






目录
AttributeError: 'Tensor' object has no attribute 'numpy'
Tensorlow 中的常量值函数:tf.zeros()、tf.ones()、tf.fill()和tf.constant()
任务
- 继续进行多线学习。李沐和B站的豆豆的课(每周一节),河北工业大学刘老师的课。动手学的学习可能这次的学习可能不会特别重点的看了。因为其他两门课已经覆盖了其大部分内容。至于周志华的西瓜书,我想等到自己论文答辩完,不是很忙的时候学习。
- 多看和记一下python的一些重要函数和语法
- 华为云的直播有一些活动和课,最近看到的,抽空看看。
- 接下来的两周还有两次机器学习的代码实践课,多学学机器学习的思想和敲python代码的熟练度。
- 开始学一些简单公式的输入,对现在来说方便自己笔记的整理,对以后来说可能对论文的写作有帮助。
老师给我的动手学的链接是mxnet,而没有tensorflow版的,在b站李沐的视频的链接找到了tf的链接,思想是一样的,只是实现的代码方式可能不一样
本次的学习,还是不断地试错,自己百度找解决办法,由于6月6号进行论文答辩,最近的学习进度还是偏慢,学习的时间受到影响,但是每天都会争取看一点书,想想算法的实现。
由于接近6月份了,要进行本科论文答辩等,由于要去青岛答辩而不是在学校,可能学习的时间会更加紧一点,而我这次的学习计划,还是想多学一点,少整理一些东西。可能学到的知识只会做一些总结,而不是仅把所有的知识列出来。
visdom可视化工具
动手学第三章的学习链接:https://zh.d2l.ai/chapter_deep-learning-basics/linear-regression.html
python基础知识
记录自己感觉重要和刚接触不同于java的一些东西,为了考研,有一年多没碰电脑,感觉还是忘掉的东西比较多,索引是从0开始!!所以我简单的整理了python的一些知识,感觉都写在这里篇幅可能要蛮多,所以专门整了个博客,也方便自己日后系统整理自己所学知识。
https://blog.csdn.net/qq_43613688/article/details/116935204
数学公式的输入
刚开始输的是第一个图,感觉怪怪的,所以又开始改了下,这是别的大佬的博客,自己就不整理了,借鉴学习一下。
自己输公式遇到的问题,主要还是美观的问题。


tensorflow的安装
今天补李沐的视频的时候,发现B站的视频下面的链接教材貌似是新的教材,有tensorflow的代码,而老师给的只有mxnet的,所以今天就开始下tensorflow。但是下载过程一直出错,然后最后发现是网络的问题......浪费我4个小时,百度了无数办法,换了4个网络,用了镜像还是下载出错我就应该想到是网络问题。。。
网络真的不好的话,在这里面下载 https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/tensorflow/
 这个环境的python版本是3.6版本的,也就是下图的第一个。下成别的版本的会出错。所以下载tensorflow也应该是相应的版本。
这个环境的python版本是3.6版本的,也就是下图的第一个。下成别的版本的会出错。所以下载tensorflow也应该是相应的版本。

下载完以后把文件放到这个路径下,就是conda安装的路径下的要装的虚拟环境下的Scripts

在次路径输入cmd进入后,输入 pip install +文件名 ( 可以输入tensor+Tab会自动补全下载的文件名)


activate gluon
python
import tensorflow as tf来确定是否成功下载tensorflow
AttributeError: 'Tensor' object has no attribute 'numpy'
运行代码出错,然后百度,csdn,解决方法是加一串代码,就可,但是我加了以后也还是不行,搜了大约1个半小时,才看到有个帖子说是要加完代码后要重启内核


