






共享内存:
共享内存是 一种可被程序员直接操控的缓存,主要作用有两个:一个是减少核函数中对全局内存的访问次数,实现高效的线程块内部的通信,另一个是提高全局内存访问的合并度。
我们将通 过两个具体的例子阐明共享内存的合理使用,包括一个数组归约的例子和第7节讨论过的 矩阵转置的例子。其中,数组归约是一个非常适合学习CUDA编程的例子,通过它可以了 解CUDA编程的很多方面。
1.例子数组归约计算
考虑一个有N个元素的数组x,假如我们需要计算该数组中所有元素的和, 即sum=x[0]+x[1] +...+x[N-1]。
先看看cpu程序;
typedef double real;
//typedef double double;
#include "error.cuh"
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<math.h>
#include<stdlib.h>
real reduce(const real* x, const int N) {
real sum = 0.0;
for (int n = 0; n < N; n++) {
sum += x[n];
}
return sum;
}
int main(void) {
const int N = 100000000;
const int M = sizeof(real) * N;
real* x = (real*)malloc(M);
for (int i = 0; i < N; i++) {
x[i] = 1.23;
}
real sum = reduce(x, N);
printf("sum = %10f.",sum);
return 0;
}这里typedef 了 real类型为double或者float
先看看double结果

该结果前9位有效数字都正确,从第10位开始有错误。
然后时float结果

该结果完全错误。这里好像就差老远了。
为什么会这样呢?
单精度浮点数只有6,7位有效数字。当
这是因为,在累加计算中出现了所谓的“大数吃小数”的现象。单精度浮 点数只有6、7位精确的有效数字。在上面的函数reduce中,将变量sum的值累加到3000 多万后,再将它和1.23相加,其值就不再增加了(小数被大数“吃掉了”,但大数并没有变化)。
在计算单精度浮点数(float)的和时,如果将大数与小数相加,可能会导致精度损失或者溢出。这是因为单精度浮点数有限的精度,只能表示一定范围的数值,同时有限的小数位数。当大数与小数相加时,精度限制可能导致一些小数部分的损失,从而引起舍入误差。
(GPT)例如,考虑以下示例:
float a = 1.0e38; // 大数
float b = 1.0; //
小数 float result = a + b;
在这个示例中,a 是一个非常大的数,而 b 是一个小数。当它们相加时,由于单精度浮点数的精度限制,b 的值可能会在计算中丢失,导致 result 的值不等于预期的 a + b。
对于数组归约的并行计算问题,从一个数组出发,最终得到一个数。所以必须使用某种迭代方案。
假如数组元素个数是2的整数次方,我们可以将数组后半部分的各个元素与前半部分对应的数组元素相加。如此重复,最后第一个数组元素就是最初数组中各元素之和。
