








目录
一、分类
通过前面的学习,我们利用梯度下降算法,在反复的前向和反向传播的训练下,以及能够让小蓝从偏离现实的直觉自动学习到符合现实的认知。但是总感觉有点怪怪的,因为这种精确拟合的方式似乎并不是一个智能体在思考的时候常见的模式。仔细想想,我们人在思考的时候往往不会产生精确的数值估计,而更常做的事情是分类。

比如给你一个馒头,你会说这么大的我能吃饱,而这么大的我吃不饱。我们更倾向于把馒头分为能吃饱和吃不饱这两类。而不会在大脑中构建出所谓的馒头大小和饱腹程度的精确函数曲线。


再比如我们一开始说过的一只小狗的眼睛,你可能把它分为可爱和不可爱两类,顶多再加一个吓人的分类,但是无论如何,很少有人会在大脑里建立眼睛大小和可爱程度的精确拟合函数。


对一个东西,简单的贴标签比仔细的计算更符合我们的生物本能,也就是说,人类思考问题的方式往往都是离散的分类,而不是精确的离合。

对于小蓝也是如此,若能精确的估算出不同大小的豆豆的毒性固然是好事,但是一般会采用更加干脆的分类,有毒或者没毒。假如小蓝本身有一定的抗毒性,比如最多能抗住0.8的毒性,只有超过这个毒性的豆豆才会让小蓝中毒,所以小蓝会更乐意把豆豆分为有毒和无毒两类。至于具体有多少毒,那就让小蓝里的科学家们去研究吧。

二、激活函数
从有毒和无毒的角度来看,豆豆数据其实是这样的,注意,我们的纵坐标不再表示毒性的大小,而变成了有毒的概念,1表示有毒,0表示无毒,不存在中间的值。所以面对这个两极分化的分类问题,我们之前的神经元预测函数模型是否还有效?很明显不行,这个函数的值可以大于1,也可以小于0,我们可能更希望让最后的输出变成这样。在一元一次函数的输出大于某个阈值的时候,固定输出1,而小于这个阈值的时候固定输出0。我们可以用一个分段函数很容易实现这一点,把之前的线性函数的结果在丢进一个分段函数中进行二次加工,而这个新加入的分段函数就是一种所谓的激活函数。

其实我们一开始提到的Rosenblatt感知器中也有激活函数,当时为了不造成困扰,我们并没有提及Rosenblatt感知器把线性函数的计算结果放入一个类似的符号函数中进行分类,也就是说到此为止我们才算见到了完整的Rosenblatt感知器。

三、Logistic函数
当然使用这种阶跃函数作为激活函数并不十分美好,远的不说,你看这个大括号看起来就不是个容易处理的家伙。我们来看看另外一种更好的一个常用的S型函数,Logistic函数。