tf.compat.v1.enable_eager_execution()
然后就可正常运行了。
补沐神的视频
很简单的机器学习就两个步骤:1.特征提取。2.模型的预测
线性回归
给你一个数据集,比如学习的时间和期末取得分数这么一个表
一般竞赛也就是给你前4行,和 第5行的前半个,让你求?,上面是训练集,下面是测试集。
线性回归输出是一个连续值,因此适用于回归问题。回归问题在实际中很常见,如预测房屋价格、气温、销售额等连续值的问题。与回归问题不同,分类问题中模型的最终输出是一个离散值。我们所说的图像分类、垃圾邮件识别、疾病检测等输出为离散值的问题都属于分类问题的范畴。softmax回归则适用于分类问题。
动手学上的房价y与面积x1和房龄x2有关,这和我在b站上学的豆豆的毒性和豆豆的大小有关的模型是一样的,只不过这里的控制房价的因素有两个罢了。b站上的算是一个让人理解的简化版的例子。
模型
简单来说,就是用用房屋的面积和房屋的房龄
去描述房屋的价格y,这就是建立模型。而房屋的面积和房屋的房龄对房屋价格的影响也是有所不同的,所以需要权重来看哪个占主导地位更多一些,从而可以更好的描述价格。线性回归假设输出与各个输入之间是线性关系:
,
是权重(weight),
是偏差(bias),且均为标量。它们是线性回归模型的参数(parameter)。模型输出y^是线性回归对真实价格y的预测或估计。我们通常允许它们之间有一定误差。
模型训练
接下来我们需要通过数据来寻找特定的模型参数值,使模型在数据上的误差尽可能小。这个过程叫作模型训练(model training)。下面我们介绍模型训练所涉及的3个要素。
训练数据
我们通常收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄。我们希望在这个数据上面寻找模型参数来使模型的预测价格与真实价格的误差最小。在机器学习术语里,该数据集被称为训练数据集(training data set)或训练集(training set),一栋房屋被称为一个样本(sample),其真实售出价格叫作标签(label),用来预测标签的两个因素叫作特征(feature)。特征用来表征样本的特点。
假设我们采集的样本数为n,索引为i的样本的特征为和
,标签为
。对于索引为i的房屋,线性回归模型的房屋价格预测表达式为
损失函数
在模型训练中,我们需要衡量价格预测值与真实值之间的误差。通常我们会选取一个非负数作为误差,且数值越小表示误差越小。一个常用的选择是平方函数。它在评估索引为i的样本误差的表达式为loss=。显然,误差越小表示预测价格与真实价格越相近,且当二者相等时误差为0。给定训练数据集,这个误差只与模型参数相关,因此我们将它记为以模型参数为参数的函数。在机器学里,将衡量误差的函数称为损失函数(loss function)。这里使用的平方误差函数也称为平方损失(square loss)。平均平方误差,简称MSE或均方误差(Mean Square Error) ,
。当只有一个权重的时候,坐标系是x轴为权重,y为均方误差,在横坐标这里搜索了100个数值,那么当
里有两个权重
,即
,就不是我们所想的二次曲线找最低点那么简单了。我们要在一个平面内搜索
,就要搜索100*100,也就是
个数值,
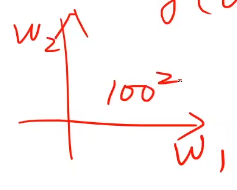 ,如果有10个权重,那么就要搜索
,如果有10个权重,那么就要搜索,所以用穷举法来说,尽可能找比较符合的权重,然后去求目标函数,然后去决定取哪一组权重的组合能保证它的目标函数最小,但是搜索的区间太大的话,穷举法一般很难实现。
至于梯度下降(贪心)只看眼前最好的一步,不一定能得到最有的结果,但是能得到局部最优的结果。看了b站刘老师的课以后,有了新的认识。初始权重确定了,那你的权重往哪边走? 梯度的定义, 用我们的目标函数对权重求导数,就求到了它的上升方向。导数正的说明目标函数是在上升,导数负的说明目标函数在下降。


学习率不宜过大。我们每次迭代都往下降最快的方向走。只能得到局部最优结果,对于非凸函数(就是在函数上画一条横线,你不能保证图像的所有的都在所画横线的上方)来说。

存在一个特殊点鞍点,即梯度为0的点。像这样的一个函数它是没有局部最优点的, 它会没办法继续迭代,因为
它会没办法继续迭代,因为,梯度为0,没法迭代了,就陷入鞍点,就停下了,没法运动。
从多维来看, 从一个切面来看,它是最小值,从另一个切面来看,它是最大值。解决最大的问题不是局部最优,需要解决最大的问题是解决鞍点问题。
从一个切面来看,它是最小值,从另一个切面来看,它是最大值。解决最大的问题不是局部最优,需要解决最大的问题是解决鞍点问题。
对整个MSE的损失求导