这就是所谓的折半归约(binary reduction)法。

这个代码是存在问题的,也许我们乍一看没啥问题。
先看看前两次迭代,
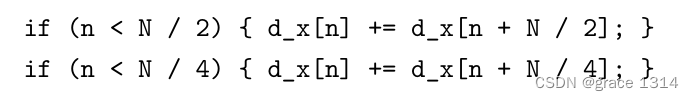

即,执行顺序出错就g了。
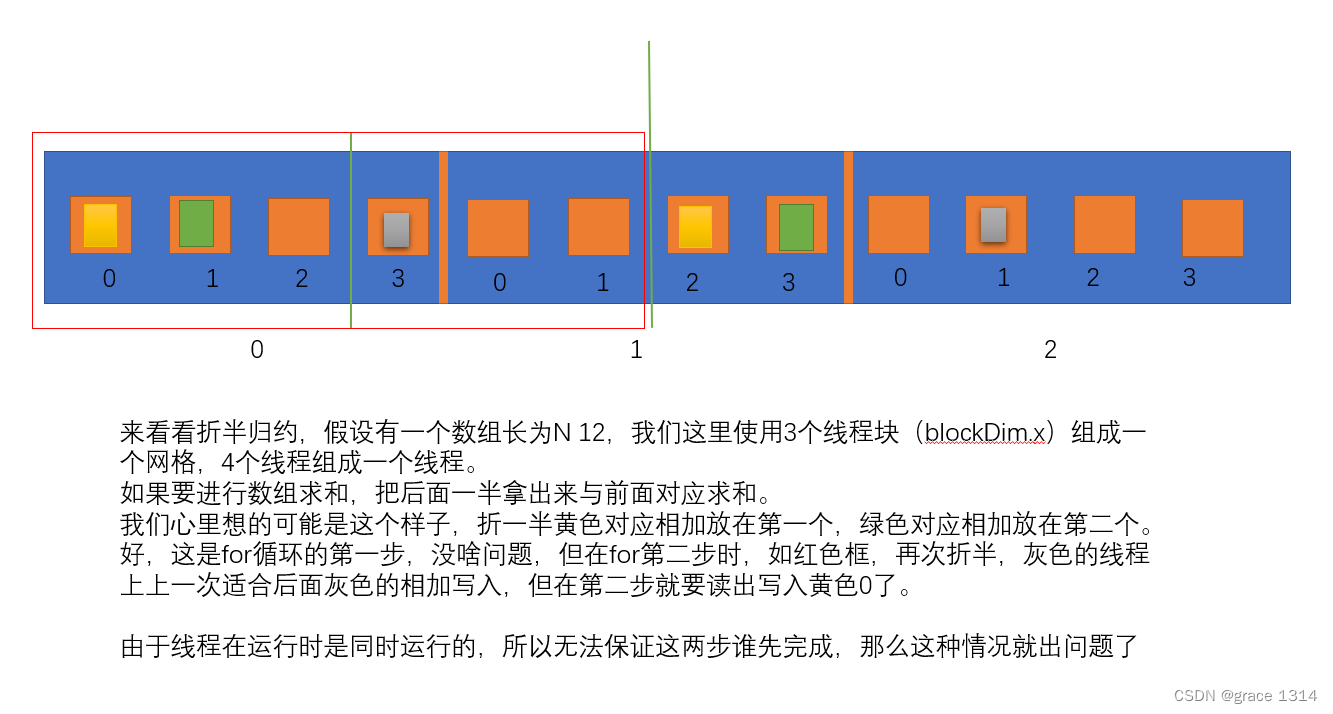
要保证核函数中语句的执行顺序与出现顺序一致,就必须使用某种同步机制。
在CUDA中,提供了一个同步函数__syncthreads。
该函数只能用在核函数中,其最简 单的用法是不带任何参数: __syncthreads();
该函数可保证一个线程块中的所有线程(或者说所有线程束)在执行该语句后面的语句之前都完全执行了该语句前面的语句。然而,该函数只是针对同一个线程块中的线程的,不 同线程块中线程的执行次序依然是不确定的。
既然函数__syncthreads能够同步单个线程块中的线程,那么我们就利用该功能让每 个线程块对其中的数组元素进行归约。
仅使用全局内存的归约核函数代码:
void __global__ reduce_global(real* d_x, real* d_y) {
const int tid = threadIdx.x;
real* x = d_x + blockDim.x * blockIdx.x; //赋值符号的右边是(动态)数组d_x中第blockDimx.x* blockIdx.x个元素的地址。
//real* x = &d_x[blockDim.x * blockIdx.x]; //也可以这样写。
//>>1,移位即就是除2
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
if (tid < offset) {
x[tid] += x[tid + offset];
}
__syncthreads(); //在vs中虽然爆红,未定义标识符,但能跑
//同步语句保证了同一个线程块内的线程按照代码出现的顺序执行指令。
}
if (tid == 0) {
d_y[blockIdx.x] = x[0];
}
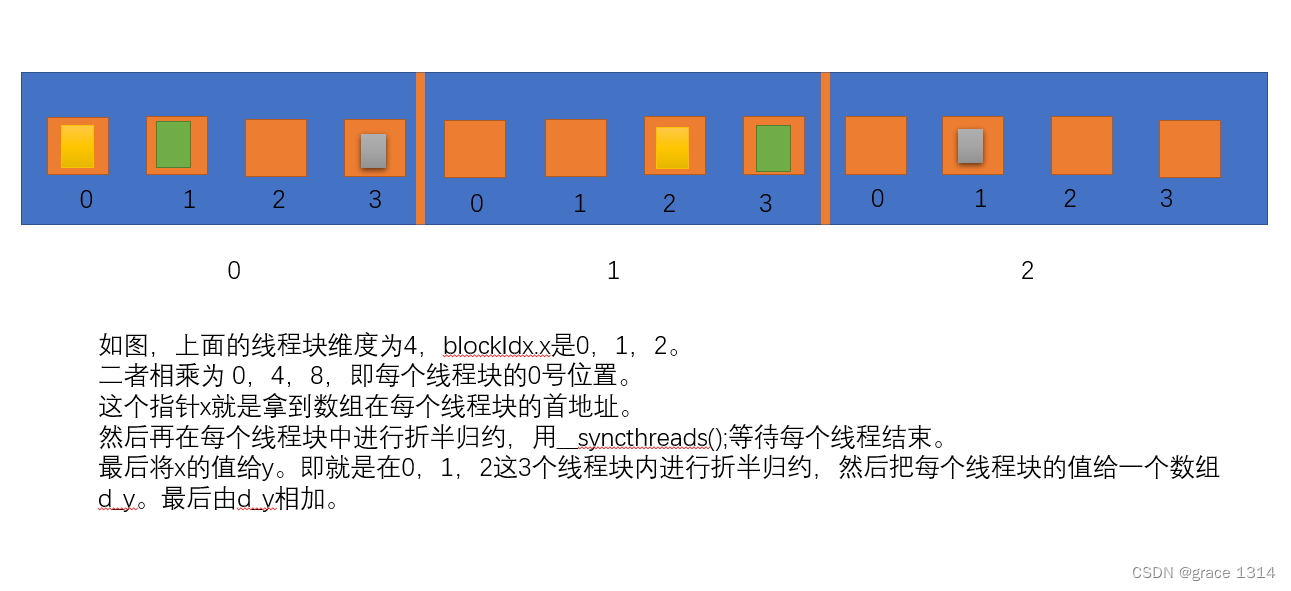
}下面是该核函数中值得注意的地方: •核函数的第4行定义了一个指针x。赋值符号的右边是(动态)数组d_x中 第blockDimx.x* blockIdx.x个元素的地址。所以,第4行也可写成
real*x= &d_x[blockDim.x*blockIdx.x];
这样定义的x在不同的线程块中指向全局内存中不同的地址,使得我们可以在 不同的线程块中对数组d_x中不同的部分进行归约。具体地说,每一个线程块处 理blockDim.x个数据。我们这里不再假设N是2的整数次方,但假设N能够 被blockDim.x整除,而且假设blockDim.x是2的整数次方(作者采用他最常用的 线程块大小128)。
•第6-13行就是在各个线程块内对其中的数据独立地进行归约。第12行的同步语句保 证了同一个线程块内的线程按照代码出现的顺序执行指令。至于两个不同线程块中的 线程,则不一定按照代码出现的顺序执行指令,但这不影响程序的正确性。这是因为, 在该核函数中,每个线程块都处理不同的数据,相互之间没有依赖。总结起来就是说: 一个线程块内的线程需要合作,所以需要同步;两个线程块之间不需要合作,所以不 需要同步。
