x
i
T
x_i^T
xiTW
z
i
z_{i}
zi-
z
i
T
z_i^T
ziT
W
T
W^T
WT
x
i
x_{i}
xi+
z
i
T
z_i^T
ziT
W
T
W^T
WTW
z
i
z_{i}
zi]
\qquad
\qquad
\qquad
\qquad
=
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d[
x
i
T
x_i^T
xiT
x
i
x_i
xi-2
z
i
T
z_i^T
ziT
W
T
W^T
WT
x
i
x_{i}
xi+
z
i
T
z_i^T
ziT
z
i
z_{i}
zi]
\qquad
\qquad
\qquad
\qquad
=
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d[
x
i
T
x_i^T
xiT
x
i
x_i
xi-2
z
i
T
z_i^T
ziT
z
i
z_{i}
zi+
z
i
T
z_i^T
ziT
z
i
z_{i}
zi]
\qquad
\qquad
\qquad
\qquad
=
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d[-
z
i
T
z_i^T
ziT
z
i
z_{i}
zi+
x
i
T
x_i^T
xiT
x
i
x_i
xi]
notes:
\qquad
x
i
T
x_i^T
xiTW
z
i
z_{i}
zi以及
z
i
T
z_i^T
ziT
W
T
W^T
WT
x
i
x_{i}
xi互为转置,且都是一个数,可以合并
\qquad
\qquad
约束条件:
W
T
{W^T}
WTW=I(单位矩阵)∈
R
d
×
d
{R^{d×d}}
Rd×d
\qquad
\qquad
x
i
T
x_i^T
xiT
x
i
x_i
xi为原始数据方差,是一个常数,可省略
此时目标函数可优化为:
\qquad
\qquad
a
r
g
m
i
n
w
argmin_w
argminw
\;\;\;
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d-
z
i
T
z_i^T
ziT
z
i
z_{i}
zi
\qquad
\qquad
\qquad
\qquad
=-
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d
z
i
T
z_i^T
ziT
z
i
z_{i}
zi
\qquad
\qquad
\qquad
\qquad
=-
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1dtr(
z
i
z_{i}
zi
z
i
T
z_i^T
ziT)
\qquad
\qquad
\qquad
\qquad
=-
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1dtr(
W
T
W^T
WT
x
i
x_i
xi
x
i
T
x_i^T
xiT
W
W
W)
\qquad
\qquad
\qquad
\qquad
=-tr(
W
T
W^T
WT
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d
x
i
x_i
xi
x
i
T
x_i^T
xiT
W
W
W)
令C=
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d
x
i
x_i
xi
x
i
T
x_i^T
xiT=X
X
T
X^T
XT(为散度矩阵,再除以个数减一就是协方差矩阵)
\qquad
\qquad
\qquad
\qquad
=-tr(
W
T
W^T
WTC
W
W
W)
\qquad
\qquad
\qquad
(1)
s.t.
W
T
{W^T}
WTW=I
由拉格朗日乘数法得到:
\qquad
L(W,∧)=-tr(
W
T
W^T
WTC
W
W
W)+tr(∧(
W
T
{W^T}
WTW-I))
∧=diag(
λ
1
λ_1
λ1,
λ
2
λ_2
λ2,…,
λ
d
λ_d
λd)
L对W求导,并令结果为0,得到:矩阵求导
\qquad
\qquad
\qquad
\qquad
(C+
C
T
C^T
CT)W=2W∧
\qquad
\qquad
\qquad
\qquad
\qquad
CW=W∧
\qquad
\qquad
\qquad
(2)
对任意
λ
i
λ_i
λi都有:
\qquad
\qquad
\qquad
\qquad
C
w
i
w_i
wi=
λ
i
λ_i
λi
w
i
w_i
wi
即
λ
i
λ_i
λi为C的特征值,
w
i
w_i
wi为对应的特征向量。