一般以后我们遇到的cost function,波动比较大的往下走这是正常的,如果想要平缓的曲线的话可以对均方误差做指数加权均值,但是如果出现均方误差下去又上去了,说明发散了,这次的训练是失败的。可能失败的原因是学习率取得太大。

梯度下降的算法在以后的学习中用的可能也比较少,更多的用随机梯度下降,N个样本中随机选一个样本,用单个样本的损失求导作为梯度,对每一个样本进行更新。 因为cost function 是所有的样本算出来的,容易陷入鞍点,因为我们拿到的样本一般都是有噪声的。即使我们陷入到鞍点,但是随机噪声可能把我们向前推动,将来更新可能会向前推动,跨过鞍点。以下对loss求导的是随机噪声的算法,对cost求导的是梯度下降的算法。

如果我们采用的是梯度下降算法,我们对于每个样本x,在用模型计算时,计算和计算
是没有互相依赖关系的,是可以并行计算。因为梯度是求得总的。和单个之间有无关系这个关系是没有关系的。
如果我们采用的是随机梯度下降, 和
是有关系的,因为我们要对
做更新的。
三种梯度下降
随机梯度下降,用的是单个样本,要每次更新w,要用到之前的w,具有性能好,但是浪费时间,因为用到瞬时的斜率去调整权重。
批量梯度下降,也叫梯度下降,用的是总体的,单个样本之间随便了,所以可以进行并行计算,时间用的少,但是性能不是很好。但是我觉着它收敛的速度真的好慢...,因为用的是总的k去调整权重。
mini-batch ,这是一个折中的 算法,就是把很多的数据进行分组,然后用随机梯度下降。
随机梯度下降豆豆实验
import dataset #导入生成豆豆的数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib auto
import numpy as np
import matplotlib.pyplot as plt
%matplotlib auto
xs,ys=dataset.get_beans(100)
plt.title("Sixe-Toxicity Function",fontsize=15)
plt.xlabel("豆豆大小")
plt.ylabel("毒性")
plt.scatter(xs,ys)
plt.rcParams["font.sans-serif"] = "SimHei"
w=0.1
for _ in range(100): #进行100次的学习
for i in range(100):
x=xs[i]
y=ys[i]
k=2*(x**2)*w+(-2*x*y) #这是均差代价函数的斜率
a=0.1 #学习率
w=w-a*k #权重的计算
plt.clf() #清空窗口
plt.xlim(0,1) #对横坐标的范围做出限制,防止点抖动
plt.ylim(0,1.2)
plt.scatter(xs, ys)
y_pre = w * xs #对权重进行更新
plt.plot(xs, y_pre)
plt.pause(0.01) #对图像进行暂停import dataset
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.backends.backend_pdf import PdfPages
from matplotlib import animation
xs,ys=dataset.get_beans(100)
fig=plt.figure() #创建一个画布
plt.title("Sixe-Toxicity Function",fontsize=15)
plt.xlabel("豆豆大小")
plt.ylabel("毒性")
plt.scatter(xs,ys)
plt.rcParams["font.sans-serif"] = "SimHei"
ims=[]
w=0.1
for _ in range(10):
for i in range(10):
x=xs[i]
y=ys[i]
k=2*(x**2)*w+(-2*x*y)
a=0.1
w=w-a*k
#plt.clf()
#plt.scatter(xs, ys)
y_pre = w * xs
plt.xlim(0,1)
plt.ylim(0,1.2)
#plt.plot(xs, y_pre)
#plt.pause(0.01)
ims.append(plt.plot(xs,y_pre,'b')+plt.plot(xs,ys,'ro'))
ani = animation.ArtistAnimation(fig,ims,interval=33)
ani.save('sin_dot.gif', writer='pillow') #保存动图
由于不能上传5M以上图片,只得把学习次数调低。不然所生成的gif图片过大,导致无法上传。此上传的gif图为学习9次的。