•核函数的第6行也值得注意。这里我们将blockDim.x/2写成了blockDim.x>>1, 并将offset/=2写成了offset>>=1。这是利用了位操作。以上不同写法在结果 上的等价性要求blockDim.x和offset都是的整数次方。在核函数中,位操作比 对应的整数操作高效。当所涉及的变量在编译期间就知道其可能的取值时,编译器会 自动用位操作取代相应的整数操作,但明显地使用位操作也是不错的做法。
•该核函数仅仅将一个长度为8的数组d_x归约到一个长度为8的数组d_y。 为了计算整个数组元素的和,我们将数组d_y从设备复制到主机,并在主机继续对数 组d_y规约,得到最终的结果。这样做不是很高效,但我们暂时先这样做。
看完了然后我的理解。
使用共享内存:
我们注意到,在前一个版本的核函数中,对全局内存的访问是很频繁的。我们介绍过, 全局内存的访问速度是所有内存中最低的,应该尽量减少对它的使用。所有设备内存中,寄 存器是最高效的,但在需要线程合作的问题中,用仅对单个线程可见的寄存器是不够的。我 们需要使用对整个线程块可见的共享内存。
在核函数中,要将一个变量定义为共享内存变量,就要在定义语句中加上一个限定符__shared__。一般情况下,我们需要的是一个长度等于线程块大小的数组。在当前问题中,我们可以定义如下共享内存数组变量:
__shared__ real s_y[128];如果没有限定符__shared__,该语句将极有可能定义一个长度为128的局部数组。注意: 作者喜欢用前缀 s_给共享内存变量命名,而用前缀d_给全局内存变量命名,虽然这并不 是必须的。需要强调的是,在一个核函数中定义一个共享内存变量,就相当于在每一个线 程块中有了一个该变量的副本。每个副本都不一样,虽然它们共用一个变量名。核函数中 对共享内存变量的操作都是同时作用在所有的副本上的。这种并行的特征在使用共享内存 时需要牢记在心。
来看看使用了共享内存的归约核函数;
void __global__ reduce_shared(real* d_x, real* d_y) {
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid; //这个指引就是元素在整个线程块中的索引。
__shared__ real s_y[128]; //定义了共享内存数组s_y[128]
s_y[tid] = (n < N) ? d_x[n] : 0.0;//将全局内存中的数据复制到共享内存中。
//这里用到了前面说过的共享内存的特征:每个线程块都有一个共享内存变量的副本。
__syncthreads(); //调用函数__syncthreads进行线程块内的同步。
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
if (tid < offset) {
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
//每个线程块都对其中的共享内存变量副本进行操作。
// 在归约过程结束后,每一个线程块中的s_y[0]副本就保存了若干数组元素的和。
if (tid == 0) {
