







背景
大脑是如何思考?
如何描述“思考”或者”认知“?
认知以前当然就是一无所知。
认知事物的唯一方法就是依靠直觉。
如何描述直觉呢?
很明显是函数,我们通过函数来认知这个世界。
我们本来一直就是在用函数认识世界:
物理中,质量为m的物体在不同受力F下产生的加速度a,是一个以F为自变量,m为参数,a为因变量的函数
在经济学中,将消费,投资,政府购买和净出口作为自变量,也可以形成一个关于GDP的认知函数
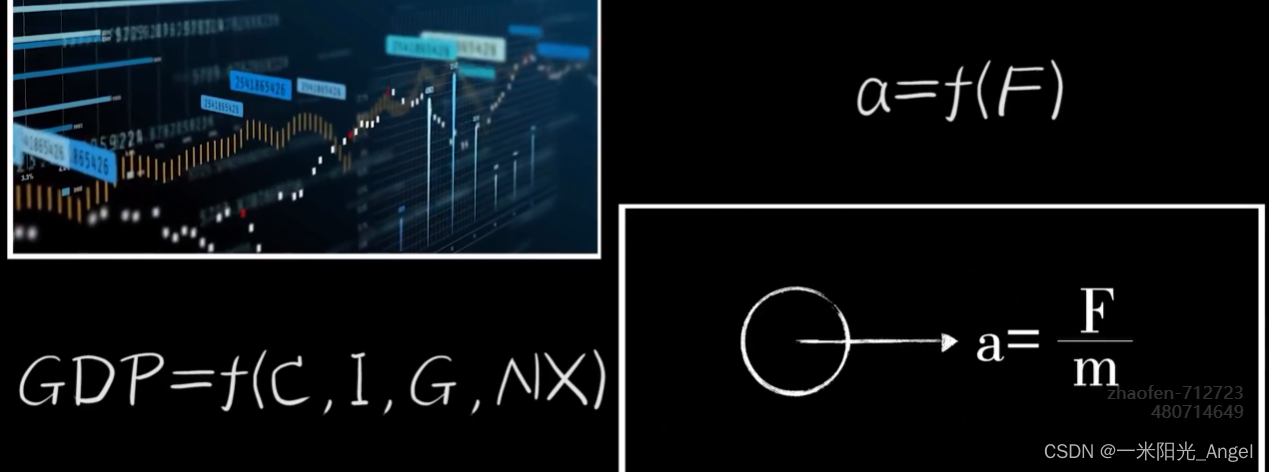
除了上述这种严格的领域;对于这种不太严格的领域,例如:
- 气温对人心情的影响
- 一只小狗眼睛的大小和其可爱程度的关系

这类不太严格,但人类更加擅长的问题,也就是人工智能要解决的问题。
解决问题的方法就是,找到一个惬当的函数去描述它。
把智能体对世界的认知的过程,看作在脑中不断形成各种函数
从偏离现实的直觉过度到符合现实的认知,人工智能最初是如何实现的?
小蓝的问题:如何描述直觉
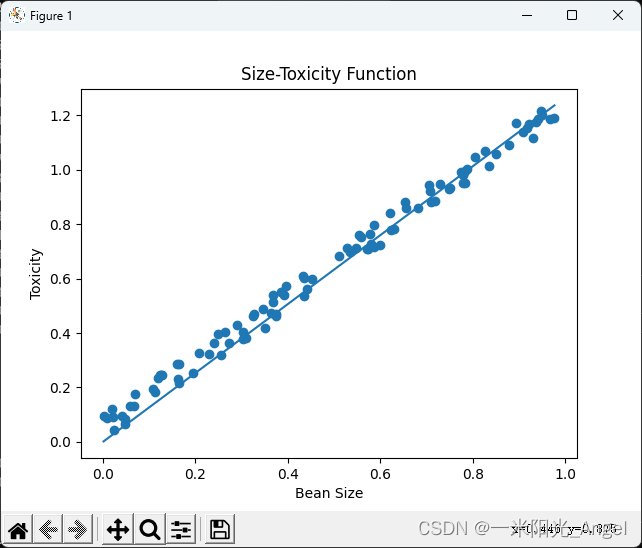
豆豆的毒性和大小存在关系:豆豆的大小X是自变量,毒性Y是因变量,w是一个确定的参数(直线的斜率)
一个简单的一元一次函数,就可以描述一个直觉,建立一种思考/认知的模型