批量梯度下降豆豆实验
总体变动不大,只是变了两行代码。
import dataset
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib auto #图片是动态的
import numpy as np
import matplotlib.pyplot as plt
%matplotlib auto
xs,ys=dataset.get_beans(100)
plt.title("Sixe-Toxicity Function",fontsize=15)
plt.xlabel("豆豆大小")
plt.ylabel("毒性")
plt.scatter(xs,ys)
plt.rcParams["font.sans-serif"] = "SimHei"
w=0.1
for _ in range(100):
for i in range(100):
x=xs[i]
y=ys[i]
k=2*np.sum(x**2)*w+np.sum(-2*x*y) #整体的样本
k=k/100
a=0.1
w=w-a*k
plt.clf()
plt.scatter(xs, ys)
y_pre = w * xs
plt.plot(xs, y_pre)
plt.pause(0.01)固定步长下降豆豆实验
自己用固定步长的方法敲一下。刚开始没加for循坏,导致只能训练一次,只做了一次的步长移动。敲完还纳闷,为啥效果不对。这才想起来没加for循坏
此方法是,左半边的斜率是负的,右半边的斜率是正的,由此采用固定步长的方法,使得其不管是在左半边还是右半边都能收敛到最低点。
import numpy as np
import dataset
import matplotlib.pyplot as plt
xs,ys=dataset.get_beans(100)
w=0.1
step=0.01
for _ in range(200):
k=2*np.sum(xs**2*w)+(-2)*np.sum(xs*ys)
k=k/100
if k>0:
w=w-step
else:
w=w+step
y_pre=w*xs
plt.scatter(xs,ys)
plt.plot(xs,y_pre)
plt.show()
关于matplotlib生成的动图保存问题。
找解决方法也是找了一下午吧。但是能给的解决方法少之又少,只有寥寥几个,而且试过以后,也不能保存,很是郁闷。然后问群友,无人回应,有个人说matplotlib库里自带animation模块,可以保存动图,于是开始搜索,animation,看到一个帖子,粘了以下代码运行出动态图,并能保存在当前路径。以下是帖子的代码和代码链接。开始自己琢磨怎么 保存自己代码的图。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import animation
"""
animation example 2
author: Kiterun
"""
fig, ax = plt.subplots()
x = np.linspace(0, 2*np.pi, 200)
y = np.sin(x)
l = ax.plot(x, y)
dot, = ax.plot([], [], 'ro')
def init():
ax.set_xlim(0, 2*np.pi)
ax.set_ylim(-1, 1)
return l
def gen_dot():
for i in np.linspace(0, 2*np.pi, 200):
newdot = [i, np.sin(i)]
yield newdot
def update_dot(newd):
dot.set_data(newd[0], newd[1])