d_y[bid] = s_y[0];
}
}s_y[tid] = (n < N) ? d_x[n] : 0.0; 这一行:共享内存是每个线程块都有的。
该行语句所实现的功能可以展开如下:
– 当bid等于0时,将全局内存中第0到第blockDim.x- 1个数组元素复制给 第0个线程块的共享内存变量副本。
– 当bid等于1时,将全局内存中第blockDim.x到第2 * blockDim.x- 1个数 组元素复制给第1个线程块的共享内存变量副本。
– 因为这里有n < N的判断,所以该函数能够处理N不是线程块大小的整数倍的 情形。此时,最后一个线程块中与条件n >= N对应的共享内存数组元素将被赋 值为0,不对归约(求和)的结果产生影响。
因为共享内存变量的生命周期仅仅在核函数内,所以必须在核函数结束之前将共享内 存中的某些结果保存到全局内存。
这里的判断if(tid==0)可 保证其中的语句在一个线程块中仅被执行一次。
该语句的作用可以展开如下:
–当bid等于0时,将第0个线程块中的s_y[0]副本复制给d_y[0];
–当bid等于1时,将第1个线程块中的s_y[0]副本复制给d_y[1];–如此等等。
总结一下就是在进行计算开始前把全局内存里的数据存到共享内存中。然后线程块从共享内存中读取写入开始计算。
最后计算完后再将共享内存里的结果放入全局内存中。
我自己运行了一下,感觉也没快多少。
使用共享内存减少全局内存的访问一般来说会带来性能的提升,但也不是绝对如此。一 般来说,在核函数中对共享内存访问的次数越多,则由使用共享内存带来的加速效果越明 显。在我们的数组归约问题中,使用共享内存相对于仅使用全局内存还有两个好处:一个 是不再要求全局内存数组的长度N是线程块大小的整数倍,另一个是在规约的过程中不会 改变全局内存数组中的数据(在仅使用全局内存时,数组d_x中的部分元素被改变)。
共享内存的另一个作用是改善全局内存的访问方式(将非合并的全局内存访问转化为合并的。
使用动态共享内存:
如果在定义共享内存变量时不小心把数组长度写错了,就有 可能引起错误或者降低核函数性能。 有一种方法可以减少这种错误发生的概率,那就是使用动态的共享内存。
将前一个版本的静态共享内存改成动态共享内存,只需要做以下两处修改: 1.在调用核函数的执行配置中写下第三个参数:
<<<grid_size,block_size,sizeof(real)*block_size>>>前两个参数分别是网格大小和线程块大小,第三个参数就是核函数中每个线程块需要 定义的动态共享内存的字节数。在我们以前所有的执行配置中,这个参数都没有出现, 其实是用了默认值零。
2.要使用动态共享内存,还需要改变核函数中共享内存变量的声明方式。例如,
extern __shared__reals_y[];两点要求,第一,必须加上限定词extern,第二不能指定数组大小。
使用动态共享内存的核函数和使用静态共享内存的核函 数在执行时间上几乎没有差别。所以,使用动态共享内存不会影响程序性能,但有时可提 高程序的可维护性。
void __global__ reduce_dynamic(real* d_x, real* d_y) {
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid;