我们一般采用标准的Logistic函数,也就是取L=1,K=1,y0=0。

Sigmoid,Logistic函数的区别:
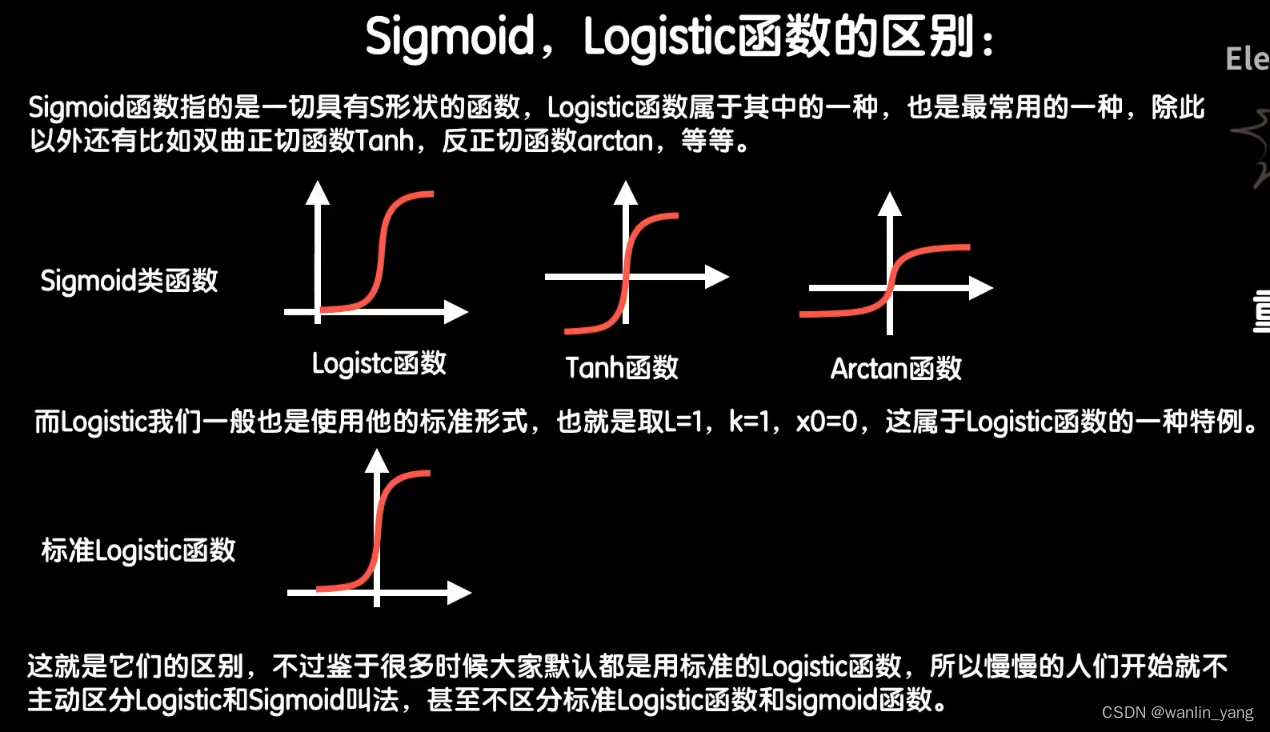
我们来看看如何使用这个S型的激活函数。可以看出来,这个函数的计算结果始终在0到1之间,它的名字逻辑也暗示了这一点,它很适合做逻辑判断,也就是分类。除此之外还有一点,它很软,很圆润。有的同学或许会说了,这个圆润的函数看起来好像并没有尖锐的阶跃函数自信,毕竟它有一个渐渐上坡的过程。如果我们把它应用在我们的分类问题中,就是这样的一个效果,在靠近分界点处,它不够果断,确实,但是这种软和圆润却是一个极好的特性。我们知道利用梯度下降算法进行的参数调整学习的时候需要对函数进行求导,也就是求斜率。我们在加入激活函数后,同样需要对它也进行求导。相比之下,如果用类似阶跃函数,虽然判断的自信满满,但是在分界点处的导数不好处理,而除了分界点,其他地方的导数总是0,无法进行下降。

实际上阶跃函数的导数是一个冲击函数,在分界处无穷大,而在其他地方都是0,这很不利于梯度下降的进行。

所以使用Sigmoid这种软软的,润润的,处处可导,导数又处处不为0的激活函数是很好的。
我们来看一下把这个圆润的函数加入小蓝的神经元作为激活函数之后,小蓝预测的模型。


此刻对于这个新的预测模型,我们得到方差代价函数是这样的,我们该如何对W和B分别求导,然后进行梯度下降?当然最简单和粗暴的方法还是取一个点,然后利用定义法进行求导,当然这太麻烦了,我们有更巧妙的方法。

