







SENet
SELayer
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
SE-ResNet模型
class SEBottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, reduction=16):
super(SEBottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
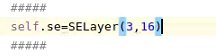
self.se = SELayer(planes * 4, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.se(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
级联细化网络
级联细化网络(CRN)【1】是一种基于语义布局的逼真图像合成方法,与最近和当代的工作不同,该网络不依赖对抗性训练,而是通过一个结构合适的单一前馈网络来合成,并用直接回归目标进行端到端训练,且可以无缝地扩展到高分辨率。


级联网络
if self.layout_noise_dim > 0:
N, C, H, W = layout.size()
#batch_size 128 128 128
noise_shape = (N, self.layout_noise_dim, H, W)
layout_noise = torch.randn(noise_shape, dtype=layout.dtype,
device=layout.device)
layout = torch.cat([layout, layout_noise], dim=1)
#横过来叠加
img = self.refinement_net(layout)
refinement_kwargs = {
'dims': (gconv_dim + layout_noise_dim,) + refinement_dims, #合成一个元组
'normalization': normalization,
'activation': activation,
}
self.refinement_net = RefinementNetwork(**refinement_kwargs)
refinement_dims=(1024, 512, 256, 128, 64),
normalization='batch',
activation='leakyrelu-0.2'
gconv_dim = 128
layout_noise_dim = 32
crn.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from sg2im.layers import get_normalization_2d
from sg2im.layers import get_activation
from sg2im.utils import timeit, lineno, get_gpu_memory
"""
Cascaded refinement network architecture, as described in:
Qifeng Chen and Vladlen Koltun,
"Photographic Image Synthesis with Cascaded Refinement Networks",
ICCV 2017
"""
级联模块
class RefinementModule(nn.Module):
def __init__(self, layout_dim, input_dim, output_dim,
normalization='instance', activation='leakyrelu'):
super(RefinementModule, self).__init__()
layers = []
layers.append(nn.Conv2d(layout_dim + input_dim, output_dim,
kernel_size=3, padding=1))
layers.append(get_normalization_2d(output_dim, normalization))
layers.append(get_activation(activation))
layers.append(nn.Conv2d(output_dim, output_dim, kernel_size=3, padding=1))
layers.append(get_normalization_2d(output_dim, normalization))
layers.append(get_activation(activation))
layers = [layer for layer in layers if layer is not None]
for layer in layers:
if isinstance(layer, nn.Conv2d):
nn.init.kaiming_normal_(layer.weight)
self.net = nn.Sequential(*layers)
def forward(self, layout, feats):
_, _, HH, WW = layout.size()
_, _, H, W = feats.size()
assert HH >= H
if HH > H:
factor = round(HH // H)
assert HH % factor == 0
assert WW % factor == 0 and WW // factor == W
layout = F.avg_pool2d(layout, kernel_size=factor, stride=factor)
net_input = torch.cat([layout, feats], dim=1)
out = self.net(net_input)
return out
F.avg_pool2d
output=(input-k)/s+1
k=s=HH/H
o=i/s=H
级联网络
class RefinementNetwork(nn.Module):
def __init__(self, dims, normalization='instance', activation='leakyrelu'):
super(RefinementNetwork, self).__init__()
layout_dim = dims[0]
self.refinement_modules = nn.ModuleList()
for i in range(1, len(dims)):
input_dim = 1 if i == 1 else dims[i - 1]
output_dim = dims[i]
mod = RefinementModule(layout_dim, input_dim, output_dim,
normalization=normalization, activation=activation)
self.refinement_modules.append(mod)
output_conv_layers = [
nn.Conv2d(dims[-1], dims[-1], kernel_size=3, padding=1),
get_activation(activation),
nn.Conv2d(dims[-1], 3, kernel_size=1, padding=0)
]
nn.init.kaiming_normal_(output_conv_layers[0].weight)
nn.init.kaiming_normal_(output_conv_layers[2].weight)
self.output_conv = nn.Sequential(*output_conv_layers)
def forward(self, layout):
"""
Output will have same size as layout
"""
# H, W = self.output_size
N, _, H, W = layout.size()
self.layout = layout
# Figure out size of input
input_H, input_W = H, W
for _ in range(len(self.refinement_modules)):
input_H //= 2
input_W //= 2
assert input_H != 0
assert input_W != 0
feats = torch.zeros(N, 1, input_H, input_W).to(layout)
for mod in self.refinement_modules:
feats = F.upsample(feats, scale_factor=2, mode='nearest')
feats = mod(layout, feats)
out = self.output_conv(feats)
return out
构建级联模块
dims=(160,1024,512,256,128,64)
layout_dim = dims[0]
self.refinement_modules = nn.ModuleList()
for i in range(1, len(dims)):
input_dim = 1 if i == 1 else dims[i - 1]
output_dim = dims[i]
mod = RefinementModule(layout_dim, input_dim, output_dim,
normalization=normalization, activation=activation)
self.refinement_modules.append(mod)
M0 1->1024
M1 1024->512
M2 512->256
M3 256->128
M4 128->64
# Figure out size of input
input_H, input_W = H, W
for _ in range(len(self.refinement_modules)): #5
input_H //= 2
input_W //= 2
input_H = 4
feats = torch.zeros(N, 1, input_H, input_W).to(layout)
for mod in self.refinement_modules:
feats = F.upsample(feats, scale_factor=2, mode='nearest')
feats = mod(layout, feats)
out = self.output_conv(feats)


添加SE

不能在输出结果后面再加SE了,SE要先压缩再激励,总共就3维,压无可压了

【1】.Q. Chen and V. Koltun. Photographic image synthesis with cascaded refinement networks. In ICCV, 2017. 2, 3, 4, 7















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