extern __shared__ real s_y[];
s_y[tid] = (n < N) ? d_y[n] : 0.0;
__syncthreads();
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
if (tid < offset) {
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
if (tid == 0) {
d_y[bid] = s_y[0];
}
}代码没啥不同。
使用动态共享内存好处就是安全,不用写数组长度。
//这里插一嘴,我是今天才看到这本书里由源码,链接https://github.com/brucefan1983/CUDA-Programming
自己可以试着敲,体会下。我就不摆了。
2.使用共享内存进行转置
如果不利用共享内存的话,在矩阵转置问题中,对全局内存的读和写这两个 操作,总有一个是合并的,另一个是非合并的。在本节,我们将看到,利用共享内存可以 改善全局内存的访问模式,使得对全局内存的读和写都是合并的。
看看代码;
__global__ void tranpose1(const real* A, real* B, const int N) {
__shared__ real S[TILE_DIM][TILE_DIM];
int bx = blockIdx.x * TILE_DIM;
int by = blockIdx.y * TILE_DIM;
// 计算块所代表的位置 行,列
int nx1 = bx + threadIdx.x;
int ny1 = by + threadIdx.y;
//计算线程所代表的位置,行,列
if (nx1 < N && ny1 < N) {
S[threadIdx.y][threadIdx.x] = A[ny1 * N + nx1];
}
__syncthreads();
int nx2 = bx + threadIdx.y;
int ny2 = by + threadIdx.x;
if (nx2 < N && ny2 < N) {
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
//B[nx2 * N + ny2] = S[threadIdx.y][threadIdx.x];
}
}•在矩阵转置的核函数中,最中心的思想是用一个线程块处理一片(tile)矩阵。这里, 一片矩阵的行数和列数都是TILE_DIM=32。为了利用共享内存改善全局内存的访问 方式,我们在第3行定义了一个两维的静态共享内存数组S,其行、列数与一片矩阵 的行、列数一致。
•第11行,将一片矩阵数据从全局内存数组A中读出来,存放在共享内存数组中。这里 对全局内存的访问是合并的(不考虑内存对齐的因素),因为相邻的threadIdx.x与 全局内存中相邻的数据对应。
第13行,在将共享内存中的数据写入全局内存数组B之前,进行一次线程块内的同步操作。一般来说,在利用共享内存中的数据之前,都要进行线程块内的同步操作,以 确保共享内存数组中的所有元素都已经更新完毕。