发展
1943神经学家McCulloch和数学家Pitts提出一种神经元模型【McCulloch-Pitts模型】,这个模型是对生物神经元一种相当简化的模仿。选择用一次函数来模仿神经元。
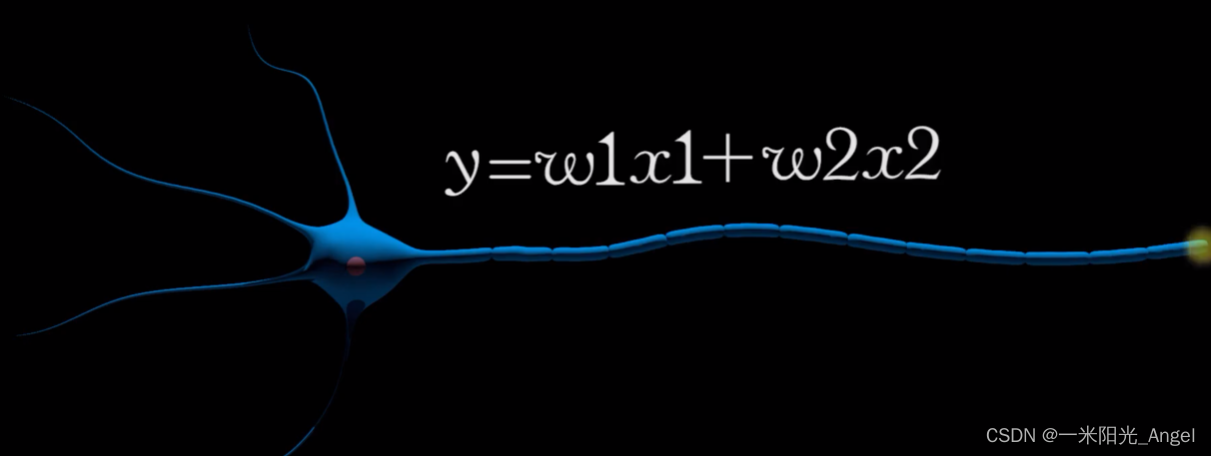
开始的【McCulloch-Pitts模型】没有自动学习和适应的方法,需要手动调节神经元权重。
后来,Rosenblatt提出【Rosenblatt感知器】,解决神经元自己调节权重参数的能力。【Rosenblatt感知器】是第一个从算法上完整描述的神经元。
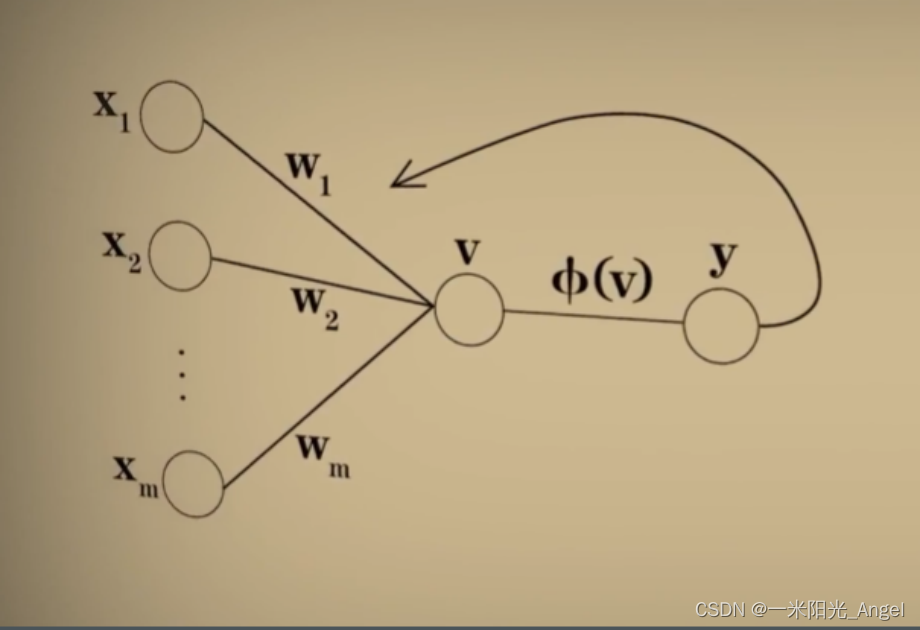
【Rosenblatt感知器】通过误差来修正结果
- 输入–>通过【McCulloch-Pitts模型】–>得到结果
- 新权重w=权重w+误差(标准答案-结果)
- 误差 * 输入x 为了修正输入小于0的情况
- 误差 * 学习率,学习率用来调节修正的幅度,避免幅度过大,错过最佳权重w
- 数学证明 w 最终收敛于一个值
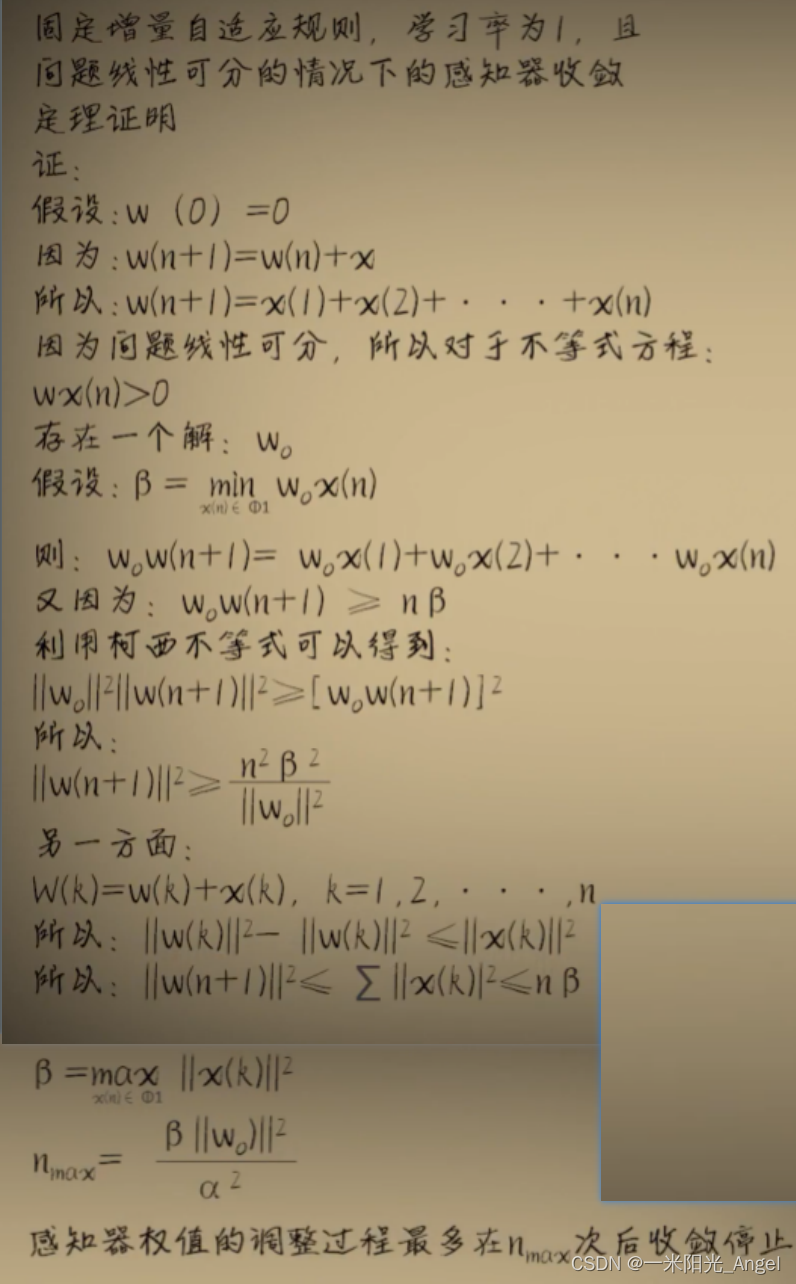
- 现代机器学习和神经网络应用中很少采用古老的【Rosenblatt感知器】模型
- 目前通过 梯度下降和反向传播 进行机器学习
实践
1. 构造数据集
import numpy as np
def get_beans(counts):
xs = np.random.rand(counts)
xs = np.sort(xs)
ys = [1.2*x+np.random.rand()/10 for x in xs]
return xs,ys
2. 用matplotlib绘制图像
import dataset
from matplotlib import pyplot as plt
xs,ys=dataset.get_beans(10)