return dot,
ani = animation.FuncAnimation(fig, update_dot, frames = gen_dot, interval = 100, init_func=init)
ani.save('sin_dot.gif', writer='imagemagick', fps=30)
plt.show()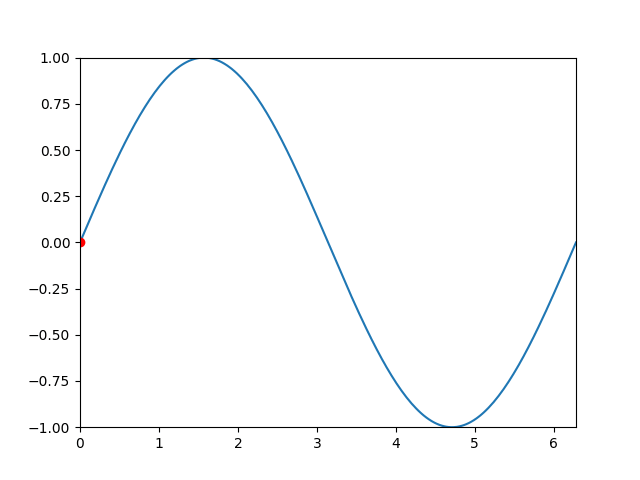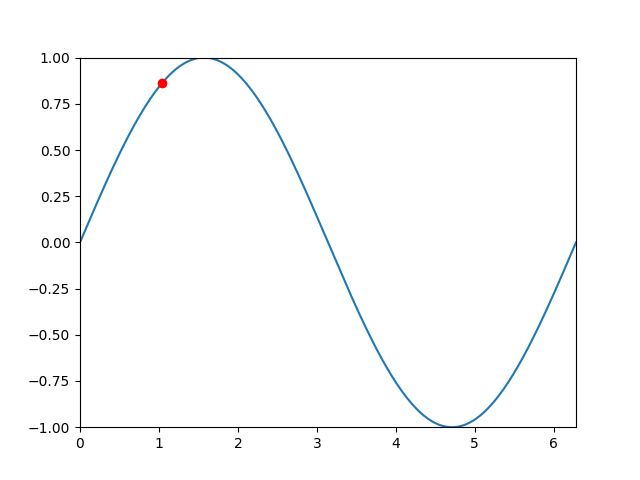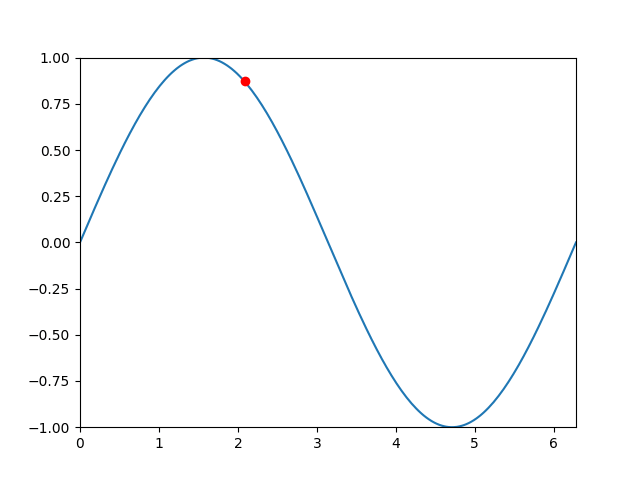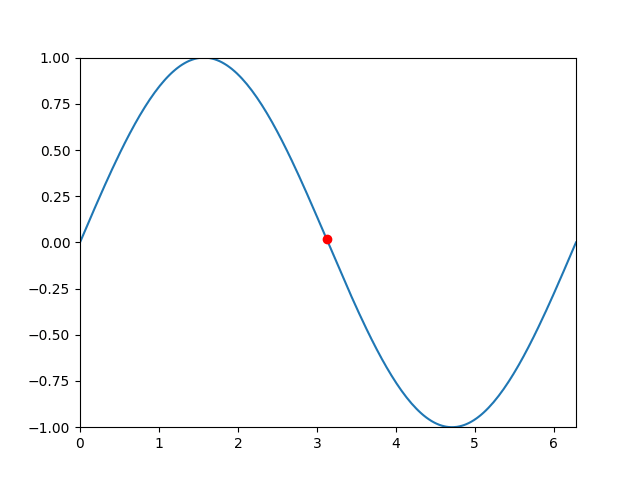
Tensorlow 中的常量值函数:tf.zeros()、tf.ones()、tf.fill()和tf.constant()
原文链接
https://blog.csdn.net/mch2869253130/article/details/89284628
Session 是 Tensorflow 为了控制,和输出文件的执行的语句. 运行 session.run() 可以获得你要得知的运算结果, 或者是你所要运算的部分.
# coding=utf8
import tensorflow as tf
import numpy as np
a = tf.constant(2,shape=[2]) #一个长为2的list
b = tf.constant(2,shape=[2,2]) #元素都是2的2*2的矩阵
c = tf.constant([1,2,3],shape=[6]) # 后面的元素用3填充
d = tf.constant([1,2,3],shape=[3,2])
sess = tf.Session()
sess.run(tf.global_variables_initializer())
print(sess.run(a),)
print() #空格
print(sess.run(b))
print()
print(sess.run(c))
print()
print(sess.run(d))
tensorflow | tf.assign的用法
# 创建一个变量, 初始化为标量 0.
state = tf.Variable(0, name="counter")
# 创建一个 op, 其作用是使 state 增加 1
one = tf.constant(1)
new_value = tf.add(state, one)
update = tf.assign(state, new_value) # 把new_value的值赋值给state
# 启动图后, 变量必须先经过`初始化` (init) op 初始化,
# 首先必须增加一个`初始化` op 到图中.
init_op = tf.initialize_all_variables()
# 启动图, 运行 op
with tf.Session() as sess:
# 运行 'init' op
sess.run(init_op)
# 打印 'state' 的初始值
print (sess.run(state))
# 运行 op, 更新 'state', 并打印 'state'
for _ in range(3):
sess.run(update) #同时调用td.add,tf.assign
print (sess.run(state))
# 输出:
# 0
# 1
# 2
# 3
反向传播
对于这样的豆豆数据,我们的预测函数的弊端就出现了。之前是本着如无必要,无处新知,而现在的新知就是将预测函数的里面的
,有了
的存在,我们可以将直线有了平移和旋转,更好的拟合。可以更好的应对奇奇怪怪的豆豆数据。