这样改写后的核函数与第7章的核函数transpose1相比,唯一的区别就是将数据从 全局内存转移到了共享内存,然后又原封不动地转移到了全局内存,并没有改变对 全局内存的访问方式。要改变对全局内存的访问方式很简单:只要调换这几行代码中 的threadIdx.x 和 threadIdx.y 即可。调换之后,就得到了Listing8.5中的核函数, 其中对全局内存数组B的访问也是合并的,因为相邻的threadIdx.x与全局内存数 组B中相邻的数据对应。
好了,估计你们看上面代码也晕了,现在我来大概解释下。
const real *A, real *B, const int N首先这3个参数,A,B,我们是吧矩阵拉开当成数组存了。N是矩阵的维度(因为方阵所以只需要一个)。
A和B是设备变量,device,放在全局内存中,如果直接再全局内存中进行转置计算,要么读不是合并的,要么写不是合并的,这在之前说到过。就是你可以顺序的读A中的每个变量,但是当你写入B中的时候得按照转置的位置来写入,这个不是顺序的,所以后面操作不能合并。另外一种情况也相同。
然后看看通过共享内存怎么做的,
__shared__ real S[TILE_DIM][TILE_DIM];申请共享内存,大小就是自己定义的32X32大小,一大块。
int bx = blockIdx.x * TILE_DIM;
int by = blockIdx.y * TILE_DIM;这个是线程块索引位置(行,列)。
int nx1 = bx + threadIdx.x;
int ny1 = by + threadIdx.y;这个是线程块中线程的位置(行,列)。
if (nx1 < N && ny1 < N)
{
S[threadIdx.y][threadIdx.x] = A[ny1 * N + nx1];
}
__syncthreads();然后这步将矩阵A中的元素读出写入到S中。这里读写时连续的所以访问时合并的。然后等待A写完。
int nx2 = bx + threadIdx.y;
int ny2 = by + threadIdx.x;
if (nx2 < N && ny2 < N)
{
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
}这步是找到B的索引,首先想想前两个啥意思。
前面两行,是计算输出矩阵的x索引和y索引
后面共享内存中的数据是以列为单位加载,然后在输出矩阵以行为单位写入,这个方式可以确保数据的局部性,减少全局内存的访问次数,从而提高性能。
emmm,总的来说还是有点浑,不太明白。有大佬,可以好好解释这段,最好是画图把。
3.避免共享内存的bank冲突
关于共享内存,有一个内存bank的概念值得注意。为了获得高的内存带宽,共享内 存在物理上被分为32个(刚好等于一个线程束中的线程数目,即内建变量warpSize的值) 同样宽度的、能被同时访问的内存bank。我们可以将32个bank从0到31编号。在每一 个bank 中,又可以对其中的内存地址从0开始编号。为方便起见,我们将所有bank中编 号为0的内存称为第一层内存;将所有bank中编号为1的内存称为第二层内存。在开普勒 架构中,每个bank的宽度为8字节;在所有其他架构中,每个bank的宽度为4字节。