我们重新审视一下这个函数,有没有更好的方法求e对W的导数?这是一个复合函数。

复合函数的链式求导法则

代价函数e对w求偏导


三、编程实验
1.豆豆的毒性数据生成代码dataset.py
import numpy as np
def get_beans(counts):
xs = np.random.rand(counts)
xs = np.sort(xs)
ys = np.zeros(counts)
for i in range(counts):
x = xs[i]
yi = 0.7*x+(0.5-np.random.rand())/50+0.5
if yi > 0.8:
ys[i] = 1
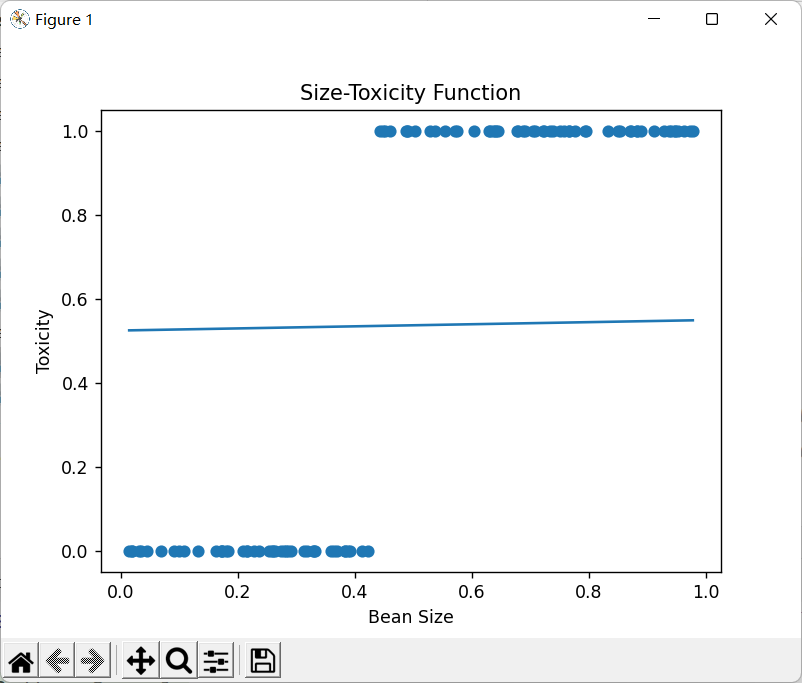
return xs,ys豆豆毒性分布如下:
2.加入激活函数后的梯度随机下降算法:activation.py
import dataset #调用dataset库
from matplotlib import pyplot as plt #调用matplotlib库的pyplot
#import matplotlib.pyplot as plt
import numpy as np
m=100
xs,ys=dataset.get_beans(m) #获取100个豆子数据
#配置图像,坐标信息
plt.title("Size-Toxicity Function",fontsize=12)#设置图像名称
plt.xlabel("Bean Size")#设置横坐标的名字
plt.ylabel("Toxicity")#设置纵坐标的名字
plt.scatter(xs,ys) #画散点图
#预测函数
#y=0.1*x
w=0.1 #初始权值
b=0.1
z=w * xs+b
a=1/(1+np.exp(-z))#将预测函数送入激活函数sigmoid
plt.plot(xs,a)
plt.show() #显示图像
for _ in range(5000):#调整5000次全部,0-99的整数,用range 函数进行for循环
for i in range(100):#调整1次全部,可能会导致线不拟合
x=xs[i];
y=ys[i];
alpha=0.01 #学习率,学习率不可过大也不可过小
# 三个函数
z = w * x + b
a = 1 / (1 + np.exp(-z))
e = (y - a) ** 2
# 对w和b求偏导
deda = -2 * (y - a)
dadz = a * (1 - a)
dzdw = x
dzdb = 1
dedw = deda * dadz * dzdw
dedb = deda * dadz * dzdb
w = w - alpha * dedw
b = b - alpha * dedb
if _ % 100 == 0: #控制绘图时间,把绘图频率降低100倍
# 绘制动态
plt.clf() # 清空窗口
plt.scatter(xs, ys)
z = w * xs + b
a = 1 / (1 + np.exp(-z)) # 加入激活函数
plt.xlim(0,1) #plt.xlim()函数限制x轴范围
plt.ylim(0,1.1) #plt.ylim()函数限制y轴范围
plt.plot(xs, a)
plt.pause(0.01) # 暂停0.01秒
生成图像
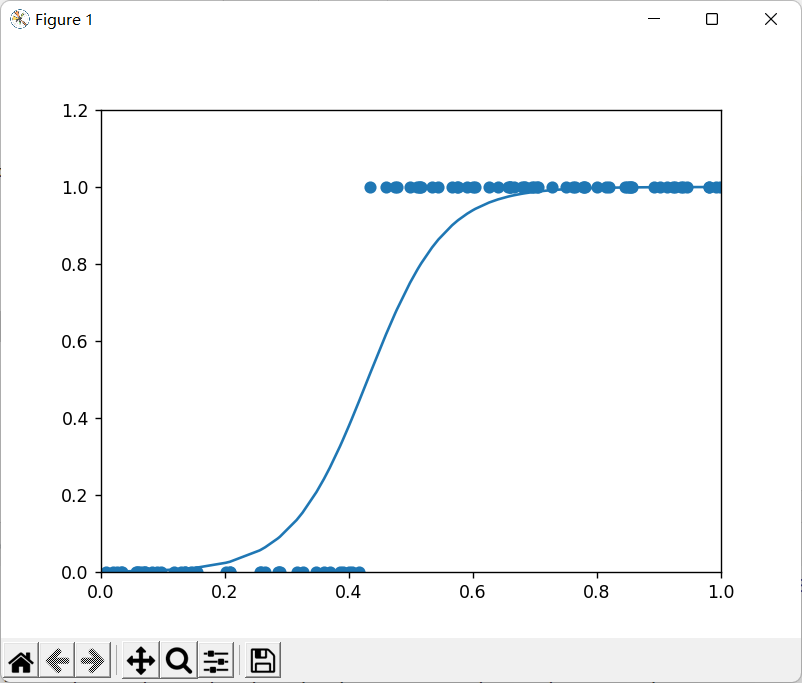
四、总结
我们说精确拟合的方式似乎并不是一个智能体在思考的时候常见的模式,往往分类判断更符合机器学习,所以引入了激活函数Logistic函数,并与阶跃函数做了对比。介绍了如何用复合函数的链式法则去求偏导,介绍了加入激活函数进行梯度下降的编程。
我们接下来要学习的多层感知器,或者说多层神经网络,其本质就是一个嵌套的非常非常深的复合函数,当然不仅可以纵向的增加神经元的层数,也可以横向的增加一层神经元的个数。