但是有了b的存在,图像也从e-w的二维图像变成了三维e-w-b图像


如果不考虑,即
,这种情况,即在b=0处沿w的方向切一刀,就会形成一个关于e和w 的开口向上的抛物线,然后不断地通过梯度下降算法调整w最后达到最低点,但是此刻的最低点却不是曲面的最低点。说明b=0的取值不是最好的。
如果我们沿着b的方向来一刀,切口形成的曲线似乎也是一个开口向上的抛物线。我们需要研究以下e和b的关系。
横看调整w,侧看调整e。两个方向的调整合成一个方向的调整,即向着曲面的最低点挪动。再说下,一个曲面上某点的斜率是什么样子,是关于w的还是关于e的?我们在代价函数的w和b两个方向分别求得斜率,对于有两个自变量得代价函数,我们先偏向w求导,再偏向b求导数,为了区分只有一个自变量的情况,我们把某一个自变量上的导数也称之为“偏导数”。如果我们把对w和b的偏导数看成向量,把这两个向量合在一起,形成一个新的合向量。沿着这个合向量进行下降,是这个曲面在该点下降最快的方式,这个合向量在数学上称之为“梯度”,因为之前在二维上,也可以把梯度和斜率理解成是一样的。在二维的情况叫它斜率下降也未尝不可。
把我们统计观测而来的数据,送入预测函数得到进行预测的过程称为前向传播。因为计算从前往后,数据通过预测函数完成一次前向传播就会得到一个预测值。用代价函数去修正预测函数参数的过程,也称为“反向传播”,因为计算从后往前。而不断的经历前向传播和反向传播最后到达代价函数的最低点的过程我们称之为学习或者是训练。这就是所谓的机器学习中的神经网络,不过对于现在的单个神经元,用神经网络可能不大恰当,但是最后会引入多个神经元。

预测函数为y=wx+b,梯度下降豆豆编程实验
此次实验主要做两件事,1.在引入b后,我们绘制的代价函数曲面看看是不是一个碗
2.在w和b两个方向上分别求导,得到这个曲面某点的梯度进行梯度下降,拟合数据。我们尝试从w的角度去解构这个代价函数形成的过程,也就是说每次取不同的b,看看误差e和w形成的抛物线是不是一个扁扁的碗。
dataset.py里的豆豆数据变成这种的。我们用dataset1.py来存,dataset1.py的源码如下
import numpy as np
def get_beans(counts):
xs = np.random.rand(counts)
xs = np.sort(xs)
ys = np.array([(0.7*x+(0.5-np.random.rand())/5+0.5) for x in xs])
return xs,ys
绘制的散点图如下