(2)带入(1)得到:
\qquad
\qquad
\qquad
a
r
g
m
i
n
w
argmin_w
argminw
\;\;\;
-tr(
W
T
W^T
WTC
W
W
W)
\qquad
\qquad
\qquad
=-tr(
W
T
W^T
WT
W
W
W∧)
\qquad
\qquad
\qquad
=-tr(∧)
最小的重构误差==对角矩阵的迹和的最大值
W就位最大的d个特征值对应的特征向量
最大方差角度
投影后数据方差最大
\qquad
\qquad
a
r
g
m
a
x
w
argmax_w
argmaxw
\;\;\;
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d(
z
i
z_i
zi
)
2
)^2
)2
\qquad
\qquad
\qquad
\qquad
=
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d
z
i
T
z_i^T
ziT
z
i
z_{i}
zi
\qquad
\qquad
\qquad
\qquad
=
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1dtr(
z
i
z_{i}
zi
z
i
T
z_i^T
ziT)
\qquad
\qquad
\qquad
\qquad
=
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1dtr(
W
T
W^T
WT
x
i
x_i
xi
x
i
T
x_i^T
xiT
W
W
W)
\qquad
\qquad
\qquad
\qquad
=tr(
W
T
W^T
WTC
W
W
W)
即求最大的迹,最大的d个特征值。与最小重构相同了
手动实现
步骤
- 对样本数据进行中心化
- 求散度矩阵X X T X^T XT
- 求X X T X^T XT的特征值以及特征向量
- 选取最大的d个特征值对应的特征向量组成W=( w 1 w_1 w1, w 2 w_2 w2… w d w_d wd)
- 降维后数据Z= W T W^T WTX
iris代码
单步
数据集是m×n,为推到中的数据集的转置
import numpy as np
import matplotlib.pyplot as plt
#载入鸢尾花数据集
from sklearn import datasets
iris=datasets.load_iris()
x=iris.data
y=iris.target
#第一步,去中心化
#按列求和
x_sum=np.sum(x,axis=0)
x_mean=x_sum/x.shape[0]
x=x-x_mean
#x=x-x.mean(axis=0)
print(x)
#求C=x^TX
c=np.dot(x.T,x)
print(c)

#求特征值以及特征向量
val,vector=np.linalg.eig(c)
print(val)
print(vector)
#对特征值进行排序,index保存索引
index=np.argsort(-val)
print(index)
#print(index[:2])
#投影矩阵 -为最大的特征值对应特征向量,即index对应索引对应的列。降到2维
A=vector[:,index[:2]]
print(A)
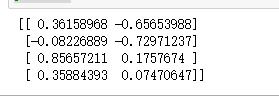
#投影后矩阵
Y=np.dot(x,A)
print(Y)
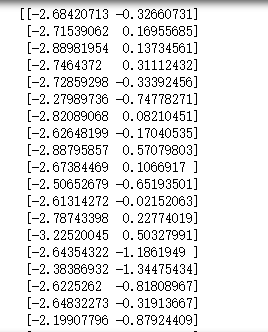
#画图
for i in range(len(y)):
if y[i]==0:
plt.scatter(Y[i][0],Y[i][1],c='r',marker='.')
elif y[i]==1:
plt.scatter(Y[i][0],Y[i][1],c='b',marker='.')
else:
plt.scatter(Y[i][0],Y[i][1],c='g',marker='.')
plt.show()
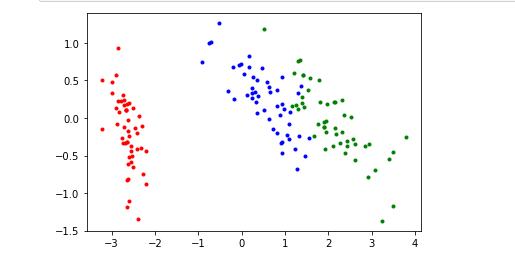
这个图和网上的第二主成分和网上的图相反。但是没关系,是第二主成分方向反了的问题,并不影响。在Y[i][1]前面加负号就得到了网上的图
#画图
for i in range(len(y)):
if y[i]==0:
plt.scatter(Y[i][0],-Y[i][1],c='r',marker='.')
elif y[i]==1:
plt.scatter(Y[i][0],-Y[i][1],c='b',marker='.')
else:
plt.scatter(Y[i][0],-Y[i][1],c='g',marker='.')