而利用复合函数求导的链式法则,把梯度下降和反向传播完美结合后,不论这个网络有多深有多宽,我们都可以用同样的套路计算出代价函数在每个神经元上全值参数的导数,然后利用梯度下降算法去调整这些参数。

我们会在接下来的课程中带你实现一个最简单的多层神经网络,那时候再来看看具体的操作。而激活函数除了可以很好的用来分类之外,也给我们的神经网络注入了灵魂。我们之前所说的神经元函数的模型一直采用的是线性函数,线性函数说到底能力有限,对于一个多层的神经网络,如果每个神经元都是一个线性函数,那么即使我们有很多很多的神经元构建出一个复杂的神经网络,从数学上来说,他们在一起仍然是一个线性系统,因为线性函数不论怎么叠加,结果都是一个线性函数。而激活函数是非线性的,它让我们的神经网络摆脱线性的约束,开始具备处理越来越复杂问题的能力。
我们将在下一节课中详细的说明这个问题,加入激活函数神经元扩展到多个节点的网络,这时候也就可以说是对一般情况下真正的反向传播算法了,把代价函数在神经网络中反向传播到各个节点,计算参数对代价函数的影响,然后调整参数。
正是深度学习的开山鼻祖Geoffrey Hinton和David Rumelhart等人在1986年开始在神经网络的研究中引入的反向传播算法成为了现代神经网络的基石,目前深度学习又统治着整个人工智能的。
而在此之前,人们对于多层感知器深度神经网络一直持有悲观的态度,正如Marvin Lee Minsky和Seymour Papert在反向传播算法发明之前的1961年是这么评价的.


五、往期内容

5.激活函数:给机器注入灵魂
6.隐藏层:神经网络为什么working
7.高维空间:机器如何面对越来越复杂的问题
8.初识Keras:轻松完成神经网络模型搭建
9.深度学习:神奇的DeepLearning
10.卷积神经网络:打破图像识别的瓶颈
11. 卷积神经网络:图像识别实战
12.循环:序列依赖问题
13.LSTM网络:自然语言处理实践
14.机器学习:最后一节课也是第一节课
视频链接:![]() https://pan.baidu.com/s/18ZvFPtdjpoxsPwcZ9-FMhA?pwd=8qb3可视化工具链接:
https://pan.baidu.com/s/18ZvFPtdjpoxsPwcZ9-FMhA?pwd=8qb3可视化工具链接:![]() https://pan.baidu.com/s/1kMpqjn3CGFcsJUYr6nlkug?pwd=lphb
https://pan.baidu.com/s/1kMpqjn3CGFcsJUYr6nlkug?pwd=lphb
可视化工具包含:从线性函数到激活函数
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