import dataset1
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
xs,ys=dataset1.get_beans(100)
plt.title("Sixe-Toxicity Function",fontsize=15)
plt.xlabel("豆豆大小")
plt.ylabel("毒性")
plt.rcParams["font.sans-serif"] = "SimHei"
plt.xlim(0,1)
plt.ylim(0,1.5)
plt.scatter(xs,ys)
w=0.1
b=0.1
y_pre=w*xs+b
plt.plot(xs,y_pre)
plt.show()
#下面两行代码就是把Axes3D和matplotlib做一个连接,这样就可以用Axes3D绘制3D图像
fig=plt.figure() #调用plt的figure函数得到plt的图形对象
ax=Axes3D(fig) #然后用figure对象创建Axes3D对象
ax.set_zlim(0,2)
ws=np.arange(-1,2,0.1) #从1到2,每次递增0.1
bs=np.arange(-2,2,0.03)
for b in bs :
es=[]
for w in ws:
y_pre=w*xs+b #带入预测函数进行预测
e=np.sum((ys-y_pre)**2)*(1/100) #计算全部样本的均方误差
es.append(e) #把计算的结果放到数组中
# plt.plot(ws,es)
ax.plot(ws,es,b,zdir='y')
#正常坐标是x和z在下面,y朝上,但是Axes3D的三维坐标系统x和y在下面,z朝上
#画出来是一个倒着的图像,而zdir='y'就是把z轴的朝向从z换到y上
plt.show()
import numpy as np
import matplotlib.pyplot as plt
import dataset1
import matplotlib.pyplot as plt
import numpy as np
xs,ys=dataset1.get_beans(100)
plt.title("Sixe-Toxicity Function", fontsize=15)
plt.xlabel("豆豆大小")
plt.ylabel("毒性")
plt.scatter(xs, ys)
plt.rcParams["font.sans-serif"] = "SimHei"
w = 0.1
b=0.1
for _ in range(500):
for i in range(100):
x = xs[i]
y = ys[i]
dw=2*x**2*w+2*x*b-2*x*y #dw就是对w求导
db=2*b+2*x*w-2*y
a = 0.01
w = w - a * dw
b=b-a*db
plt.clf()
plt.xlim(0, 1)
plt.ylim(0, 1.2)
plt.scatter(xs, ys)
y_pre = w * xs+b
plt.plot(xs, y_pre)
plt.pause(0.01) 由于此训练的gif图太大,现直接展示最终结果,的确达到了很好的拟合

b站深度学习
将来我们进行网络训练时,就要对权重w进行更新,更新权重的过程,需要计算损失对权重的导数,因为我们不是要
最小,而是要损失值最小。所以我们在做随机梯度下降的时候,用单个样本的损失对权重求导,对于单个简单的神经可以,如果遇到复杂的神经,

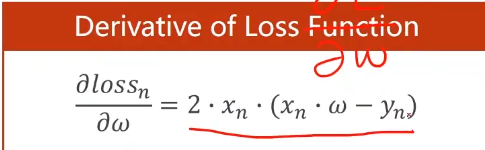

上面的每一个圆圈里面我们都有相应的权重,第一层来看,输入是五维的向量,输出是六维的向量,第一层的权重有30个,第二层的权重有42个,依此类推。挨个写解析式是一个繁重的任务,在写解析式很复杂了。
所以我们需要用别的方法,比如把这个 网络看成一个图,在这个图上,进行传播梯度,最终根据链式法则把梯度求出来。这种算法就叫做反向传播。比如简单的两层神经网络

上图右上计算图的实现就是画横线的,就叫做全连接神经网络中的一个层。其中b1为偏置量,外面再乘一个w2就是对第一层的输出结果,再做一个乘法和加法,就构成了第二层。

 这本书有很多矩阵计算公式。
这本书有很多矩阵计算公式。
这种不断的进行线性变化的,不管是几层,把式子展开,最后的形式都是一样的,都是.我们要将最后的输出加一个非线性的变化函数。我们对输出的向量的每一个值,都应用非线性函数。为什么要加激活函数?因为不加的话,即使深度再深度,其实只相当于用了一层而已。不加的话,无论多少层都没意义,因为到头来还是线性的。加了激活函数之后神经网络才有了能够逼近任意函数形式的能力。

















 1498
1498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