print(xs)
print(ys)
#配置图像
plt.title("Size-Toxicity Function",fontsize=12) #设置图像名称
plt.xlabel("Bean Size")#设置横坐标的名称
plt.ylabel("Toxicity")#设置纵坐标的名称
plt.scatter(xs,ys)
w = 0.5
y_pre = w * xs
print(y_pre)
plt.plot(xs,y_pre)
plt.show()

2. 用python 描述【Rosenblatt感知器】

import dataset
from matplotlib import pyplot as plt
xs,ys=dataset.get_beans(100)
print(xs)
print(ys)
#配置图像
plt.title("Size-Toxicity Function",fontsize=12) #设置图像名称
plt.xlabel("Bean Size")#设置横坐标的名称
plt.ylabel("Toxicity")#设置纵坐标的名称
plt.scatter(xs,ys)
w = 0.5
#重复100次全部豆豆的预测
for i in range(100):
#完成全部豆豆的预测
for i in range(100):
x = xs[i]
y = ys[i]
y_pre = w*x
#误差
e = y - y_pre
#学习率
alpha = 0.05
#调整误差
w = w + alpha * e * x
#得到训练后的w
y_pre = w * xs
plt.plot(xs,y_pre)
plt.show()
完成1次预测的结果:

完成100次预测的结果:















 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