对于bank宽度为4字节的架构,共享内存数组是按如下方式线性地映射到内存bank的: 共享内存数组中连续的128字节的内容分摊到32个bank的某一层中,每个bank负责4字 节的内容。例如,对一个长度为128的单精度浮点数变量的共享内存数组来说,第0-31个 数组元素依次对应到32个bank的第一层;第32-63个数组元素依次对应到32个bank的 第二层;第64-95个数组元素依次对应到32个bank的第三层;第96-127个数组元素依次 对应到32个bank的第四层。也就是说,每个bank分摊4个在地址上相差128字节的数据,
只要同一线程束内的多个线程不同时访问同一个bank中不同层的数据,该线程束对 共享内存的访问就只需要一次内存事务(memory transaction)。当同一线程束内的多个 线程试图访问同一个bank 中不同层的数据时,就会发生bank冲突。在一个线程束内对 同一个bank 中的 层数据同时访问将导致次内存事务,称为发生了路bank冲突。 最坏的情况是线程束内的32个线程同时访问同一个bank中32个不同层的地址,这将导 致32路bank冲突。这种很大的bank冲突是要尽量避免的。
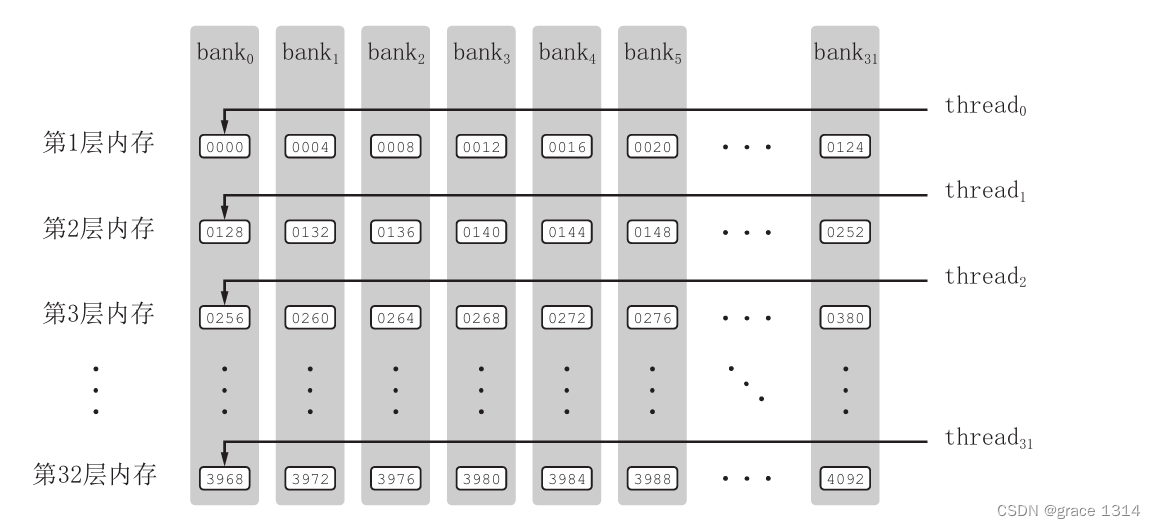
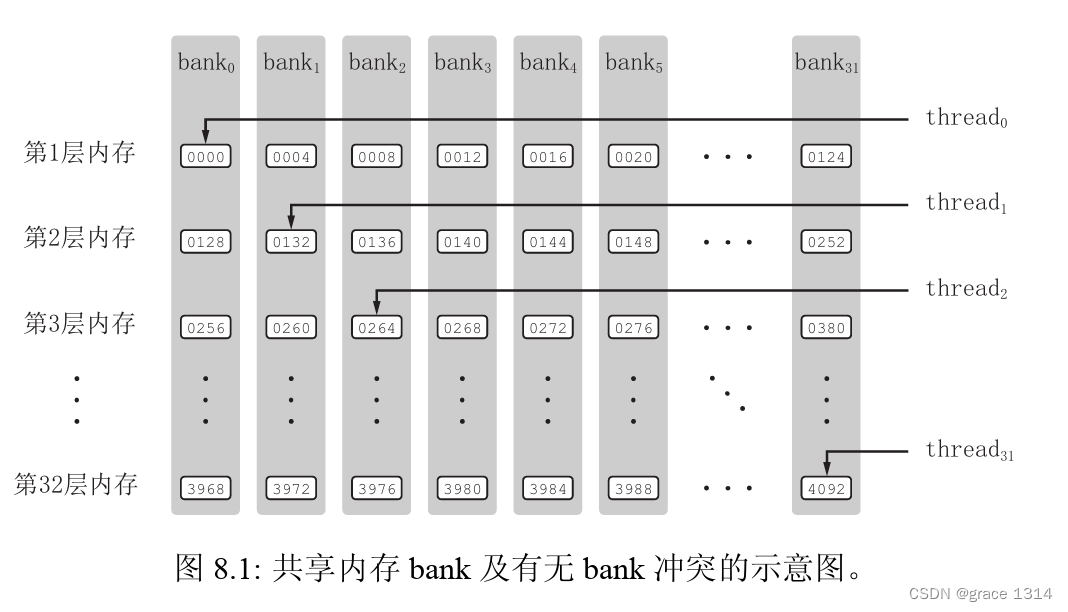
在前一节的核函数transpose1中,定义了一个长度为 1024 的单精度浮点型变量的共享内存数组。我们只讨论非开普勒架构的情形,其中每个共享内存bank的宽度 为4字节。于是,每一层的32个bank将对应32个连续的数组元素;每个bank有32层数据。从前一节核函数transpose1的第19行可以看出,同一个线程束中的32个线程(连续的32个threadIdx.x 值)将对应共享内存数组S中跨度为32的数据。也就是说,这32个线程将刚好访问同一个bank中的32个数据。这将导致32路bank冲突,参见图8.1(上)。 相比之下,第11行对共享内存的访问不导致bank冲突。
通常可以用改变共享内存数组大小的方式来消除或减轻共享内存的bank冲突。例如, 将上述核函数中的共享内存定义修改为如下:
__shared__ real S[TILE_DIM][TILE_DIM + 1];
就可以完全消除第19行读取共享内存时的bank冲突。这是因为,这样改变共享内存数组 的大小之后,同一个线程束中的32个线程(连续的32个threadIdx.x值)将对应共享内存 数组S中跨度为33的数据。如果第一个线程访问第一个bank的第一层,第二个线程则会 访问第二个bank的第二层(而不是第一个bank的第二层);如此等等。于是,这32个线 程将分别访问32个不同bank中的数据,所以没有bank冲突。
在使用单精度浮点数时,使用共享内存 并消除bank冲突的核函数最为高效,但在使用双精度浮点数时,仅使用全局内存(不使用 共享内存)且保证全局内存的合并写入的(故导致全局内存的非合并读取,但此时会利用 只读缓存加速)核函数最为高效。这说明,使用共享内存来改善全局内存的访问方式并不 一定能够提高核函数的性能。所以,在优化CUDA程序时,一般需要对不同的优化方案进 行测试与比较。















 5170
5170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