plt.show()
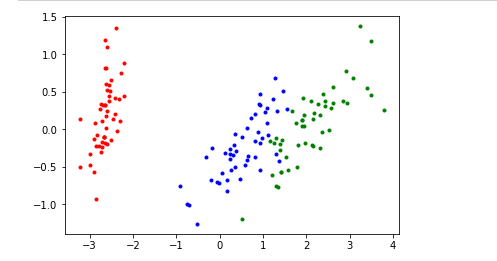
函数
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
#x:一个数据为一行
def PCA_fit(d_dim,x):
#去中心化
x=x-x.mean(axis=0)
#求C
C=np.dot(x.T,x)
#求特征值以及特征向量
val,vector=np.linalg.eig(C)
#求排序索引
index=np.argsort(-val)
#投影矩阵
A=vector[:,index[:d_dim]]
#返回降维后的数据
return np.dot(x,A)
iris=datasets.load_iris()
x=iris.data
y=iris.target
#降维后数据Y,调用函数
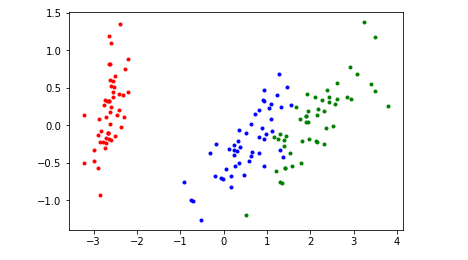
Y=PCA_fit(2,x)
#画图
for i in range(len(y)):
if y[i]==0:
plt.scatter(Y[i][0],-Y[i][1],c='r',marker='.')
elif y[i]==1:
plt.scatter(Y[i][0],-Y[i][1],c='b',marker='.')
else:
plt.scatter(Y[i][0],-Y[i][1],c='g',marker='.')
plt.show()
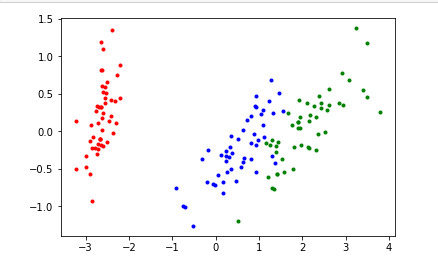
class PCA():
def __init__(self,n_components):
self.n_components=n_components
def fit_transform(self,X):
#去中心化
X=X-X.mean(axis=0)
#求协方差矩阵
self.covariance=np.dot(X.T,X)/X.shape[0]
#求特征值以及特征向量
val,vector=np.linalg.eig(self.covariance)
#求排序索引
index=np.argsort(-val)
#投影矩阵 ,降维矩阵
self.components_=vector[:,index[:self.n_components]]
#返回降维后的数据
return np.dot(x,self.components_)
iris=datasets.load_iris()
x=iris.data
y=iris.target
#降维后数据Y,调用函数
pca=PCA(n_components=2)
Y=pca.fit_transform(x)
#画图
for i in range(len(y)):
if y[i]==0:
plt.scatter(Y[i][0],-Y[i][1],c='r',marker='.')
elif y[i]==1:
plt.scatter(Y[i][0],-Y[i][1],c='b',marker='.')
else:
plt.sca
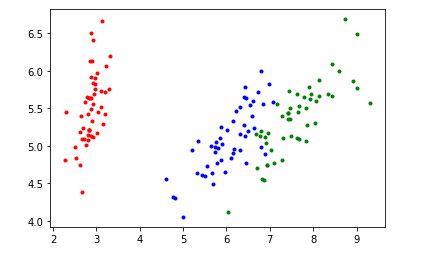
sklearn
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import PCA
iris=datasets.load_iris()
x=iris.data
y=iris.target
pca=PCA(n_components=2)#降到二维
pca.fit(x)
Y=pca.fit_transform(x)#降维后数据
#画图
for i in range(len(y)):
if y[i]==0:
plt.scatter(Y[i][0],Y[i][1],c='r',marker='.')
elif y[i]==1:
plt.scatter(Y[i][0],Y[i][1],c='b',marker='.')
else:
plt.scatter(Y[i][0],Y[i][1],c='g',marker='.')
plt.show()
优缺点
优点
减少特征空间维度,降低了数据复杂度
方便模型拟合
缺点
计算成本高
可能会降低模型精度,因为会丢弃一些信息
转换过程复杂,结果难以解释
对异常值敏感
















 1555
1555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











